技術熱點:白話機器學習
從去年開始,陸陸續續學習了大半年的機器學習,現在是時候做個總結了。
在以往的編程經驗里面,我們需要對于輸入有一個精確的,可控制的,可以說明的輸出。例如,將1 + 1作為輸入,其結果就是一個精確的輸出 2 。并且不論怎么調整參數,都希望結果是2,并且能夠很清楚的說明,為什么結果是2,不是3。這樣的理念在傳統的IT界,非常重要,所有的東西就像時鐘一般精確,一切都是黑白分明的。由于這種嚴格的輸入輸出,衍生出很多對于程序的自動測試工具,你的程序無論怎么運行,都應該在相同輸入情況下,得到相同的,準確的,精確的輸出。
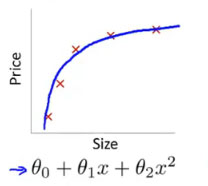
但是,如果你進入機器學習的世界,則一切都是基于一個準確率。換句話說,你的模型,允許是不***的,1 + 1,結果可以是 2.01,也可以是1.98。有時候,如果你的模型要追求***,則可能出現過擬合的可能性。也就是說,由于你的模型太過于***,使得模型可以很好的匹配訓練用數據,反而失去了通用性,在數據發生變化的時候,發生錯誤。
舉個例子來說吧,如果一個男孩子說喜歡某個女孩子,這個女孩子身高178,籍貫是遼寧撫順,專業是計算機。如果機器學習發生過擬合的時候,它就會輸出這樣一個模型
如果 身高 = 178 ,籍貫 = 撫順 ,專業 = 計算機 則喜歡。
這個模型如果用來匹配一個個例,則這個模型是***的!
但是,如果這個女孩子身高是179呢,這個模型會告訴你,這個男孩子不喜歡她。其實,對于男孩子來說,178和179其實沒有什么很大的區別。但是由于計算機想精確給出男孩子喜歡女孩子的模型,所以,計算機做出了過擬合的模型。
當然,一般來說,計算機的模型應該是有彈性的。
身高在 【175,185】之間
籍貫是 東北
專業是 IT相關的
這樣的話,模型雖然會把一些男孩子不喜歡的女孩子也錯誤的標識出來,但是大部分的樣本還是可以比較好的預測出來的。
機器學習追求的不是100%的正確,而是一個可以容忍的正確率。
當然,在某些時候,還需要一些風險策略的,例如,在人工智能判斷一個用戶是否能夠發給信用卡的時候,并不是說,這個人51%的可能性是一個講信用的人,就發卡,而是這個人95%是講信用的人的時候,才發卡的。機器給出的只是一個估計值,***還是要人工控制風險的。
機器學習,很多人認為是一個高科技的IT技能,其實,一個好的機器學習模型,領域里的業務知識還是很需要的。而且現在很多工具可以幫助大家建立程序,完全不需要什么編程的技能,只需要給機器“喂”數據,調節參數,就可以獲得結果了。
給機器“喂”什么數據,那些數據的特征值是有用的,那些特征值沒有價值,這個就是領域專家思考的問題了。
