支付風控之模型分析
接上一篇支付風控數據倉庫建設。支付風控涉及到多方面的內容,包括反洗錢、反欺詐、客戶風險等級分類管理等。 其中最核心的功能在于對實時交易進行風險評估,或者說是欺詐檢測。如果這個交易的風險太高,則會執行攔截。由于反欺詐檢測是在交易時實時進行的,在要求不能誤攔截的同時,還有用戶體驗上的要求,即不能占用太多時間,一般要求風控操作必須控制在100ms以內,對于交易量大的業務,10ms甚至更低的性能要求都是必須的。 這就需要對風控模型進行合理的設計。一般來說,要提升風控的攔截效率,就需要考慮更多的維度,但這也會帶來計算性能的下降。在效率和性能之間需要進行平衡。
本文重在介紹建立風控模型的方法,每個公司應該根據自己的實際業務情況和開發能力來選擇合適的模型。這里列出來的模型僅為了說明問題,提供參考。
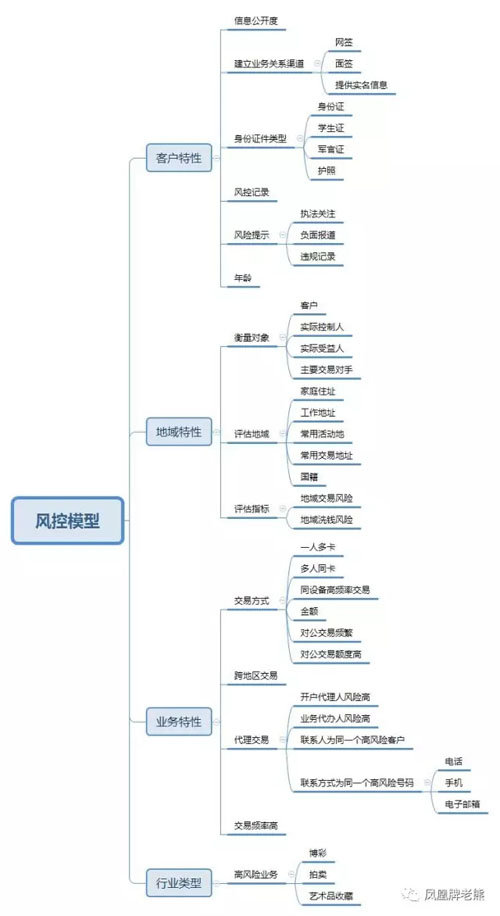
一、風險等級
做風控攔截,首先要回答的問題是風險等級怎么劃分? 目前主流的風險等級劃分有三種方式, 三等級、四等級、五等級。
- 三等級的風險分為 低風險、中風險和高風險。 大部分交易是低風險的,不需要攔截直接放行。 中風險的交易是需要進行增強驗證,確認是本人操作后放行。 高風險的交易則直接攔截。
- 四風險等級,會增加一個中高風險等級。此類交易在用戶完成增強驗證后,還需要管理人員人工核實,核實沒問題后,交易才能放行。
- 五風險等級,會增加一個中低風險等級。此類交易是先放行,但是管理人員需要進行事后核實。 如果核實有問題,通過人工方式執行退款,或者提升該用戶的風險等級。
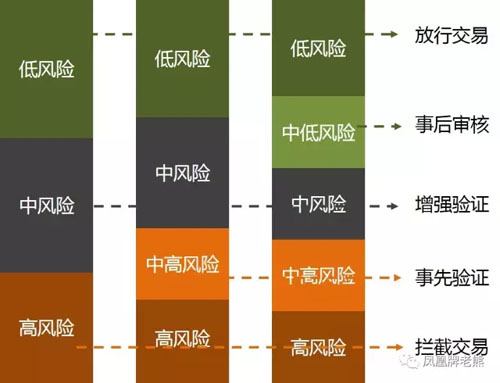
大部分支付系統是使用三等級的風險。
二、基于規則的風控
規則是最常用的,也是相對來說比較容易上手的風控模型。從現實情況中總結出一些經驗,結合名單數據,制定風控規則,簡單,有效。 常見的規則有:
1. 名單規則
使用白名單或者黑名單來設置規則。具體名單如上文所述,包括用戶ID、IP地址、設備ID、地區、公檢法協查等。 比如:
- 用戶ID是在風控黑名單中。
- 用戶身份證號在反洗錢黑名單中。
- 用戶身份證號在公檢法協查名單中。
- 用戶所使用的手機號在羊毛號名單列表中。
- 轉賬用戶所在地區是聯合國反洗錢風險警示地區。
2. 操作規則
對支付、提現、充值的頻率按照用戶賬號、IP、設備等進行限制,一旦超出閾值,則提升風控等級。
- 頻率需綜合考慮(五)分鐘、(一)小時、(一)天、(一)周等維度的數據。由于一般計算頻率是按照自然時間段來進行的,所以如果用戶的操作是跨時間段的,則會出現頻率限制失效的情況。 當然,比較復雜的可以用滑窗來做。
- 對不同的風險等級設置不同的閾值。 比如:
- 用戶提現頻次5分鐘不能超過2次, 一小時不能超過5次,一天不能超過10次。
