













一文看懂:“計算機視覺”到底是個啥?
想象一下,有人朝你扔過來一個球,你會怎么辦?當然是馬上把它接祝這個問題是不是弱智死了?
但實際上,這一過程是最復雜的處理過程之一,而我們目前尚處于理解它的階段,離重塑還非常遙遠。這就意味著,發明一個像人類一樣去觀看的機器,是一項非常艱巨的任務,不僅是讓電腦去做到非常困難,甚至我們自己都無法確定完整的細節。
實際上的過程大概如下:首先球進入人類的視網膜,一番元素分析后,發送到大腦,視覺皮層會更加徹底地去分析圖像,把它發送到剩余的皮質,與已知的任何物體相比較,進行物體和緯度的歸類,最終決定你下一步的行動:舉起雙手、拿起球(之前已經預測到它的行進軌跡)。
上述過程只在零點幾秒內發生,幾乎都是完全下意識的行為,也很少會出差錯。因此,重塑人類的視覺并不只是單一一個困難的課題,而是一系列、環環相扣的過程。
早在1966年,人工智能領域的先鋒派人士Marivin Minsky就曾經給自己的研究生出題,要求他們“把攝像機連到一臺電腦上,讓它描述自己看到了什么。”而50年之后,今天的人們仍然在研究相同的課題。
這一領域的深入研究是從20世紀50年代開始的,走的是三個方向——即復制人眼(難度系數十顆星);復制視覺皮層(難度系數五十顆星),以及復制大腦剩余部分(難度系數一百顆星)。
復制人眼——讓計算機“去看”
目前做出最多成效的領域就是在“復制人眼”這一領域。在過去的幾十年,科學家已經打造了傳感器和圖像處理器,這些與人類的眼睛相匹配,甚至某種程度上已經超越。通過強大、光學上更加完善的鏡頭,以及納米級別制造的半導體像素,現代攝像機的精確性和敏銳度達到了一個驚人的地步。它們同樣可以拍下每秒數千張的圖像,并十分精準地測量距離。
數碼相機里的圖像傳感器
但是問題在于,雖然我們已經能夠實現輸出端極高的保真度,但是在很多方面來說,這些設備并不比19世紀的針孔攝像機更為出色:它們充其量記錄的只是相應方向上光子的分布,而即便是最優秀的攝像頭傳感器也無法去“識別”一個球,遑論將它抓祝
換而言之,在沒有軟件的基礎上,硬件是相當受限制的。因此這一領域的軟件才是要投入解決的更加棘手的問題。不過現在攝像頭的先進技術,的確為這軟件提供了豐富、靈活的平臺就是了。
復制視覺皮層——讓計算機“去描述”
要知道,人的大腦從根本上就是通過意識來進行“看”的動作的。比起其他的任務,在大腦中相當的部分都是專門用來“看”的,而這一專長是由細胞本身來完成的——數十億的細胞通力合作,從嘈雜、不規則的視網膜信號中提取模式。
如果在特定角度的一條沿線上出現了差異,或是在某個方向上出現了快速運動,那么神經元組就會興奮起來。較高級的網絡會將這些模式歸納進元模式(meta-pattern)中:它是一個朝上運動的圓環。同時,另一個網絡也相應而成:這次是帶紅線的白色圓環。而還有一個模式則會在大小上增長。從這些粗糙但是補充性的描述中,開始生成具體的圖像。
使用人腦視覺區域相似的技術,定位物體的邊緣和其他特色,從而形成的“方向梯度直方圖”
由于這些網絡一度被認為是“深不可測的復雜”,因此 在計算機視覺研究的早期,采用的是別的方式:即“自上而下的推理”模式——比如一本書看起來是“這樣”,那么就要注意與“這個”類似的模式。而一輛車看起來是“這樣”,動起來又是“這樣”。
在某些受控的情況下,確實能夠對少數幾個物體完成這一過程,但如果要描述身邊的每個物體,包括所有的角度、光照變化、運動和其他上百個要素,即便是咿呀學語的嬰兒級別的識別,也需要難以想象的龐大數據。
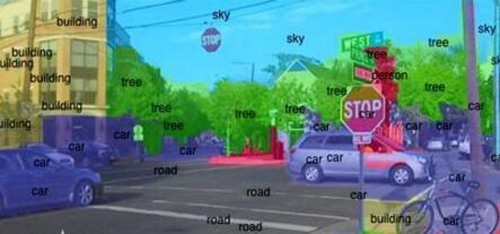
而如果不用“自上而下”,改用“自下而上”的辦法,即去模擬大腦中的過程,則看上去前景更加美好:計算機可以在多張圖中,對一張圖片進行一系列的轉換,從而找到物體的邊緣,發現圖片上的物體、角度和運動。就像人類的大腦一樣,通過給計算機觀看各種圖形,計算機會使用大量的計算和統計,試著把“看到的”形狀與之前訓練中識別的相匹配。
科學家正在研究的,是讓智能手機和其他的設備能夠理解、并迅速識別出處在攝像頭視場里的物體。如上圖,街景中的物體都被打上了用于描述物體的文本標簽,而完成這一過程的處理器要比傳統手機處理器快上120倍。
隨著近幾年并行計算領域的進步,相關的屏障逐漸被移除。目前出現了關于模仿類似大腦機能研究和應用的爆發性增長。模式識別的過程正在獲得數量級的加速,我們每天都在取得更多的進步。
復制大腦剩余部分——讓計算機“去理解”
當然,光是“識別”“描述”是不夠的。一臺系統能夠識別蘋果,包括在任何情況、任何角度、任何運動狀態,甚至是否被咬等等等等。但它仍然無法識別一個橘子。并且它甚至都不能告訴人們:啥是蘋果?是否可以吃?尺寸如何?或者具體的用途。
上文曾經談過,沒有軟件,硬件的發揮非常受限。但現在的問題是,即便是有了優秀的軟硬件,沒有出色的操作系統,也“然并卵”。
對于人們來說,大腦的剩余部分由這些組成,包括長短期記憶、其他感官的輸入、注意力和認知力、從世界中萬億級別的交互中收獲的十億計知識,這些知識將通過我們很難理解的方式,被寫入互聯的神經。而要復制它,比起我們遇到過的任何事情都要更加復雜。
計算機視覺的現狀和未來
這一點就是計算機科學和更加普遍的人工智能領域的前沿。計算機科學家、工程師、心理學家、神經學家和哲學家正在通力合作,形成關于意識運作的概念,但還是遠遠達不到模擬它的地步。
不過,這也并非意味著目前我們處于死胡同。計算機視覺的未來,將會集成強大而專門的系統,讓人們更加廣泛集中在難以解決的概念上:環境、注意力和意圖。
因此,即便是在如此早期的階段,計算機視覺仍然發揮了很大的作用。在攝像頭領域,是面部和笑容識別;在自駕車領域 ,則是讀取交通信號和注意行人;工廠里的機器人會通過它來檢測問題所在、并繞過周圍的人類公認。雖然說要實現“和人類一樣去看”仍然有很長的一段路,但是如果能夠實現的話,那會是非常美妙的未來。






















