遷移學習,讓深度學習不再困難……

在不遠的過去,數據科學團隊需要一些東西來有效地利用深度學習:
- 新穎的模型架構,很可能是內部設計的
- 訪問大型且可能是專有的數據集
- 大規模模型訓練所需的硬件或資金
這就阻礙了深度學習,將其局限于滿足這些條件的少數項目。
然而,在過去幾年里,情況發生了變化。
在Cortex,用戶推出了基于深度學習的新一代產品,與以前不同的是,這些產品并非都是使用獨一無二的模型架構構建的。
這種進步的背后驅動力是遷移學習。
什么是遷移學習?
廣義上講,遷移學習是指在為特定任務訓練的模型中積累知識,例如,識別照片中的花可以轉移到另一個模型中,以助于對不同的相關任務(如識別某人皮膚上的黑色素瘤)進行預測。
注:如果想深入研究遷移學習,塞巴斯蒂安·魯德(Sebastian Ruder)已經寫了一本很棒的入門書。
遷移學習有多種方法,但有一種方法被廣泛采用,那就是微調。
在這種方法中,團隊得到一個預訓練的模型,并移除/重新訓練模型的最后一層,以專注于一個新的、相關的任務。例如,AI Dungeon是一款開放世界的文本冒險游戲,因其人工智能生成的故事極具說服力,而迅速風靡:

值得注意的是,AI Dungeon不是在谷歌的一個研究實驗室里開發的,它是由一個工程師建造的項目。
AI Dungeon的創建者尼克·沃爾頓(NickWalton)并不是從頭開始設計一個模型的,而是通過采用最先進的NLP模型OpenAI的GPT-2,然后根據自行選擇的冒險文本進行微調。
這項工作之所以有效,是因為在神經網絡中,最初的層關注簡單的、一般的特征,而最終層則關注更多針對任務的分類/回歸。吳恩達通過想象一個圖像識別模型來可視化這些層和它們的相對特異性水平:
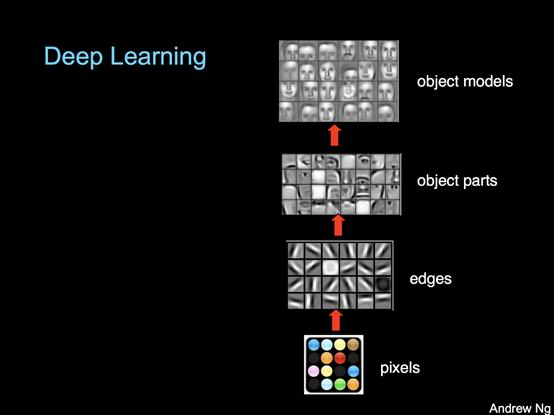
事實證明,基礎層的一般知識通常可以很好地轉化為其他任務。在AI地牢的例子中,GPT-2對普通英語有著比較先進的理解,只需在其最終層進行一些再訓練,就可以在自己選擇的冒險類型中表現出色。
通過這個過程,一個工程師可以在幾天內將一個模型部署到一個新的領域中,從而獲得比較新的結果。
為什么遷移學習是下一代機器學習驅動型軟件的關鍵
在前面,筆者提到機器學習和深度學習所需要的有利條件,特別是要有效地使用這些條件。你需要訪問一個大的、干凈的數據集,需要設計一個有效的模型,需要方法進行訓練。
這意味著在默認情況下,在某些領域或沒有某些資源的項目是不可行的。
現在,通過遷移學習,這些瓶頸正在消除:
一、小數據集不再是決定性因素
深度學習通常需要大量的標記數據,在許多領域中,這些數據根本不存在。遷移學習可以解決這個問題。
例如,哈佛醫學院下屬的一個研究小組最近部署了一個模型,該模型可以“根據胸片預測長期死亡率,包括非癌癥死亡”。
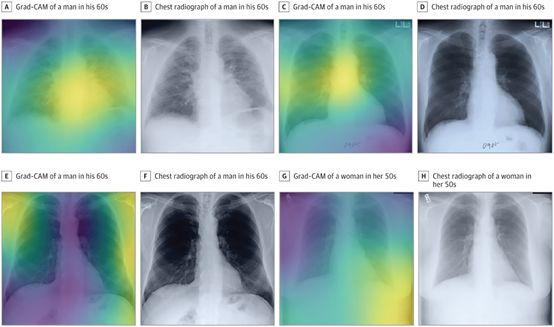
在擁有大約50000個標記圖像的數據集的條件下,研究人員沒有從零開始訓練CNN(卷積神經網絡)所需的數據。取而代之的是,他們采用一個預訓練的Inception-v4模型(在擁有超過1400萬張圖像的ImageNet數據集上進行訓練),使用遷移學習,通過輕微修改架構來使模型適應他們的數據集。
最后,他們的CNN成功地僅使用一張胸部圖像為每位患者生成與患者實際死亡率相關的風險評分。
二、模型可以在幾分鐘內訓練,而不是幾天
在海量數據上訓練模型不僅是獲取大型數據集的問題,也是資源和時間的問題。
例如,當谷歌開發比較先進的圖像分類模型exception時,他們訓練兩個版本:一個是ImageNet數據集(1400萬張圖像),另一個是JFT數據集(3.5億張圖像)。
在60 NVIDIAK80GPUs上進行各種優化的訓練,運行一個ImageNet實驗需要3天。JFT的實驗花了一個多月的時間。
然而,現在已經發布預先訓練的Xception模型,團隊可以更快地微調自己的版本。
例如,伊利諾伊大學和阿貢國家實驗室的一個小組最近訓練了一個模型,將星系的圖像分為螺旋狀或橢圓形:

盡管只有35000個標記圖像的數據集,他們能夠在8分鐘內使用NVIDIAGPUs對Xception進行微調。
當在GPU上運行時,模型能夠以每分鐘超20000個星系的超人速度對星系分類,準確率達99.8%。
三、你不再需要風險投資來訓練模型
當在60 GPUs上訓練Xception模型需要數月的時間的時候,谷歌可能不太在乎成本。然而,對于任何沒有谷歌規模預算的團隊來說,模型訓練的價格是一個真正令人擔憂的問題。
例如,當OpenAI第一次公布GPT-2的結果時,他們發布了模型架構,但由于擔心誤用,沒有發布完整的預訓練模型。
作為回應,Brown的一個團隊按照本文所述的架構和訓練過程復制GPT-2,并調用模型OpenGPT-2。他們花了大約5萬美元去訓練,但表現不如GPT-2。
如果一個模型的性能低于比較先進的水平,那么5萬美元對于任何一個團隊來說都是一個巨大的風險,因為他們在沒有大量資金的情況下去構建真正的軟件。
建造AI Dungeon時,尼克·沃爾頓通過微調GPT-2來完成項目。OpenAI已經投入大約27118520頁的文本和數千美元來訓練這個模型,而沃爾頓不需要重新創建任何一個。
取而代之的是,他使用從chooseyourstory.com上截取了一組小得多的文本,并在完全免費的GoogleColab中對模型進行微調。
機器學習工程正在成為一個真正的生態系統
相比軟件工程,從相當標準的模式來看,人們一般認為生態系統已經“成熟”。
一種涵蓋了一些極強性能的新編程語言即將出現,人們將把它用于專門的案例、研究項目和玩具上。在這個階段,任何使用它的人都必須從頭開始構建所有的基本實用程序。
接下來,這一社區中的人們開發庫和項目,將公共實用程序抽離出來,直到工具能夠穩定地用于生產。
在這個階段,使用它來構建軟件的工程師并不關心發送HTTP請求或連接到數據庫,所有這些都被抽離出來的,工程師們只關注于構建他們的產品。
換句話說,臉書構建React,谷歌構建Angular,而工程師使用它們來構建產品。隨著遷移學習的發展,機器學習工程正朝著這一方向邁進。
隨著OpenAI、谷歌、臉書和其他科技巨頭發布強大的開源模型,機器學習工程師的“工具”變得更加強大和穩定。
機器學習工程師們不再花時間用PyTorch或TensorFlow從頭開始構建模型,而是使用開源模型和遷移學習來構建產品,這意味著全新一代的機器學習驅動軟件即將面世。
現在,機器學習工程師只需要擔心如何將這些模型投入生產。
深度學習不再困難。