python數據分析筆記——數據加載與整理
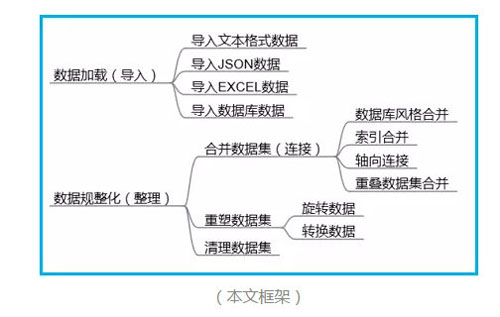
數據加載
導入文本數據
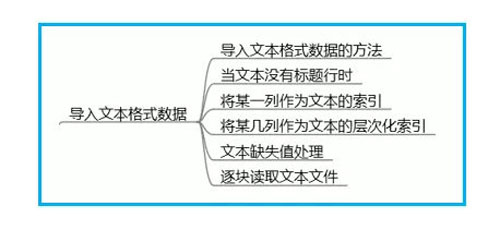
1、導入文本格式數據(CSV)的方法:
方法一:使用pd.read_csv(),默認打開csv文件。

9、10、11行三種方式均可以導入文本格式的數據。
特殊說明:第9行使用的條件是運行文件.py需要與目標文件CSV在一個文件夾中的時候可以只寫文件名。第10和11行中文件名ex1.CSV前面的部分均為文件的路徑。
方法二:使用pd.read.table(),需要指定是什么樣分隔符的文本文件。用sep=””來指定。

2、當文件沒有標題行時
可以讓pandas為其自動分配默認的列名。
也可以自己定義列名。

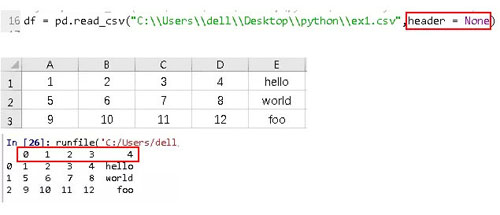
3、將某一列作為索引,比如使用message列做索引。通過index_col參數指定’message’。

4、要將多個列做成一個層次化索引,只需傳入由列編號或列名組成的列表即可。
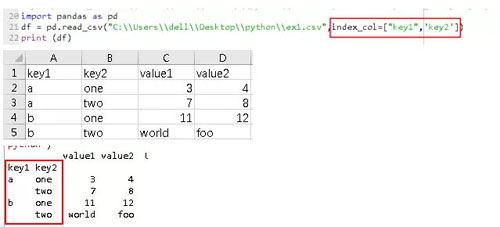
5、文本中缺失值處理,缺失數據要么是沒有(空字符串),要么是用某個標記值表示的,默認情況下,pandas會用一組經常出現的標記值進行識別,如NA、NULL等。查找出結果以NAN顯示。
6、逐塊讀取文本文件
如果只想讀取幾行(避免讀取整個文件),通過nrows進行制定即可。

7、對于不是使用固定分隔符分割的表格,可以使用正則表達式來作為read_table的分隔符。

(’\s+’是正則表達式中的字符)。
導入JSON數據
JSON數據是通過HTTP請求在Web瀏覽器和其他應用程序之間發送數據的標注形式之一。通過json.loads即可將JSON對象轉換成Python對象。(import json)
對應的json.dumps則將Python對象轉換成JSON格式。
導入EXCEL數據

直接使用read_excel(文件名路徑)進行獲取,與讀取CSV格式的文件類似。
導入數據庫數據
主要包含兩種數據庫文件,一種是SQL關系型數據庫數據,另一種是非SQL型數據庫數據即MongoDB數據庫文件。
數據庫文件是這幾種里面比較難的,本人沒有接觸數據庫文件,沒有親測,所以就不貼截圖了。
數據整理
合并數據集
1、數據庫風格的合并
數據庫風格的合并與SQL數據庫中的連接(join)原理一樣。通過調用merge函數即可進行合并。

當沒有指明用哪一列進行連接時,程序將自動按重疊列的列名進行連接,上述語句就是按重疊列“key”列進行連接。也可以通過on來指定連接列進行連接。

當兩個對象的列名不同時,即兩個對象沒有共同列時,也可以分別進行指定。
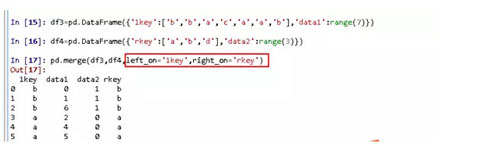
Left_on是指左側DataFrame中用作連接的列。
right_on是指右側DataFrame中用作連接的列。
通過上面的語句得到的結果里面只有a和b對應的數據,c和d以及與之相關的數據被消去,這是因為默認情況下,merge做的是‘inner’連接,即sql中的內連接,取得兩個對象的交集。也有其他方式連接:left、right、outer。用“how”來指明。

