MetaMind深度解讀NLP研究:如何讓機器學習跳讀
自然語言處理是人工智能研究的核心問題之一。近日,已宣布被 Salesforce 收購的深度學習公司 MetaMind 在其官方網站上發表了一篇文章,深度剖析了 LSTM 和詞袋模型在自然語言處理上的應用。
機器學習、深度學習和更廣義上的人工智能的興起是毫無疑問的,而且其已經對計算機科學領域產生巨大的影響。你可能已經聽說過,目前深度學習已經在圖像識別和圍棋等很多任務上實現了對人類的超越。
深度學習社區目前將自然語言處理(NLP)看作是下一個研究和應用的前沿。
深度學習的一大優勢是其進步往往是非常通用的。比如說,使深度學習在一個領域有效的技術往往不需要太多修改就能遷移到另一個領域。更具體而言,為圖像和語音識別所開發的構建大規模、高計算成本的深度學習模型的方法也能被用于自然語言處理。最近的最先進的翻譯系統就是其中一例,該系統的表現超越了所有以往的系統,但所需的計算機能力也要多得多。這樣的高要求的系統能夠在真實世界數據中發現偶然出現的非常復雜的模式,但這也讓很多人將這樣的大規模模型用在各種各樣的任務上。這又帶來了一個問題:
是否所有的任務都具有需要這種模型才能處理的復雜度?
讓我們看看一個用于情感分析的在詞袋嵌入(bag-of-words embeddings)上訓練的一個兩層多層感知器(two layered MLP)的內部情況:
上訓練的一個兩層多層感知器(two layered MLP)的內部情況")
一個被稱為詞袋(bag-of-words)的簡單深度學習系統的內部情況,其可以將句子分類為積極的(positive)或消極的(negative)。這張圖是來自在一個詞袋上的一個 2 層 MLP 最后一個隱藏層的一個 T-SNE。其中每個數據點對應于一個句子,不同的顏色分別對應于該深度學習系統的預測和真實目標。實線框表示句子的不同語義內容。后面你可以通過一張交互式圖表來了解它們。
上圖中的實線框提供了一些重要的見解。而真實世界數據的難度遠不止此,一些句子可以被輕松分類,但另一些卻包含了復雜的語義結構。在可以輕松分類的句子的案例中,高容量的系統可能并不是必需的。也許一個簡單得多的模型就能完成同樣的工作。這篇博客文章探討了這種情況是否屬實,并將說明我們其實往往使用簡單模型就能完成任務。
一、對文本的深度學習
大多數深度學習方法需要浮點數作為輸入,如果你沒使用過文本,你可能會疑問:
我怎么使用一段文本來進行深度學習?
對于文本,其核心問題是在給定材料的長度的情況下如何表征任意大量的信息。一種流行的方法是將文本切分(tokenize)成詞(word)、子詞(sub-word)甚至字符(character)。然后每一個詞都可以通過 word2vec 或 Glove 等經過了充分研究的方法而轉換成一個浮點向量。這種方法可以通過不同詞之前的隱含關系來提高對詞的有意義的表征。

取一個詞,將其轉換成一個高維嵌入(比如 300 維),然后使用 PCA 或 T-SNE(流行的降維工具,在這個案例中是降為 2 維),你就可以找到詞之間的有趣關系。比如,在上圖中你可以看到 uncle 與 aunt 之間的距離和 man 與 woman 之間的距離差不多相等(來自 Mikolov et al., 2013)
通過使用 tokenization 和 word2vec 方法,我們可以將一段文本轉換為詞的浮點表示的一個序列。
現在,一個詞表征的序列有什么用?
二、詞袋(bag-of-words)
現在我們來探討一下詞袋(BoW),這也許是最簡單的機器學習算法了!
")
取一些詞表征(圖下部的灰色框),然后通過加(sum)或平均(average)得到一個共同的表征(藍色框),這個共同表征(common representation)包含了每個詞的一些信息。在這篇文章中,該共同表征被用于預測一個句子是積極的還是消極的(紅色框)。
在每個特征維(feature dimension)上簡單地取詞的平均(mean)。事實證明簡單地對詞嵌入(word embedding)進行平均(盡管這完全忽略了句子的順序)就足以在許多簡單的實際案例中取得良好的效果,而且也能在與深度神經網絡結合時提供一個強大的基準(后面會解釋)。
此外,取平均的計算成本很低,而且可以將句子的降維成固定大小的向量。
三、循環神經網絡
一些句子需要很高的準確度或依賴于句子結構。使用詞袋來解決這些問題可能不能滿足要求。不過,你可以考慮使用讓人驚嘆的循環神經網絡(Recurrent Neural Networks)。
")
在每一個時間步驟(從左到右),一個輸入(比如一個詞)被饋送入 RNN(灰色框),并整合之前的內部記憶(藍色框)。然后該 RNN 執行一些計算,得到新的內部記憶(藍色框),該記憶表示了所有之前見過的單元(如,所有之前的詞)。該 RNN 現在應該已經包含了一個句子層面的信息,讓其可以更好地預測一個句子是積極的還是消極的(紅色框)。
每個詞嵌入都按順序被送入一個循環神經網絡,然后該網絡可以存儲之前見過的信息并將其與新的詞結合起來。當使用長短期記憶(LSTM)或門控循環單元(GRU)等著名的記憶單元來驅動 RNN 時,該 RNN 能夠記住具有很多個詞的句子中所發生的情況!(因為 LSTM 的成功,帶有 LSTM 記憶單元的 RNN 常被稱為 LSTM。)這類模型中最大的模型將這樣的結構堆疊了 8 次。

