動態計算圖和GPU支持操作
作者:小sen
在深度學習中使用 PyTorch 的主要原因之一,是我們可以自動獲得定義的函數的梯度/導數。當我們操作我們的輸入時,會自動創建一個計算圖。該圖顯示了如何從輸入到輸出的動態計算過程。
動態計算圖
在深度學習中使用 PyTorch 的主要原因之一,是我們可以自動獲得定義的函數的梯度/導數。
當我們操作我們的輸入時,會自動創建一個計算圖。該圖顯示了如何從輸入到輸出的動態計算過程。
為了熟悉計算圖的概念,下面將為以下函數創建一個:
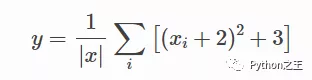
這里的 是我們的參數,我們想要優化(最大化或最小化)輸出 . 為此,我們想要獲得梯度.
在下面的代碼中,我將使用[1,2,3]作輸入。
- # 只有浮動張量有梯度
- x = torch.arange(1,4, dtype=torch.float32, requires_grad=True)
- print("X", x)
- # X tensor([1., 2., 3.], requires_grad=True)
現在讓我來一步一步地構建計算圖,了解每個操作是到底是如何添加到計算圖中的。
- a = x + 2
- b = a ** 2
- c = b + 3
- y = c.mean()
- print("Y", y)
- # Y tensor(19.6667, grad_fn=<MeanBackward0>)
使用上面的語句,我們創建了一個類似于下圖的計算圖(通過tensorboard )查看:
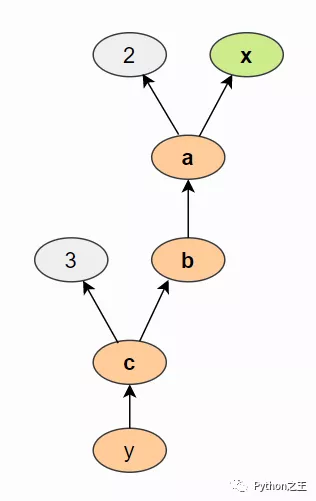
我們計算 a 基于輸入x 和常數2, b是 a平方等等操作。計算圖通常以相反的方向可視化(箭頭從結果指向輸入)。
我們可以通過backward()在最后一個輸出上調用函數來對計算圖執行反向傳播,這樣可以,計算了每個具有屬性的張量的梯度requires_grad=True:
- y.backward()
最后打印x.grad就可以查看對應梯度。

GPU支持操作
在Pytorch中GPU 可以并行執行數以千計的小運算,因此非常適合在神經網絡中執行大型矩陣運算。
「CPU 與 GPU的區別」
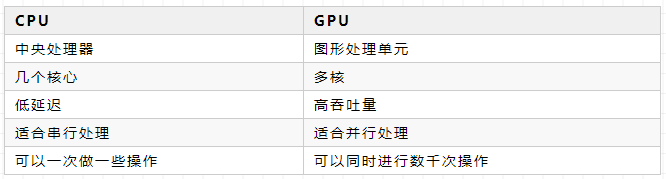
PyTorch 使用GPU,需要搭建NVIDIA 的CUDA和cuDNN。
下面代碼,檢查是否有可用的 GPU:
- gpu_avail = torch.cuda.is_available()
- print("Is the GPU available? %s" % str(gpu_avail))

現在創建一個張量并將其推送到GPU設備:
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- print("Device", device)
- x = x.to(device)
- print("X", x)
- # Device cuda
- # X tensor([1., 1., 1.], device='cuda:0')
cuda 旁邊的零表示這是計算機上的第0個 GPU 設備。因此,PyTorch 還支持多 GPU 系統,
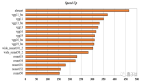
下面將CPU 上的大型矩陣乘法的運行時間與 GPU 上的運算進行比較:
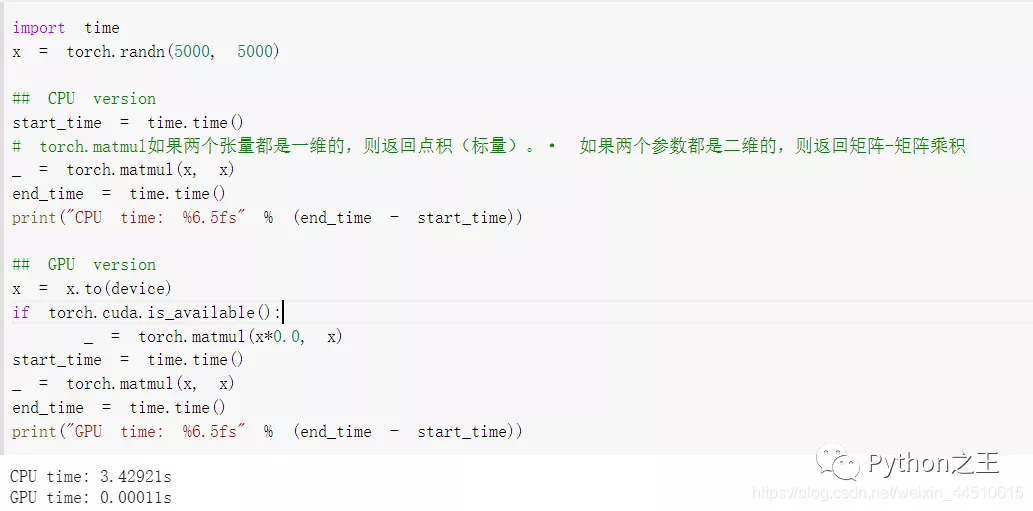
根據系統中的配置而定,GPU加速提高模型的訓練速度。
責任編輯:姜華
來源:
Python之王