- 用戶提現額度一天不能超過1萬。
- 用戶支付頻次5分鐘不能超過2次,一小時不能超過10次,一天不能超過100次。
3. 業務規則
和特定各業務相關的一些規則,比如:
- 同一個人綁定銀行卡張數超過10張。
- 同一張銀行卡被超過5個人綁定。
- 同一個手機號被5個人綁定。
- 一個周內手機號變更超過4次。
- 同一個對私銀行卡接受轉賬次數一分鐘超過5次。
4. 行為異常
用戶行為和以前的表現不一致,比如:
- 用戶支付地點與常用登錄地點不一致
- 用戶支付使用個IP與常用IP地址不一致
- 用戶在短時間內,上一次支付的地址和本次支付的地址距離非常遠。 比如2分鐘前在中國支付的,2分鐘后跑到美國去支付了。
5. 風控攔截歷史規則
用戶在某個業務上的消費行為被風控網關多次攔截。
規則引擎優點:
- 性能高: 對訂單按照規則進行匹配,輸出結果。一般不會涉及到復雜的計算。
- 易于理解和分析: 交易被攔截到底是觸犯了那條規則,很容易輸出。
- 開發相對簡單。
規則引擎存在的問題:
- 一刀切,容易被薅羊毛的人嗅探到。比如規則規定超過5000元就進行攔截,那羊毛號會把訂單拆分成4999元來做。 一天限制10筆,那就薅到9筆就停手了。
- 規則沖突問題。當一筆交易命中IP白名單和額度黑名單的時候應該如何處理?
規則引擎看起來簡單,但也是最實用的一類模型。 它是其它風控模型的基礎。實踐中,首先使用已知的規則來發現存在問題的交易,人工識別交易的風險等級后,把這些交易作為其它有監督學習的訓練數據集。
三、決策樹模型
風險評估從本質上來說是一個數據分類問題。 和傳統的金融行業風險評估不一樣的地方,在于數據規模大、業務變化快、實時要求高。一旦有漏洞被發現,會對公司造成巨大損失。 而機器學習是解決這些問題的利器。 互聯網金融風控離不開機器學習,特別是支付風控。 在各種支付風控模型中,決策樹模式是相對比較簡單易用的模型。 如下的決策樹模型,我們根據已有的數據,分析數據特征,構建出一顆決策樹。當有一筆交易發生時,我們使用決策樹來判斷這筆交易是否是高風險交易。
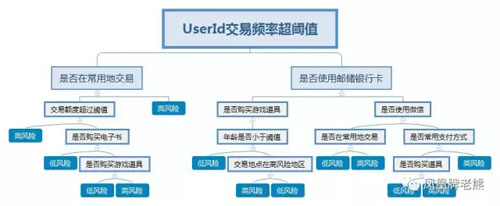
這種模型的優點是非常容易理解,檢測速度快。 因而也是現有機構中常用的模型之一。 風控模型存在的主要問題是其產生的結果比較粗略。同樣的兩個交易被判定為高風險,究竟哪種交易風險更高,決策樹模型無法給出答案。
四、評分模型
比決策樹模型更進一步,現在也有不少公司在使用評分(卡)模型。 銀行在處理信用風險評級、反洗錢風險等級時,往往也是使用這種方法。
每個公司的模型都不一樣,一個參考模型如下:
該模型為參考《金融機構洗錢和恐怖融資風險評估及客戶分類管理指引》編制,僅具參考意義。雖然銀行間的評分模型有很好的參考價值,但互聯網公司由于業務和數據的不同,評分模型參考價值不大。