也可以根據多個鍵(列)進行合并,用on傳入一個由列名組成的列表即可。
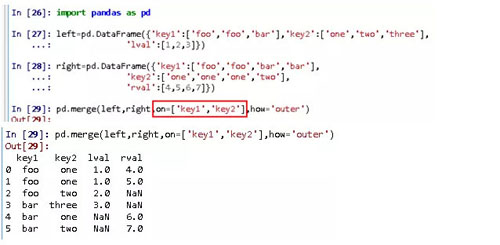
2、索引上的合并
(1)普通索引的合并
Left_index表示將左側的行索引引用做其連接鍵
right_index表示將右側的行索引引用做其連接鍵
上面兩個用于DataFrame中的連接鍵位于其索引中,可以使用Left_index=True或right_index=True或兩個同時使用來進行鍵的連接。

(2)層次化索引
與數據庫中用on來根據多個鍵合并一樣。
3、軸向連接(合并)
軸向連接,默認是在軸方向進行連接,也可以通過axis=1使其進行橫向連接。
(1)對于numpy對象(數組)可以用numpy中的concatenation函數進行合并。
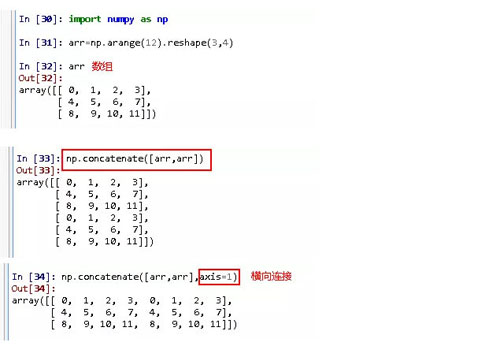
(2)對于pandas對象(如Series和DataFrame),可以pandas中的concat函數進行合并。

·4、合并重疊數據
對于索引全部或部分重疊的兩個數據集,我們可以使用numpy的where函數來進行合并,where函數相當于if—else函數。

對于重復的數據顯示出相同的數據,而對于不同的數據顯示a列表的數據。同時也可以使用combine_first的方法進行合并。合并原則與where函數一致,遇到相同的數據顯示相同數據,遇到不同的顯示a列表數據。

重塑數據集
1、旋轉數據
(1)重塑索引、分為stack(將數據的列旋轉為行)和unstack(將數據的行旋轉為列)。
(2)將‘長格式’旋轉為‘寬格式’
2、轉換數據
(1)數據替換,將某一值或多個值用新的值進行代替。(比較常用的是缺失值或異常值處理,缺失值一般都用NULL、NAN標記,可以用新的值代替缺失標記值)。方法是replace。

一對一替換:用np.nan替換-999

多對一替換:用np.nan替換-999和-1000.

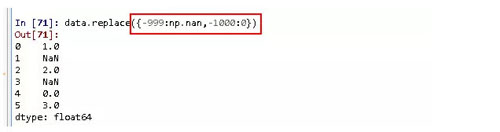
多對多替換:用np.nan代替-999,0代替-1000.
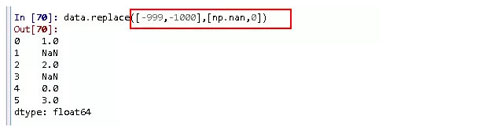
也可以使用字典的形式來進行替換。
(2)離散化或面元劃分,即根據某一條件將數據進行分組。
利用pd.cut()方式對一組年齡進行分組。

默認情況下,cut對分組條件的左邊是開著的狀態,右邊是閉合狀態。可以用left(right)=False來設置哪邊是閉合的。

清理數據集
主要是指清理重復值,DataFrame中經常會出現重復行,清理數據主要是針對這些重復行進行清理。

利用drop_duplicates方法,可以返回一個移除了重復行的DataFrame.

默認情況下,此方法是對所有的列進行重復項清理操作,也可以用來指定特定的一列或多列進行。

默認情況下,上述方法保留的是***個出現的值組合,傳入take_last=true則保留***一個。
![]()