谷歌發布深度學習庫TensorFlow Fold,支持動態計算圖
在大部分的機器學習過程中,用于訓練 (training) 和推理 (inference) 的數據都需要進行數據的預處理,通過預處理將不同的輸入數據(例如圖像)規整至相同尺寸并進行批(batch)存儲。這一步使高性能的深度學習庫,例如 TensorFlow,可以并行的處理批存儲中的所有輸入,且以相同的計算圖(computation graph)進行處理。批處理(Batching)利用現代 GPU 和多核 CPU 的單指令流多數據流(SIMD)性能來加速運算執行。但是,當輸入數據的尺寸和結構變化時會產生諸多問題,例如在自然語言理解中的解析樹(parse tree)、源代碼中的抽象語法樹(abstract syntax tree)、網頁的文檔樹(DOM tree)等。在這些情況下,不同的輸入數據需要不同的計算圖,通常這些計算圖不能夠批存儲在一起,導致處理器、存儲器以及緩存利用率低。
今天我們發布 TensorFlow Fold 來解決這些困難。TensorFlow Fold 使得處理不同數據尺寸和結構的深度學習模型更容易實現。不僅如此,TensorFlow Fold 將批處理的優勢賦予這些模型,使得這些模型在 CPU 上的運行速度有超過 10 倍的提升,在 GPU 上的運行有超過 100 倍的提升(相比于其他實現方式)。這一提升來源于動態批存儲(dynamic batching)技術,在我們的論文中有詳細介紹(Deep Learning with Dynamic Computation Graphs)。
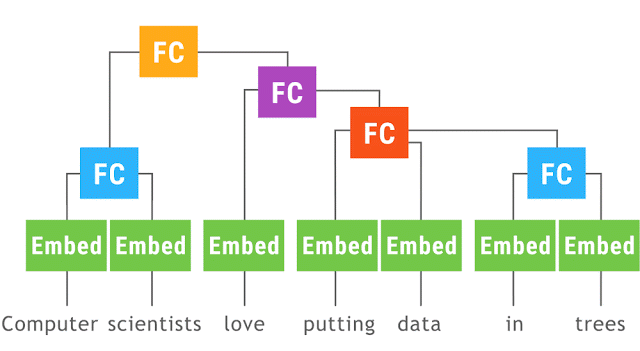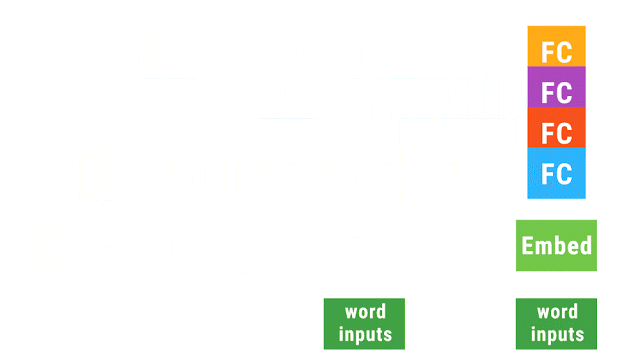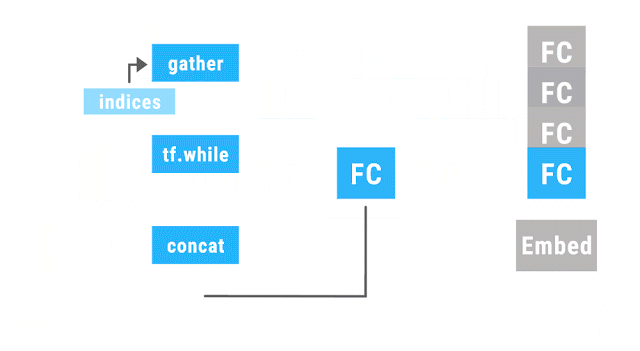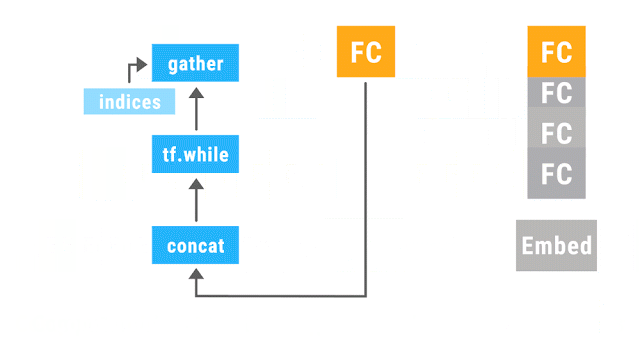
以上動圖演示了動態批處理運行的遞歸神經網絡。帶有同樣的顏色的運算聚成一批,這使得 TensorFlow 能夠更快的運行它們。Embed 運算將單詞轉換為向量表征。完全連接(fully connected,FC)運算結合詞向量,從而形成段落向量表征。網絡的輸出是一個完整語句的向量表征。盡管上圖只演示了一個語句解析樹,但在多種任意形狀與大小的解析樹上,這個網絡同樣也能運行并實現批處理運算。
TensorFlow Fold 庫首先會為每個輸入建立一個獨立的計算圖。
因為單獨的輸入可能有不同的大小和結構,計算圖也可能是這樣。動態批處理自動結合這些圖,從而獲取在輸入內以及整個輸入進行批處理機會的優勢,并且插入額外的指令在批處理操作之間移動數據。(查看技術細節請參考論文)
想要了解更多,也可以查看我們的 github 網址:https://github.com/tensorflow/fold。我們希望 TensorFlow Fold 能夠幫助研究人員與從業者在 TensorFlow 中部署動態計算的神經網絡。
論文:DEEP LEARNING WITH DYNAMIC COMPUTATION GRAPHS

摘要:在包括自然語言處理(解析樹)與化學信息學(分子圖)在內的多個領域中,在圖結構上進行計算的神經網絡是解決問題的天然方式。然而,因為每個輸入的計算圖有不同的形狀與大小,所以網絡通常不能直接進行批訓練或推斷。它們也難以部署到流行的深度學習庫中,因為這些庫是基于靜態數據流圖的。我們引入了一種稱之為動態批處理(Dynamic Batching) 的技術,它不僅能批處理不同輸入圖(形狀也不類似)之間的運算,也能批處理單個輸入圖內的不同節點。該技術使得我們能夠創造靜態圖、使用流行的庫、模仿任意形狀與大小的動態計算圖。我們進一步展現了組成區塊的高層次庫,從而簡化了創造動態圖模型的過程。使用這一庫,我們論證了文獻中多種模型的簡潔且明智的批處理并行實現。
原文:https://research.googleblog.com/2017/02/announcing-tensorflow-fold-deep.html
【本文是51CTO專欄機構機器之心的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】