每個公司需根據自己的業務情況來制定評分模型,之后為各個指標指定權重比例。 權重評分結果為0~100分的區間,之后按照區間劃分,指定風險等級。比如:
![]()
當然,評分區間也需要根據企業的實際情況來制定。 評分模型的優勢在于:
性能比較高,針對交易進行指標計算,按照區間來確定風險。
相對于規則,如果指標設置合理,其覆蓋度高, 不容易被嗅探到漏洞。
理解和分析也比較容易。 如果交易被攔截了,可以根據其各項打分評估其被攔截的原因。
存在的問題:
- 模型真的很難建立。指標的選擇是一個挑戰。
- 各個參數的調優是一個長期的過程。
我們知道從一條交易記錄中可以挖掘的關聯數據有上百個,衍生數據就更多了。比如從支付地址,可以聚類出常用地址,衍生出當前地址和常用地址、上一次支付地址之間的距離,而這些指標在構建模型時都可能使用到。 所以第一個問題是,如何從這些指標中建立一個合適的模型?這就涉及到機器學習的問題了。 模型不能憑空建立,我們可以通過規則來對現有數據進行篩選和標注,確定這些記錄集的風險等級。 這些數據作為樣本來訓練模型。可用的算法包括Apriori、FP-growth等。算法實現請參考相關文檔。
在確認相關參數后,模型在使用過程中還需要不斷對相關參數進行調整。這是一個擬合或者回歸的算法,Logistic算法、CART算法,可以用來對參數做調優。
總之,模型的建立是一個不斷學習、優化的過程。 而每一個模型的發布,還需要進行試運行,AB測試和上線。 這個過程,將在下一篇的風控架構中介紹。
五、模型評估
風控本質上是對交易記錄的一個分類,所以對風控模型的評估,除了性能外,還需要評估“查全率”和“查準率”。 如下圖所示:
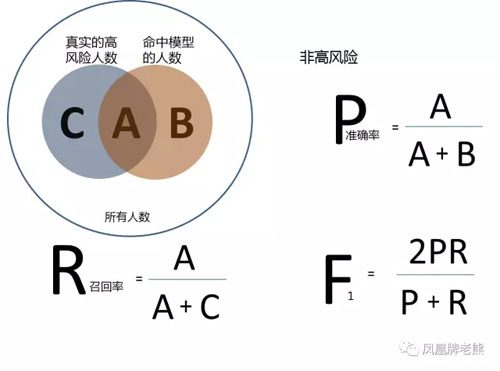
以評估高風險人群的效果為例,
- Precision, 準確率,也叫查準率,指模型發現的真實的高風險人數占模型發現的所有高風險人數的比例。
- Recall,召回率,也叫查全率,指模型發現的真實的高風險人數占全部真實的高風險人數的比例。
理想情況下,我們希望這兩個指標都要高。實際上,往往是互斥的,準確率高、召回率就低,召回率低、準確率高。如果兩者都低,那就是模型不靠譜了。 對于風控來說,需要在保證準確率的情況下,盡量提高召回率。 那怎么發現實際的高風險人數呢? 這就需要借助規則模型,先過濾一遍,再從中人工遴選。
從實際應用情況來看,目前國內大部分團隊使用Logistic回歸+評分模型來做風控,少數人使用決策樹。國外的PayPal是支付平臺風控的標桿,國內前海征信、螞蟻金服等會使用到更高級的神經網絡和機器學習,但實際效果未見到實證材料。
【本文為51CTO專欄作者“鳳凰牌老熊”的原創稿件,轉載請通過微信公眾號“鳳凰牌老熊”聯系作者本人】