深入淺出搜索架構(gòu)引擎、方案與細節(jié)(上)
一、緣起
《100億數(shù)據(jù)1萬屬性數(shù)據(jù)架構(gòu)設(shè)計》文章發(fā)布后,不少朋友對58同城自研搜索引擎E-search比較感興趣,故專門撰文體系化的聊聊搜索引擎,從宏觀到細節(jié),希望把邏輯關(guān)系講清楚,內(nèi)容比較多,分上下兩期。
主要內(nèi)容如下,本篇(上)會重點介紹前三章:
(1)全網(wǎng)搜索引擎架構(gòu)與流程
(2)站內(nèi)搜索引擎架構(gòu)與流程
(3)搜索原理、流程與核心數(shù)據(jù)結(jié)構(gòu)
(4)流量數(shù)據(jù)量由小到大,搜索方案與架構(gòu)變遷
(5)數(shù)據(jù)量、并發(fā)量、策略擴展性及架構(gòu)方案
(6)實時搜索引擎核心技術(shù)
可能99%的同學不實施搜索引擎,但本文一定對你有幫助。

二、全網(wǎng)搜索引擎架構(gòu)與流程
全網(wǎng)搜索的宏觀架構(gòu)長啥樣?
全網(wǎng)搜索的宏觀流程是怎么樣的?
搜索引擎的宏觀架構(gòu)")
全網(wǎng)搜索引擎的宏觀架構(gòu)如上圖,核心子系統(tǒng)主要分為三部分(粉色部分):
(1)spider爬蟲系統(tǒng)
(2)search&index建立索引與查詢索引系統(tǒng),這個系統(tǒng)又主要分為兩部分:
- 一部分用于生成索引數(shù)據(jù)build_index
- 一部分用于查詢索引數(shù)據(jù)search_index
(3)rank打分排序系統(tǒng)
核心數(shù)據(jù)主要分為兩部分(紫色部分):
- web網(wǎng)頁庫
- index索引數(shù)據(jù)
全網(wǎng)搜索引擎的業(yè)務(wù)特點決定了,這是一個“寫入”和“檢索”完全分離的系統(tǒng):
【寫入】
系統(tǒng)組成:由spider與search&index兩個系統(tǒng)完成
輸入:站長們生成的互聯(lián)網(wǎng)網(wǎng)頁
輸出:正排倒排索引數(shù)據(jù)
流程:如架構(gòu)圖中的1,2,3,4
(1)spider把互聯(lián)網(wǎng)網(wǎng)頁抓過來
(2)spider把互聯(lián)網(wǎng)網(wǎng)頁存儲到網(wǎng)頁庫中(這個對存儲的要求很高,要存儲幾乎整個“萬維網(wǎng)”的鏡像)
(3)build_index從網(wǎng)頁庫中讀取數(shù)據(jù),完成分詞
(4)build_index生成倒排索引
【檢索】
系統(tǒng)組成:由search&index與rank兩個系統(tǒng)完成
輸入:用戶的搜索詞
輸出:排好序的***頁檢索結(jié)果
流程:如架構(gòu)圖中的a,b,c,d
(a)search_index獲得用戶的搜索詞,完成分詞
(b)search_index查詢倒排索引,獲得“字符匹配”網(wǎng)頁,這是初篩的結(jié)果
(c)rank對初篩的結(jié)果進行打分排序
(d)rank對排序后的***頁結(jié)果返回
三、站內(nèi)搜索引擎架構(gòu)與流程
做全網(wǎng)搜索的公司畢竟是少數(shù),絕大部分公司要實現(xiàn)的其實只是一個站內(nèi)搜索,站內(nèi)搜索引擎的宏觀架構(gòu)和全網(wǎng)搜索引擎的宏觀架構(gòu)有什么異同?
以58同城100億帖子的搜索為例,站內(nèi)搜索系統(tǒng)架構(gòu)長啥樣?站內(nèi)搜索流程是怎么樣的?
搜索引擎的宏觀架構(gòu)")
站內(nèi)搜索引擎的宏觀架構(gòu)如上圖,與全網(wǎng)搜索引擎的宏觀架構(gòu)相比,差異只有寫入的地方:
(1)全網(wǎng)搜索需要spider要被動去抓取數(shù)據(jù)
(2)站內(nèi)搜索是內(nèi)部系統(tǒng)生成的數(shù)據(jù),例如“發(fā)布系統(tǒng)”會將生成的帖子主動推給build_data系統(tǒng)
看似“很小”的差異,架構(gòu)實現(xiàn)上難度卻差很多:全網(wǎng)搜索如何“實時”發(fā)現(xiàn)“全量”的網(wǎng)頁是非常困難的,而站內(nèi)搜索容易實時得到全部數(shù)據(jù)。
對于spider、search&index、rank三個系統(tǒng):
(1)spider和search&index是相對工程的系統(tǒng)
(2)rank是和業(yè)務(wù)、策略緊密、算法相關(guān)的系統(tǒng),搜索體驗的差異主要在此,而業(yè)務(wù)、策略的優(yōu)化是需要時間積累的,這里的啟示是:
a)Google的體驗比Baidu好,根本在于前者rank牛逼
b)國內(nèi)互聯(lián)網(wǎng)公司(例如360)短時間要搞一個體驗超越Baidu的搜索引擎,是很難的,真心需要時間的積累
四、搜索原理與核心數(shù)據(jù)結(jié)構(gòu)
- 什么是正排索引?