都表示帶有 LSTM 單元的循環神經網絡。它們也應用了一些權衡的技巧,比如跳過 LSTM 層之間的連接和一種被稱為注意(attention)的方法。另外要注意綠色的 LSTM 指向了相反的方向。當與一個普通的 LSTM 結合時,這被稱為雙向 LSTM(bidirectional LSTM),因為其可以在數據序列的兩個方向上都獲取信息。更多信息可參閱 Stephen Merity 的博客(即機器之心文章《深度 | 逐層剖析,谷歌機器翻譯突破背后的神經網絡架構是怎樣的?》)(來源:Wu et al., 2016)。
但是,和簡單的詞袋模型比起來,LSTM 的計算成本要高得多,而且需要經驗豐富的深度學習工程師使用高性能的計算硬件來實現和提供支持。
四、例子:情感分析
情感分析(sentiment analysis)是一種量化主觀性文章的極性的文檔分類任務。給定一個句子,模型去評估它的情感是積極、消極還是中性的。
想要在事態嚴重前先發現 Twitter 上的憤怒客戶嗎?那么,情感分析可能正是你想要的!
一個極佳的實現此目的的數據集(我們接下來會用到)是 Stanford sentiment treebank(SST):
https://nlp.stanford.edu/sentiment/treebank.html
我們已經公開了一個 PyTorch 的數據加載器:
https://github.com/pytorch/text
STT 不僅可以給句子分類(積極、消極),而且也可以給每個句子提供符合語法的子短語(subphrases)。然而,在我們的系統中,我們不使用任何樹信息(tree information)。
原始的 SST 由 5 類構成:非常積極、積極、中性、消極、非常消極。我們認為二值分類任務更加簡單,其中積極與非常積極結合、消極與非常消極結合,沒有中性。
我們為我們的模型架構提供了一個簡略且技術化的描述。重點不是它到底如何被構建,而是計算成本低的模型達到了 82% 的驗證精度,一個 64 大小的批任務用了 10 毫秒,而計算成本高的 LSTM 架構雖然驗證精度達到了 88% 但是需耗時 87 毫秒才能處理完同樣的任務量(最好的模型大概精度在 88-90%)。

下面的綠色框表示詞嵌入,使用 GloVe 進行了初始化,然后是取詞的平均(詞袋)和帶有 dropout 的 2 層 MLP。

下面的藍綠色框表示詞嵌入,使用 GloVe 進行了初始化。在整個詞嵌入中沒有跟蹤梯度。我們使用了一個帶有 LSTM 單元的雙向 RNN,使用的方式類似于詞袋,我們使用了該 RNN 隱藏狀態來提取均值和最大值,之后是一個帶 dropout 的 2 層 MLP。
五、低計算成本的跳讀閱讀器(skim reader)
在某些任務中,算法可以展現出接近人類水平的精度,但是要達到這種效果,你的服務器預算恐怕得非常高。你也知道,不一定總是需要使用有真實世界數據的 LSTM,用低成本的詞袋(BoW)或許也沒問題。
當然,順序不可知的詞袋(BoW)會將大量消極詞匯錯誤分類。完全切換到一個劣質的詞袋(BoW)會降低我們的總體性能,讓它聽上去就不那么令人信服了。所以問題就變成了:
我們能否學會區分「簡單」和「困難」的句子。
而且為了節省時間,我們能否用低成本的模型來完成這項任務?
六、探索內部
探索深度學習模型的一種流行的方法是了解每個句子在隱藏層中是如何表示的。但是,因為隱藏層常常是高維的,所以我們可以使用 T-SNE 這樣的算法來將其降至 2 維,從而讓我們可以繪制圖表供人類觀察。