男孩子喜歡女孩子,這時候 顏值,身材,脾氣 可能是比較關鍵的特征值,喜歡可口可樂還是百事可樂則變得基本沒有什么價值。如果你的數據里面,都是女孩子喜歡那個牌子的可樂,這樣的數據訓練出來的模型沒有任何意義。當然,如果你有很多特征值,還是有一些自動化的計算幫你挑選用那些特征值的(主成因分析)。
在機器學習中,有一些復雜的概念,往往都是由一個簡單的概念擴展開來的。
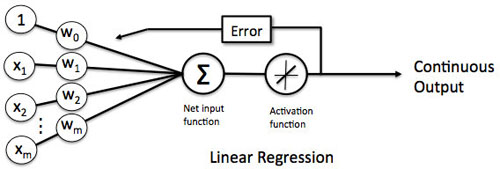
卷積神經網絡為首的一些神經網絡的概念,都是從感知機這個小家伙來的。
感知機的輸出,是由輸入和權重決定的,在監督學習中,輸入和輸出是已知的,然后機器學習通過不停的調整權重,使得感知機的輸出(模型)和實際的輸出(樣本)盡量一致。這個過程中,學習結果就是這些權重,權重知道了,模型就定下來了。一個最簡單的感知機的應用就是線性單元。
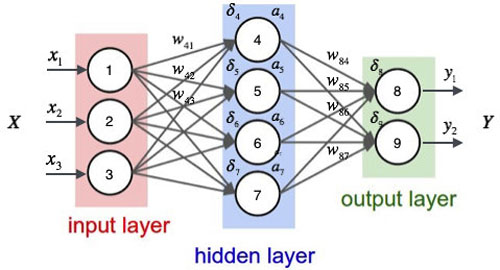
單個感知機是弱小的,但是,如果感知機有成千上萬個,然后一層一層一層疊加起來呢。。這些小家伙就變成強大的神經網絡了
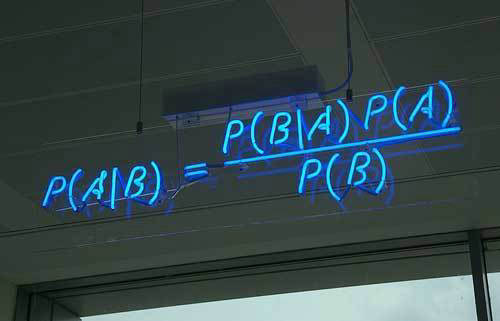
貝葉斯,馬爾科夫同志則共享了很多關于概率的機器學習。
貝葉斯***貢獻如下。
在“你家隔壁住著老王(B)”的前提下,“你的孩子長得像隔壁老王(A)”的概率
等于“你的孩子長得像隔壁老王(A)”的前提下,“你家隔壁住著老王(B)”
乘以:“你的孩子長得像隔壁老王(A)”的概率(和隔壁是否住著老王無關)
除以:“你家隔壁住著老王(B)”的概率
當然這個正統說法要牽涉到先驗概率,后驗概率。
從最簡單的伯努利分布,到關于分布的分布的變態級別的狄利克雷分布,很多機器學習都在追求模型***抽樣的分布概率。換句話說,就是希望從概率學上看,我們做出來的模型,和我們看到的樣本之間,看上去是最相似。(***似然)
例如,我們要做一個模型,表示拋一枚硬幣有多大概率正面向上。如果我們的樣本告訴我們,10次里面,有7次正面向上,則我們說這枚硬幣70%會出現正面向上。這個模型的結論和樣本之間,從概率學上看是最有可能的。
我們做的模型,就是追求和實際樣本的結果,在概率學上看,是最有可能發生的情況。
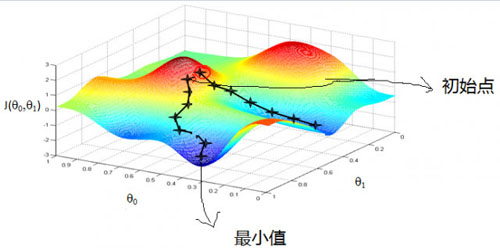
最快梯度下降則幾乎出現在所有的迭代算法中。
為什么梯度下降特別重要,因為大部分的算法都是盡可能將損失函數降低,怎么才能將損失函數降低,就是不停調整參數(權重),權重調整的方向,和梯度下降的方向是一致的。當然,最快梯度下降有可能不會收斂到全局***點。(能否收斂到全局***點,和初始位置有關)
機器學習和自然語言處理也是密不可分的。在很多自然語言處理中,將大量使用機器學習的概念。馬爾可夫鏈和條件隨機場,狄利克雷分布這些都是自然語言處理的基礎理論。