













關系型數據庫工作原理簡述

在我撰寫 High-Performance Java Persistence training 一書時,我逐步認識到讓讀者明白關系型數據庫工作原理會是了解如何構建高性能的 Java 持久化存儲的重要基石。不過關系型數據庫中的事務相關的重要概念:原子性、持久性以及檢查點等等也是相當繞人。而本文中我希望以相對高屋建瓴的方式來解釋關系型數據庫內部工作原理,也會涉及一些數據庫實現細節。
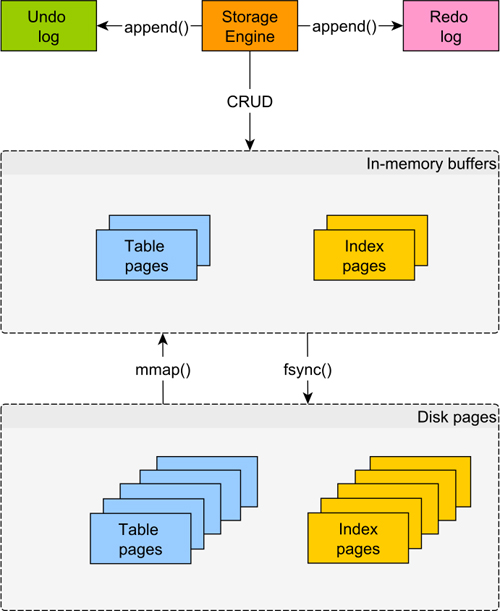
Data Pages
訪問磁盤中的數據往往速度較慢,換言之,內存中數據的訪問速度還是遠快于 SSD 中的數據訪問速度。基于這個考量,基本上所有數據庫引擎都盡可能地避免訪問磁盤數據。并且無論數據庫表還是數據庫索引都被劃分為了固定大小的數據頁(譬如 8 KB)。當我們需要讀取表或者索引中的數據時,關系型數據庫會將磁盤中的數據頁映射入存儲緩沖區。當我們需要修改數據時,關系型數據庫首先會修改內存頁中的數據,然后利用 fsync) 這樣的同步工具將改變同步回磁盤中。
Undo log
由于同時可能由多個事務并發地對內存中的數據進行修改,因此關系型數據庫往往需要依賴于某個并發控制機制(2PL 或者 MVCC)來保證數據一致性。因此,當某個事務需要去更改數據表中某一行時,未提交的改變會被寫入到內存數據中,而之前的數據會被追加寫入到 undo log 文件中。
Oracle 或者 MySQL 中使用了所謂 undo log 數據結構,而SQL Server 中則是使用 transaction log 完成此項工作。PostgreSQL 并沒有 undo log,不過其內建支持所謂多版本的表數據,即同一行的數據可能同時存在多個版本。總而言之,任何關系型數據庫都采用的類似的數據結構都是為了允許回滾以及數據的原子性。
如果當前運行的事務發生了回滾,undo log 會被用于重建事務起始階段時候的內存頁。
Redo Log
某個事務提交之后,內存中的改變就需要同步到磁盤中。不過并不是所有的事務提交都會立刻觸發同步,過高頻次的同步反而會對應用性能造成損傷。不過根據 ACID 原則,提交之后的事務必須要保證持久性,也就是即使此時數據庫引擎宕機了,提交之后的更改也應該被持久化存儲下來。這里關系型數據庫就是依靠 redo log 來達成這一點,它是一個僅允許追加寫入的基于磁盤的數據結構,它會記錄所有尚未執行同步的事務操作。相較于一次性寫入固定數目的數據頁到磁盤中,順序地寫入到 redo log 會比隨機訪問快上很多。因此,關于事務的 ACID 特性的保證與應用性能之間也就達成了較好的平衡。該數據結構在 Oracle 與 MySQL 中就是叫 redo log,而 SQL Server 中則是由 transaction log 執行,在 PostgreSQL 中則是使用 Write-Ahead Log( WAL )。
下面我們繼續回到上面的那個問題,應該在何時將內存中的數據寫入到磁盤中。關系型數據庫系統往往使用檢查點來同步內存的臟數據頁與磁盤中的對應部分。為了避免 IO 阻塞,同步過程往往需要等待較長的時間才能完成。因此,關系型數據庫需要保證即使在所有內存臟頁同步到磁盤之前引擎就崩潰的時候不會發生數據丟失。同樣地,在每次數據庫重啟的時候,數據庫引擎會基于 redo log 重構那些***一次成功的檢查點以來所有的內存數據頁。
總結
上面我們簡要討論的這些原則與考慮都是為了保證基于磁盤的存儲的較高吞吐量的同時保證數據一致性。其中,undo lo 主要用于提供原子性(允許回滾),而 redo log 則是保證磁盤頁的不可變性。
【本文是51CTO專欄作者“張梓雄 ”的原創文章,如需轉載請通過51CTO與作者聯系】


