上面兩張圖是原文中可交互的圖示的截圖。在原交互圖中,你可以將光標移動、縮放和懸停在數據點上來查看這些數據點的信息。在圖中,你可以看到在詞袋(BoW)中的最后一個隱藏層。當懸停在任何數據點上時,你可以看到表示該數據點的句子。句子的顏色取決于其標簽(label)。
Predictions 標簽頁:該模型的系統預測與實際標簽的比較。數據點的中心表示其預測(藍色表示積極,紅色表示消極),周圍的線表示實際的標簽。讓我們可以了解系統什么時候是正確的,什么時候是錯誤的。
Probabilities 標簽頁:我們繪制了在輸出層中被預測的類別的概率。這表示了該模型對其預測的信息。此外,當懸停在數據點上時,也將能看到給定數據點的概率,其顏色表示了模型的預測。注意因為該任務是二元分類,所以其概率是從 0.5 開始的,在這個案例中的最小置信度為 50/50.
T-SNE 圖容易受到許多過度解讀的破壞,但這可能能讓你了解一些趨勢。
七、T-SNE 的解讀
- 句子變成聚類(cluster),聚類構成不同的語義類型。
- 一些聚類具有簡單的形式,而且具有很高的置信度和準確度。
- 其它聚類更加分散,帶有更低的準確度和置信度。
- 帶有積極成分和消極成分的句子是很困難的。
現在讓我們看看在 LSTM 上的相似的圖:


上面兩張圖是原文中可交互的圖示的截圖。在原交互圖中,你可以將光標移動、縮放和懸停在數據點上來查看這些數據點的信息。設置和詞袋的交互圖類似,快來探索 LSTM 的內部吧!
我們可以認為其中許多觀察也對 LSTM 有效。但是,LSTM 只有相對較少的樣本,置信度也相對較低,而且句子中同時出現積極和消極的成分時,對 LSTM 來說的挑戰性也要低于對詞袋的挑戰性。
看起來詞袋可以聚類句子,并使用其概率來識別是否有可能給那個聚類中的句子提供一個正確的預測。對于這些觀察,可以做出一個合理的假設:置信度更高的答案更正確。
為了研究這個假設,我們可以看看概率閾值(probability thresholds)。
八、概率閾值
人們訓練詞袋和 LSTM 為每一個類提供概率,以度量確定性。這是什么意思?如果詞袋返回一個 1,那么表示它對其預測很自信。通常在預測時我們采用由我們的模型提供且帶有最高可能性的類。在這種二元分類的情況下(積極或消極),概率必須超過 0.5(否則我們會預測相反的類)。但是一個被預測類的低概率也許表明該模型存疑。例如,一個模型預測的積極概率為 0.51,消極概率為 0.49,那么說這個結論是積極的就不太可信。當使用「閾值」時,我們是指將預測出的概率與一個值相比較,并評估要不要使用它。例如,我們可以決定使用概率全部超過 0.7 的句子。或者我們也可以看看 0.5-0.55 的區間給預測置信度帶來什么影響,而這正是在下圖所要精確調查的。


在這張閾值圖中,柱的高度對應于兩個閾值內的數據點的精確度;線表示當所有的數據點超出給定的閾值時的類似的精確度。在數據數量圖中,柱的高度對應于兩個閾值內 data reciding 的量,線則是每個閾值倉積累的數據。
從每個詞袋圖中你也許發現增加概率閾值性能也會隨之提升。當 LSTM 過擬合訓練集并只提供置信度高的答案時,上述情況在 LSTM 圖中并不明顯就似乎很正常了。
| 在容易的樣本上使用 BoW,在困難的樣本上使用原始 LSTM |
因此,簡單使用輸出概率就能向我們表明什么時候一個句子是容易的,什么時候需要來自更強系統(比如強大的 LSTM)的指導。
我們使用概率閾值創建了一種「概率策略」(probability strategy),從而可為詞袋系統的概率設置閾值,并在所有沒有達到閾值的數據點上使用 LSTM。這樣做為我們提供了用于詞袋的那么多的數據(在閾值之上的句子)和一系列數據點,其中我們要么選擇 BoW(在閾值之上),要么選擇 LSTM(在閾值之下),我們可以用此發現一個精度和計算成本。接著我們會獲得 BoW 和 LSTM 之間的一個從 0.0(僅使用 LSTM)到 1.0(僅使用 BoW)的比率,并可借此計算精度和計算時間。
九、基線(Baseline)
為了構建基線(baseline),我們需要考慮兩個模型之間的比率。例如詞袋(BoW)使用 0.1 的數據就相當于 0.9 倍 LSTM 的準確率和 0.1 倍 BoW 的準確率。其目的是取得沒有指導策略(guided strategy)的基線,從而在句子中使用 BoW 或 LSTM 的選擇是隨機分配的。然而,使用策略時是有成本的。我們必須首先通過 BoW 模型處理所有的句子,從而確定我們是否該使用 BoW 或 LSTM。在沒有句子達到概率閥值(probability threshold)的情況下,我們可以不需要什么理由運行額外的模型。為了體現這一點,我們從以下方式計算策略成本與比率。

