一名合格的數據分析師分享Python網絡爬蟲二三事(Scrapy自動爬蟲)
作者:whenif
作為一名合格的數據分析師,其完整的技術知識體系必須貫穿數據獲取、數據存儲、數據提取、數據分析、數據挖掘、數據可視化等各大部分。
接上篇《一名合格的數據分析師分享Python網絡爬蟲二三事(綜合實戰案例)》
五、綜合實戰案例
3. 利用Scrapy框架爬取
(1)了解Scrapy
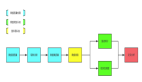
Scrapy使用了Twisted異步網絡庫來處理網絡通訊。整體架構大致如下(注:圖片來自互聯網):

關于Scrapy的使用方法請參考其官方文檔
(2)Scrapy自動爬蟲
前面的實戰中我們都是通過循環構建URL進行數據爬取,其實還有另外一種實現方式,首先設定初始URL,獲取當前URL中的新鏈接,基于這些鏈接繼續爬取,直到所爬取的頁面不存在新的鏈接為止。
(a)需求
采用自動爬蟲的方式爬取糗事百科文章鏈接與內容,并將文章頭部內容與鏈接存儲到MySQL數據庫中。
(b)分析
A. 怎么提取首頁文章鏈接?
打開首頁后查看源碼,搜索首頁任一篇文章內容,可以看到"/article/118123230"鏈接,點擊進去后發現這就是我們所要的文章內容,所以我們在自動爬蟲中需設置鏈接包含"article"

B. 怎么提取詳情頁文章內容與鏈接
- 內容
打開詳情頁后,查看文章內容如下:

分析可知利用包含屬性class且其值為content的div標簽可***確定文章內容,表達式如下:
- "//div[@class='content']/text()"
- 鏈接
打開任一詳情頁,復制詳情頁鏈接,查看詳情頁源碼,搜索鏈接如下:

采用以下XPath表達式可提取文章鏈接。
- ["//link[@rel='canonical']/@href"]
(3)項目源碼
A. 創建爬蟲項目
打開CMD,切換到存儲爬蟲項目的目錄下,輸入:
- scrapy startproject qsbkauto

B. 項目結構說明
- spiders.qsbkspd.py:爬蟲文件
- items.py:項目實體,要提取的內容的容器,如當當網商品的標題、評論數等
- pipelines.py:項目管道,主要用于數據的后續處理,如將數據寫入Excel和db等
- settings.py:項目設置,如默認是不開啟pipeline、遵守robots協議等
- scrapy.cfg:項目配置
C. 創建爬蟲
進入創建的爬蟲項目,輸入:
- scrapy genspider -t crawl qsbkspd qiushibaie=ke.com(域名)
D. 定義items
- import scrapyclass QsbkautoItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- Link = scrapy.Field() #文章鏈接
- Connent = scrapy.Field() #文章內容
- pass
E. 編寫爬蟲
- qsbkauto.py
- # -*- coding: utf-8 -*-import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom qsbkauto.items import QsbkautoItemfrom scrapy.http import Requestclass QsbkspdSpider(CrawlSpider):
- name = 'qsbkspd'
- allowed_domains = ['qiushibaike.com']
- #start_urls = ['http://qiushibaike.com/']
- def start_requests(self):
- i_headers={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0"}
- yield Request('http://www.qiushibaike.com/',headers=i_headers)
- rules = (
- Rule(LinkExtractor(allow=r'article/'), callback='parse_item', follow=True),
- )
- def parse_item(self, response):
- #i = {}
- #i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
- #i['name'] = response.xpath('//div[@id="name"]').extract()
- #i['description'] = response.xpath('//div[@id="description"]').extract()
- i = QsbkautoItem()
- i["content"]=response.xpath("//div[@class='content']/text()").extract()
- i["link"]=response.xpath("//link[@rel='canonical']/@href").extract()
- return i
pipelines.py
- import MySQLdbimport timeclass QsbkautoPipeline(object):
- def exeSQL(self,sql):
- '''
- 功能:連接MySQL數據庫并執行sql語句
- @sql:定義SQL語句
- '''
- con = MySQLdb.connect(
- host='localhost', # port
- user='root', # usr_name
- passwd='xxxx', # passname
- db='spdRet', # db_name
- charset='utf8',
- local_infile = 1
- )
- con.query(sql)
- con.commit()
- con.close()
- def process_item(self, item, spider):
- link_url = item['link'][0]
- content_header = item['content'][0][0:10]
- curr_date = time.strftime('%Y-%m-%d',time.localtime(time.time()))
- content_header = curr_date+'__'+content_header
- if (len(link_url) and len(content_header)):#判斷是否為空值
- try:
- sql="insert into qiushi(content,link) values('"+content_header+"','"+link_url+"')"
- self.exeSQL(sql)
- except Exception as er:
- print("插入錯誤,錯誤如下:")
- print(er)
- else:
- pass
- return item
- setting.py
- 關閉ROBOTSTXT_OBEY
- 設置USER_AGENT
- 開啟ITEM_PIPELINES
F. 執行爬蟲
- scrapy crawl qsbkauto --nolog
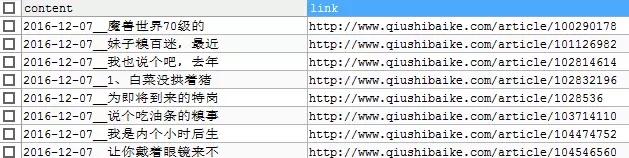
G. 結果
【本文是51CTO專欄機構“豈安科技”的原創文章,轉載請通過微信公眾號(bigsec)聯系原作者】

責任編輯:趙寧寧
來源:
51CTO專欄