- 什么是倒排索引?
- 搜索的過程是什么樣的?
- 會用到哪些算法與數(shù)據(jù)結(jié)構(gòu)?
前面的內(nèi)容太宏觀,為了照顧大部分沒有做過搜索引擎的同學,數(shù)據(jù)結(jié)構(gòu)與算法部分從正排索引、倒排索引一點點開始。
提問:什么是正排索引(forward index)?
回答:由key查詢實體的過程,是正排索引。
用戶表:t_user(uid, name, passwd, age, sex),由uid查詢整行的過程,就是正排索引查詢。
網(wǎng)頁庫:t_web_page(url, page_content),由url查詢整個網(wǎng)頁的過程,也是正排索引查詢。
網(wǎng)頁內(nèi)容分詞后,page_content會對應(yīng)一個分詞后的集合list
簡易的,正排索引可以理解為Map
提問:什么是倒排索引(inverted index)?
回答:由item查詢key的過程,是倒排索引。
對于網(wǎng)頁搜索,倒排索引可以理解為Map
舉個例子,假設(shè)有3個網(wǎng)頁:
url1 -> “我愛北京”
url2 -> “我愛到家”
url3 -> “到家美好”
這是一個正排索引Map
分詞之后:
url1 -> {我,愛,北京}
url2 -> {我,愛,到家}
url3 -> {到家,美好}
這是一個分詞后的正排索引Map
分詞后倒排索引:
我 -> {url1, url2}
愛 -> {url1, url2}
北京 -> {url1}
到家 -> {url2, url3}
美好 -> {url3}
由檢索詞item快速找到包含這個查詢詞的網(wǎng)頁Map
正排索引和倒排索引是spider和build_index系統(tǒng)提前建立好的數(shù)據(jù)結(jié)構(gòu),為什么要使用這兩種數(shù)據(jù)結(jié)構(gòu),是因為它能夠快速的實現(xiàn)“用戶網(wǎng)頁檢索”需求(業(yè)務(wù)需求決定架構(gòu)實現(xiàn))。
提問:搜索的過程是什么樣的?
假設(shè)搜索詞是“我愛”,用戶會得到什么網(wǎng)頁呢?
(1)分詞,“我愛”會分詞為{我,愛},時間復雜度為O(1)
(2)每個分詞后的item,從倒排索引查詢包含這個item的網(wǎng)頁list
我 -> {url1, url2}
愛 -> {url1, url2}
(3)求list
看似到這里就結(jié)束了,其實不然,分詞和倒排查詢時間復雜度都是O(1),整個搜索的時間復雜度取決于“求list
字符型的url不利于存儲與計算,一般來說每個url會有一個數(shù)值型的url_id來標識,后文為了方便描述,list
提問:list1和list2,求交集怎么求?
方案一:for * for,土辦法,時間復雜度O(n*n)
每個搜索詞***的網(wǎng)頁是很多的,O(n*n)的復雜度是明顯不能接受的。倒排索引是在創(chuàng)建之初可以進行排序預(yù)處理,問題轉(zhuǎn)化成兩個有序的list求交集,就方便多了。
方案二:有序list求交集,拉鏈法

有序集合1{1,3,5,7,8,9}
有序集合2{2,3,4,5,6,7}
兩個指針指向首元素,比較元素的大小:
(1)如果相同,放入結(jié)果集,隨意移動一個指針
(2)否則,移動值較小的一個指針,直到隊尾
這種方法的好處是:
(1)集合中的元素最多被比較一次,時間復雜度為O(n)
(2)多個有序集合可以同時進行,這適用于多個分詞的item求url_id交集
這個方法就像一條拉鏈的兩邊齒輪,一一比對就像拉鏈,故稱為拉鏈法
方案三:分桶并行優(yōu)化
數(shù)據(jù)量大時,url_id分桶水平切分+并行運算是一種常見的優(yōu)化方法,如果能將list1
舉例:
- 有序集合1{1,3,5,7,8,9, 10,30,50,70,80,90}
- 有序集合2{2,3,4,5,6,7, 20,30,40,50,60,70}
求交集,先進行分桶拆分:
- 桶1的范圍為[1, 9]
- 桶2的范圍為[10, 100]
- 桶3的范圍為[101, max_int]
于是:
集合1就拆分成
- 集合a{1,3,5,7,8,9}
- 集合b{10,30,50,70,80,90}
- 集合c{}
- 集合2就拆分成
- 集合d{2,3,4,5,6,7}
- 集合e{20,30,40,50,60,70}
- 集合e{}