其中 C 代表著成本,p 代表著 BoW 使用數據的比例。

上圖是驗證集上的結果,其比較了 BoW、LSTM(紅線)和概率閥值策略(藍線)之間不同組合比率的精度和速度,最左側的數據點對應于只使用 LSTM,最右邊的只使用 BoW,中間的對應著使用兩者的組合。藍線代表著沒有指導策略的 CBOW 和 LSTM 組合,紅線描述了使用 BoW 概率作為策略指導哪個系統使用多大比例。注意最大的時間節省超過了 90%,因為其僅僅只使用了 BoW。有趣的是,我們發現使用 BoW 閥值要顯著優于沒有使用指導策略(guided strategy)的情況。
我們隨后測量了曲線的均值,我們稱之為曲線下速度(Speed Under the Curve /SUC),其就如下表所示。
")
以上是在驗證集中離散地選擇使用 BoW 還是 LSTM 的策略結果。每一個模型會在不同 seed 的情況下計算十次。該表格中的結果是 SUC 的均值。概率策略(probability strategy)也會和比率(Ratio)相比較。
十、學習何時跳讀何時閱讀
知道什么時候在兩個不同模型之間轉換還不夠,因為我們要構建一個更通用的系統,學習在所有不同模型之間轉換。這樣的系統將幫助我們處理更復雜的行為。
在監督學習中當閱讀完勝于跳讀時,我們可以學習嗎?
LSTM 自左到右地「閱讀」我們,每一步都存儲一個記憶,而「跳讀」則使用 BoW 模型。在來自詞袋模型上的概率操作時,我們基于不變量做決策,這個不變量是指當詞袋系統遭到質疑時,更強大的 LSTM 工作地更好。但是情況總是如此嗎?

當詞袋和 LSTM 關于一個句子是正確或錯誤的時候的「混淆矩陣」(confusion matrix)。相似于來自之前的詞袋和 LSTM 之間的混淆 T-SNE 圖。
事實上,結果證明這種情況只適用于 12% 的句子,而 6% 的句子中,詞袋和 LSTM 都錯了。在這種情況下,我們沒有理由再運行 LSTM,而只使用詞袋以節省時間。
十一、學習跳讀,配置
當 BoW 遭受質疑時我們并不總是應該使用 LSTM。當 LSTM 也犯錯并且我們要保留珍貴的計算資源時,我們可以使詞袋模型理解嗎?
讓我們再一次看看 T-SNE 圖,但是現在再加上 BoW 和 LSTM 之間的混淆矩陣圖。我們希望找到混淆矩陣不同元素之間的關系,尤其是當 BoW 錯誤時。


從對比圖中,我們發現當 BoW 是正確的,并遭受懷疑時,我們很容易判決出來。然而,當 LSTM 可能是對或錯時,BoW 與 LSTM 之間并沒有明確的關系。
1. 我們能學習這種關系嗎?
另外,因為概率策略依賴于二元決策并要求概率,其是有很大的限制性的。相反,我們提出了一個基于神經網絡的可訓練決策網絡(decision network)。如果我們查看混淆矩陣(confusion matrix),那么我們就能使用這些信息為監督決策網絡生成標簽。因此,我們就能在 LSTM 正確且 BoW 錯誤的情況下使用 LSTM。
為了生成數據集,我們需要一個句子集,其包含了詞袋和 LSTM 的真實、潛在的預測。然而在訓練 LSTM 的過程中,其經常實現了超過 99% 的訓練準確度,并顯然對訓練集存在過擬合現象。為了避免這一點,我們將訓練集分割成模型訓練集(80% 的訓練數據)和決策訓練集(余下 20% 的訓練數據),其中決策訓練集是模型之前所沒有見過的。之后,我們使用余下的 20% 數據微調了模型,并期望決策網絡能泛化到這一個新的、沒見過的但又十分相關的數據集,并讓系統更好一些。

