













一日一技:為什么 Scrapy 啟動 A 爬蟲,B 爬蟲會自動啟動?
昨天有位同學在公眾號俱樂部群問了這樣一個問題:

他在一個 Scrapy 項目里面,有兩個爬蟲 A 和 B,他使用命令scrapy crawl B想啟動 B 爬蟲,但是發現 A 爬蟲也自動運行了。
然后,這個同學貼上來他的爬蟲代碼:

看到這個代碼,我就知道是怎么回事了。要解釋這個現象,我們需要掌握兩個知識點:
Scrapy 是怎么加載爬蟲的?
Python 的類變量與實例變量的區別。
Scrapy 是怎么加載爬蟲的?
我們知道,Scrapy 的 spiders 文件夾里面,可以定義很多個爬蟲文件。只要每個爬蟲文件的 name 的值不一樣,那么,我們就可以使用scrapy crawl name 的值來啟動特定的爬蟲。
那么,Scrapy 它是怎么根據這個名字找到對應的類的呢?
實際上,在我們執行scrapy crawl xxx的時候,Scrapy 有幾個主要的步驟:
- 首先遍歷spiders 文件夾下面的所有文件,在這些文件里面,尋找繼承了scrapy.Spider的類
- 獲取每個爬蟲類的name屬性的值
- 添加到一個公共的字典里面{'name1': 爬蟲類1, 'name2': '爬蟲類2'}
- 獲取scrapy crawl xxx具體要啟動的那個爬蟲的名字,從公共字典里面,找到這個名字對應的爬蟲類
- 執行這個爬蟲類,得到一個爬蟲對象。然后調用爬蟲對象的start_requests()方法
從這個過程我們可以知道,spiders 文件夾下面,每一個爬蟲類都會被加載。
Python 的類屬性和實例屬性
在我們定義Python 類的時候,我們其實可以在類里面,所有方法的外面寫代碼,例如:
- class Test:
- a = 1 + 1
- b = 2 + 2
- if a + b == 6:
- right = True
- else:
- right = False
- def __init__(self):
- self.age = 100
- self.address = '上海'
大家注意這幾行代碼:
- a = 1 + 1
- b = 2 + 2
- if a + b == 6:
- right = True
- else:
- right = False
他們不在任何方法里面的,這里面初始化的變量,叫做類變量或者類屬性。而在__init__里面,初始化的self.age和self.address叫做實例屬性。
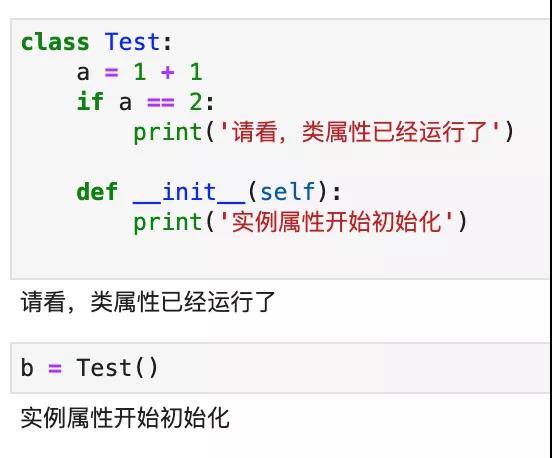
實例屬性只有在類被執行的時候,獲得實例對象的時候,才會執行。而類屬性,是在類被 Python 加載的時候,就會執行。大家注意下面這段代碼:

Python 只是加載了這個類,并沒有初始化它,但里面的 print語句已經執行了。
而當我們初始化它以后,實例屬性才會執行:
什么情況叫做Python 加載了一個類呢?
例如,當你from xxx import yyy的時候,yyy這個類就被加載了。又比如你可能是使用imortlib.import_module的時候。
所以,回到這個同學的問題。之所以他其中一個爬蟲的代碼始終會運行,原因就在下面紅色圓圈中的代碼:

他把這段代碼寫在了所有方法之外,讓他處于了類屬性的區域。在這個區域里面的代碼,在爬蟲類被加載的時候,就會執行。
如果要解決這個問題,只需要把這段代碼,放到start_requests()方法里面就可以了。
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。