每個桶內(nèi)的數(shù)據(jù)量大大降低了,并且每個桶內(nèi)沒有重復元素,可以利用多線程并行計算:
- 桶1內(nèi)的集合a和集合d的交集是x{3,5,7}
- 桶2內(nèi)的集合b和集合e的交集是y{30, 50, 70}
- 桶3內(nèi)的集合c和集合d的交集是z{}
最終,集合1和集合2的交集,是x與y與z的并集,即集合{3,5,7,30,50,70}
方案四:bitmap再次優(yōu)化
數(shù)據(jù)進行了水平分桶拆分之后,每個桶內(nèi)的數(shù)據(jù)一定處于一個范圍之內(nèi),如果集合符合這個特點,就可以使用bitmap來表示集合:
化")
如上圖,假設(shè)set1{1,3,5,7,8,9}和set2{2,3,4,5,6,7}的所有元素都在桶值[1, 16]的范圍之內(nèi),可以用16個bit來描述這兩個集合,原集合中的元素x,在這個16bitmap中的第x個bit為1,此時兩個bitmap求交集,只需要將兩個bitmap進行“與”操作,結(jié)果集bitmap的3,5,7位是1,表明原集合的交集為{3,5,7}
水平分桶,bitmap優(yōu)化之后,能極大提高求交集的效率,但時間復雜度仍舊是O(n)
bitmap需要大量連續(xù)空間,占用內(nèi)存較大
方案五:跳表skiplist
有序鏈表集合求交集,跳表是最常用的數(shù)據(jù)結(jié)構(gòu),它可以將有序集合求交集的復雜度由O(n)降至O(log(n))

- 集合1{1,2,3,4,20,21,22,23,50,60,70}
- 集合2{50,70}
要求交集,如果用拉鏈法,會發(fā)現(xiàn)1,2,3,4,20,21,22,23都要被無效遍歷一次,每個元素都要被比對,時間復雜度為O(n),能不能每次比對“跳過一些元素”呢?
跳表就出現(xiàn)了:
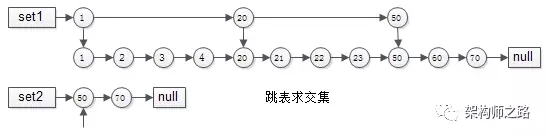
- 集合1{1,2,3,4,20,21,22,23,50,60,70}建立跳表時,一級只有{1,20,50}三個元素,二級與普通鏈表相同
- 集合2{50,70}由于元素較少,只建立了一級普通鏈表
如此這般,在實施“拉鏈”求交集的過程中,set1的指針能夠由1跳到20再跳到50,中間能夠跳過很多元素,無需進行一一比對,跳表求交集的時間復雜度近似O(log(n)),這是搜索引擎中常見的算法。
五、總結(jié)
文字很多,有宏觀,有細節(jié),對于大部分不是專門研究搜索引擎的同學,記住以下幾點即可:
(1)全網(wǎng)搜索引擎系統(tǒng)由spider, search&index, rank三個子系統(tǒng)構(gòu)成
(2)站內(nèi)搜索引擎與全網(wǎng)搜索引擎的差異在于,少了一個spider子系統(tǒng)
(3)spider和search&index系統(tǒng)是兩個工程系統(tǒng),rank系統(tǒng)的優(yōu)化卻需要長時間的調(diào)優(yōu)和積累
(4)正排索引(forward index)是由網(wǎng)頁url_id快速找到分詞后網(wǎng)頁內(nèi)容list
(5)倒排索引(inverted index)是由分詞item快速尋找包含這個分詞的網(wǎng)頁list
(6)用戶檢索的過程,是先分詞,再找到每個item對應(yīng)的list
(7)有序集合求交集的方法有
- 二重for循環(huán)法,時間復雜度O(n*n)
- 拉鏈法,時間復雜度O(n)
- 水平分桶,多線程并行
- bitmap,大大提高運算并行度,時間復雜度O(n)
- 跳表,時間復雜度為O(log(n))
六、下章預(yù)告
a)流量數(shù)據(jù)量由小到大,搜索方案與架構(gòu)變遷-> 這個應(yīng)該很有用,很多處于不同發(fā)展階段的互聯(lián)網(wǎng)公司都在做搜索系統(tǒng),58同城經(jīng)歷過流量從0到10億,數(shù)據(jù)量從0到100億,搜索架構(gòu)也不斷演化著
b)數(shù)據(jù)量、并發(fā)量、策略擴展性及架構(gòu)方案
c)實時搜索引擎核心技術(shù) -> 站長發(fā)布1個新網(wǎng)頁,Google如何做到15分鐘后檢索出來
【本文為51CTO專欄作者“58沈劍”原創(chuàng)稿件,轉(zhuǎn)載請聯(lián)系原作者】