詞袋和 LSTM 最初都是在「Model train」上先進行訓練(80% 訓練數據),隨后這些模型被用于生成決策網絡的標簽,再進行完整數據集的訓練。驗證集在這段時間一直被使用。
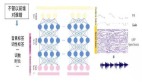
為了構建我們的決策網絡,我們進入我們低成本的詞袋系統的最后一個隱藏層(用來生成 T-SNE 圖的同一層)。我們在模型訓練集上的詞袋訓練之上疊加一個兩層 MLP。我們發現,如果我們不遵循這個方法,決策網絡將無法了解 BoW 模型的趨勢,并且不能很好地進行泛化。

底部的長條狀代表詞袋系統的層,不包含 dropout。一個雙層的 MLP 被加在頂部,一個類用于是否選擇詞袋或卓越的 LSTM。
由決策網絡在驗證集上選擇的類別(在模型訓練集上訓練過的模型基礎上)接著被應用于完全訓練集上訓練過但非常相關的模型上。為什么要應用到一個完全訓練集訓練過的模型上?因為模型訓練集上的模型通常較差,因此準確度會比較低。該決策網絡是基于在驗證集上的 SUC 最大化而利用早停(early stopping)訓練的。
2. 決策網絡的表現如何?
讓我們從觀察決策網絡的預測開始。

數據點和之前使用詞袋模型時的 T-SNE 圖相同。綠色點代表使用詞袋預測的句子,黃色點代表 LSTM。
注意:這有多近似詞袋的概率截止(probability cutoff)。讓我們看看決策網絡最后一個隱藏層的 T-SNE 是否能夠真的聚集一些關于 LSTM 什么時候正確或錯誤的信息。
")
3. 網絡如何執行我們的決策?
讓我們從決策網絡的預測開始。
數據點基于決策網絡最后隱藏狀態的語句表征,源自驗證語句。顏色和之前的比較圖相同。
看起來決策網絡能夠從詞袋的隱藏狀態中拾取聚類。然而,它似乎不能理解何時 LSTM 可能是錯誤的(將黃色和紅色聚類分開)。

紫色曲線代表在驗證集上新引入的決策網絡,注意決策網絡如何實現接近但略微不同于概率閾值的解決方案。從時間曲線和數據精度來看,決策網絡的優勢并不明顯。

Bow 與 LSTM 在測試集和驗證集中的表現。SUC 基于準確率與速度圖的平均值。每個模型都用不同種子計算了十次。表中結果來自 SUC 的平均數。標準偏差基于與比率的差異。
從預測圖、數據量、準確率和 SUC 分數中,我們可以推斷決策網絡很善于了解 BoW 何時正確,何時不正確。而且,它允許我們構建一個更通用的系統,挖掘深度學習模型的隱藏狀態。然而,它也表明讓決策網絡了解它無法訪問的系統行為是非常困難的,例如更復雜的 LSTM。
十二、討論
我們現在終于明白了 LSTM 的真正實力,它可以在文本上達到接近人類的水平,同時為了達到這一水平,訓練也不需要接近真實世界的數據量。我們可以訓練一個詞袋模型(bag-of-words model)用于理解簡單的句子,這可以節省大量的計算資源,整個系統的性能損失微乎其微(取決于詞袋閾值的大小程度)。
這個方法與平均相關,該平均通常是當類似于帶有高置信度的模型將被使用時而執行的。但是,只要有一個可調整置信度的詞袋,并且不需要運行 LSTM,我們就可以自行權衡計算時間和準確度的重要性并調整相應參數。我們相信這種方法對于那些尋求在不犧牲性能的前提下節省計算資源的深度學習開發者會非常有幫助。
文章中有一些交互式圖示,感興趣的讀者可以瀏覽原網頁查閱。本文作者為 MetaMind 研究科學家 Alexander Rosenberg Johansen。據介紹,該研究的相關論文將會很快發布到 arXiv 上。
原文:https://metamind.io/research/learning-when-to-skim-and-when-to-read
【本文是51CTO專欄機構機器之心的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】