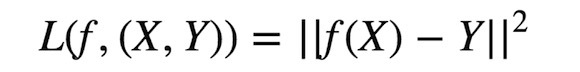機器學習技術之什么是集成學習?
譯文【51CTO.com快譯】集成學習是功能強大的機器學習技術之一。集成學習通過使用多種機器學習模型來提高預測結果的可靠性和準確性。但是,使用多種機器學習模型如何使預測結果更準確?可以采用什么樣的技術創建整體學習模型?以下將探討解答這些問題,并研究使用集成模型的基本原理以及創建集成模型的主要方法。
什么是集成學習?
簡而言之,集成學習是訓練多個機器學習模型并將其輸出組合在一起的過程。組織以不同的模型為基礎,致力構建一個最優的預測模型。組合各種不同的機器學習模型可以提高整體模型的穩定性,從而獲得更準確的預測結果。集成學習模型通常比單個模型更可靠,因此,它們經常在許多機器學習競賽中獲勝。
工程師可以使用多種技術來創建集成學習模型。而簡單的集成學習技術包括平均不同模型的輸出結果,同時還開發了更復雜的方法和算法,專門用于將許多基礎學習者/模型的預測結果組合在一起。
為什么要使用集成訓練方法?
出于多種原因,機器學習模型可能會彼此不同。不同的機器學習模型可以對總體數據的不同樣本進行操作,可以使用不同的建模技術,并且使用不同的假設。
想象一下,如果你加入由不同專業人員組成的團隊,那么肯定會有一些你知道和不知道的技術,假設你正在和其他成員一起討論一個技術主題。他們也像你一樣,只對自己的專業有所了解,而對其他專業技術一無所知。但是,如果最終能將這些技術知識組合在一起,將會對更多領域有更準確的猜測,這是集成學習的原理,也就是結合不同個體模型(團隊成員)的預測以提高準確性,并最大程度地減少錯誤。
統計學家已經證明,當一群人被要求用一系列可能的答案來猜測一個給定問題的正確答案時,他們所有的答案都會形成一個概率分布。真正知道正確答案的人會自信地選擇正確的答案,而選擇錯誤答案的人會將他們的猜測分散到可能的錯誤答案范圍內。例如玩一個猜迷游戲,如果你和兩個朋友都知道正確的答案是A,那么你們三個人都會選A,而團隊中其他三個不知道答案的人很可能會錯誤地猜測是B、C、D或E,其結果是A有三票,其他答案可能只有一到兩票。
所有的模型都有一定的誤差。一個模型的誤差將不同于另一個模型產生的誤差,因為模型本身由于上述原因而不同。當檢查所有的錯誤時,它們不會聚集在某一個答案周圍,而是廣泛分布。不正確的猜測基本上分散在所有可能的錯誤答案上,并相互抵消。與此同時,來自不同模型的正確猜測將聚集在正確的答案周圍。當使用集成訓練方法時,可以找到更可靠的正確答案。
簡單的集成訓練方法
簡單的集成訓練方法通常只涉及統計集成技術的應用,例如確定一組預測的模式、平均值或加權平均值。
模型是指一組數字中出現頻率最高的元素。為了得到這個模型,各個學習模型返回他們的預測,這些預測被認為是對最終預測的投票。通過計算預測的算術平均值(四舍五入到最接近的整數)來確定預測的平均值。最后,可以通過為用于創建預測的模型分配不同的權重來計算加權平均值,其中權重代表該模型的預測重要性。將類別預測的數值表示與權重(從0到1.0)相乘,然后將各個加權的預測相加在一起,并將其結果進行四舍五入,從而得出最接近的整數。
高級集成訓練方法
現在有三種主要的高級集成訓練技術,每種技術都旨在解決特定類型的機器學習問題。 “裝袋”(Bagging)技術用于減少模型預測的方差,方差是指當基于相同的觀察結果時預測的結果相差多少。使用“提升”(Boosting)技術來消除模型的偏差。最后,通常使用“堆疊”(Stacking)來改善預測結果。
集成學習方法通常可以分為兩類:順序集成方法和并行集成方法。
順序集成方法的名稱為“順序”,因為基礎學習器/模型是順序生成的。在順序集成方法的情況下,基本思想是利用基礎學習者之間的依賴關系來獲得更準確的預測。標簽錯誤的示例將調整其權重,而標簽正確的示例將保持相同的權重。在每次生成新的學習者時,權重都會改變,其準確性將會提高。
與順序集成模型相反,并行集成方法將會并行生成基礎學習器。在進行并行集成學習時,可以利用基礎學習器具有獨立性這一事實,因為可以通過平均每個學習器的預測值來降低總體錯誤率。
集成訓練方法可以是同質的,也可以是異質的。大多數集成學習方法是同質的,這意味著它們使用單一類型的基本學習模型/算法。與其相反,異構集成使用不同的學習算法,使學習者多樣化,以確保盡可能高的準確性。
集成學習算法的示例
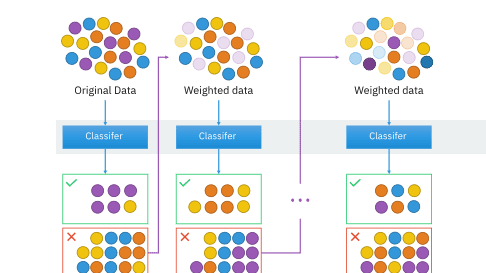
集成提升的可視化
順序集成方法的示例包括AdaBoost、XGBoost和Gradient tree boosting。這些都是提升升模型。對于這些提升模型,目標是將表現欠佳的弱勢學習者轉變為功能強大的學習者。像AdaBoost和XGBoost這樣的模型從許多弱勢學習者開始,這些學習者的表現比隨機猜測要好一些。隨著訓練的繼續,將權重應用于數據并進行調整。在較早的培訓中被學習者錯誤分類的實例將具有更大的權重。在為所需的訓練回合次數重復此過程之后,通過加權和(對于回歸任務)和加權投票(對于分類任務)將預測合并在一起。

裝袋學習過程
并行集成模型的一個示例是隨機森林分類器,并且隨機森林也是裝袋技術的一個示例。 “裝袋”這個術語來自“引導聚合”。使用稱為“自舉抽樣”的抽樣技術從總數據集中抽取樣本,基本學習者使用這些技術進行預測。對于分類任務,基本模型的輸出使用投票進行聚合,而對于回歸任務則將它們進行平均。隨機森林使用單獨的決策樹作為基礎學習者,并且集合中的每個決策樹都是使用來自數據集的不同樣本構建的。特征的隨機子集也用于生成決策樹。導致高度隨機化的個體決策樹,這些決策樹全部組合在一起以提供可靠的預測。
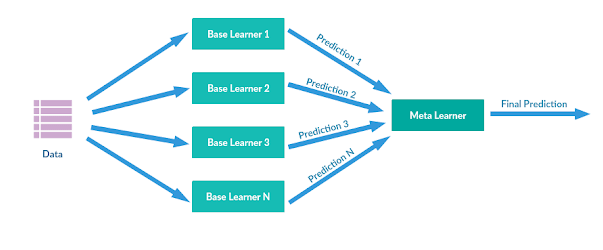
堆疊集成可視化
在堆疊集成技術方面,多元回歸或分類模型通過更高級別的元模型組合在一起。較低級別的基本模型通過輸入整個數據集進行訓練。然后將基本模型的輸出作為訓練元模型的功能。堆疊集成模型在本質上通常是異質的。
原文章標題:What is Ensemble Learning?,作者:Daniel Nelson
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】