













Hive map階段緩慢,優化過程詳細分析
背景
同事寫了這樣一段HQL(涉及公司數據,表名由假名替換,語句與真實場景略有不同,但不影響分析):
- CREATE TABLE tmp AS
- SELECT
- t1.exk,
- t1.exv,
- M.makename AS m_makename,
- S.makename AS s_makename,
- FROM
- (SELECT
- exk,
- exv
- FROM xx.xxx_log
- WHERE etl_dt = '2017-01-12'
- AND exk IN ('xxID', 'yyID') ) t1
- LEFT JOIN xx.xxx_model_info M ON (M.modelid=t1.exv AND t1.exk='xxID')
- LEFT JOIN xx.xxx_style_info S ON (S.styleid=t1.exv AND t1.exk='yyID')
任務運行過程中非常緩慢,同事反映說這個任務要跑一個多小時。初步問了下,xx.xxx_log表數據量在分區etl_dt = '2017-01-12'上大概1億3000萬,xx.xxx_model_info大概3000多,xx.xxx_style_info大概4萬多。
分析
***步,分析HQL語句著手
從同事提供的數據量上看,兩個left join顯然應該是mapjoin,因為數據量差距懸殊。當前只有HQL語句,所以優化***步當然要從HQL語句本身出發,看HQL語句是否有不恰當的地方。
從語句上看,就是取三張表的數據,按條件進行join,***創建并插入一張hive表。語句上看沒什么問題。
那就來看執行計劃吧~ 我們只看建表后面的SELECT語句,如下
- STAGE DEPENDENCIES:
- Stage-5 is a root stage
- Stage-4 depends on stages: Stage-5
- Stage-0 depends on stages: Stage-4
- STAGE PLANS:
- Stage: Stage-5
- Map Reduce Local Work
- Alias -> Map Local Tables:
- m
- Fetch Operator
- limit: -1
- s
- Fetch Operator
- limit: -1
- Alias -> Map Local Operator Tree:
- m
- TableScan
- alias: m
- Statistics: Num rows: 3118 Data size: 71714 Basic stats: COMPLETE Column stats: NONE
- HashTable Sink Operator
- filter predicates:
- 0 {(_col0 = 'xxID')} {(_col0 = 'yyID')}
- 1
- 2
- keys:
- 0 UDFToDouble(_col1) (type: double)
- 1 UDFToDouble(modelid) (type: double)
- 2 UDFToDouble(styleid) (type: double)
- s
- TableScan
- alias: s
- Statistics: Num rows: 44482 Data size: 1023086 Basic stats: COMPLETE Column stats: NONE
- HashTable Sink Operator
- filter predicates:
- 0 {(_col0 = 'xxID')} {(_col0 = 'yyID')}
- 1
- 2
- keys:
- 0 UDFToDouble(_col1) (type: double)
- 1 UDFToDouble(modelid) (type: double)
- 2 UDFToDouble(styleid) (type: double)
- Stage: Stage-4
- Map Reduce
- Map Operator Tree:
- TableScan
- alias: xx.xxx_log
- Statistics: Num rows: 136199308 Data size: 3268783392 Basic stats: COMPLETE Column stats: NONE
- Filter Operator
- predicate: ((exk) IN ('xxID', 'yyID')) (type: boolean)
- Statistics: Num rows: 22699884 Data size: 544797216 Basic stats: COMPLETE Column stats: NONE
- Select Operator
- expressions: exk (type: string), exv (type: string)
- outputColumnNames: _col0, _col1
- Statistics: Num rows: 22699884 Data size: 544797216 Basic stats: COMPLETE Column stats: NONE
- Map Join Operator
- condition map:
- Left Outer Join0 to 1
- Left Outer Join0 to 2
- filter predicates:
- 0 {(_col0 = 'SerialID')} {(_col0 = 'CarID')}
- 1
- 2
- keys:
- 0 UDFToDouble(_col1) (type: double)
- 1 UDFToDouble(modelid) (type: double)
- 2 UDFToDouble(styleid) (type: double)
- outputColumnNames: _col0, _col1, _col13, _col32
- Statistics: Num rows: 49939745 Data size: 1198553901 Basic stats: COMPLETE Column stats: NONE
- Select Operator
- expressions: _col0 (type: string), _col1 (type: string), _col13 (type: string), _col32 (type: string)
- outputColumnNames: _col0, _col1, _col2, _col3
- Statistics: Num rows: 49939745 Data size: 1198553901 Basic stats: COMPLETE Column stats: NONE
- File Output Operator
- compressed: false
- Statistics: Num rows: 49939745 Data size: 1198553901 Basic stats: COMPLETE Column stats: NONE
- table:
- input format: org.apache.hadoop.mapred.TextInputFormat
- output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
- serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
- Local Work:
- Map Reduce Local Work
- Stage: Stage-0
- Fetch Operator
- limit: -1
- Processor Tree:
- ListSink
執行計劃上分為三個stage,***個處理兩張小表的,把小表內容處理成HashTable來做mapjoin,這個跟我們上面的分析一致。第二個用于處理大表和小表的mapjoin,***一個則是關聯后的數據輸出。
從執行計劃上看,似乎也沒什么問題,一切很正常~~
既然從SQL本身找不到問題,那說明有可能出現在數據上或機器上,就只能具體問題具體看了。
第二步,查建表語句,看表的壓縮格式是不是不支持分割導致部分map任務處理時間過長
Hive支持多種壓縮格式,有的壓縮格式支持split,而有的并不支持,比如LZO。當不支持split的時候,數據塊有多大,Hive的map任務就得處理多大,而Hive表的分區數據有可能存在不均衡的現象,就會導致有的map快,有的map慢。當遇到LZO格式的時候,***的方式是建立索引,可以加快處理速度。
用show create table從建表語句里看,并沒有使用LZO的表。而在hdfs上直接查看三張表的文件大小,***的那張表加上條件后還有24個分區,每個分區的大小不一樣。但是由于任務有40個map,由此可知有些分區的數據是拆成了幾個map任務的,所以再一次證明是可切分的,排除不可切分導致的map任務問題。
第三步,分析任務運行狀況
找到運行完的任務,查看運行界面圖可以看到,map任務的時間長短不一,最短的1分鐘之內,最長的達半個多小時。
乍一看,好像是數據傾斜導致的,要確定是否數據傾斜,我們需要隨機挑幾個時間長的map任務,和時間短的map任務,看看各自的數據量和數據大小。
對比發現,數據量基本都在100萬到130之間,而數據大小也在100多MB左右(不能只看數據量,數據大小也很重要,防止空列這種數據傾斜情況)。
這樣一來,map端的數據傾斜其實是不存在的,所以map任務應該基本上是均衡的。那為什么時間上會相差這么大呢?
進而猜測,是不是因為某些慢的任務剛好被擠在某臺或某幾臺機器上,而剛好這幾臺機器負載重,所以比較慢?
到這里,我們統計下慢的幾個map任務都在什么機器上,統計完發現,果然最慢的十幾個任務集中分布在兩臺機器上,一臺機器大概六七個的樣子。按7個任務算,每個任務讀100多MB的文件,怎么說都在幾分鐘之內可以搞定吧,所以好像真的跟機器負載有關系~
所以機器這里我們也必須去看一看,看看是不是負載導致的。重新跑一下上面的任務,找到map慢的幾臺機器,做如下查看:
分別從CPU、內存、磁盤IO和網絡IO來看,這是服務器狀況查看的基本入口:
- top 命令可以輔助我們查看CPU的狀況,結果發現CPU平均負載不過50%
- iostat -x 5 命令可以輔助我們查看磁盤IO情況,我們發現請求數比較高但是平均等待隊列并不高,磁盤讀寫都跟得上,所以磁盤也不是問題
- sar -n DEV 5 命令可以輔助我們查看網絡IO的情況,服務器至少是千兆網卡,支持至少1Gb/s的速度,而從輸出來看,網絡遠遠不是問題
由此,我們排除了機器負載過高導致無法服務的問題,同時問了下同事,說是這個任務跑了好多次都這樣,好多次都這樣說明機器應該不是問題,因為機器隨機分,不可能每次都分到慢的機器上。所以說每次都map慢跟機器無關,而是我們SQL的問題。
第四步,再觸SQL,分段分析
上面的分析已經確認跟機器無關,與數據不可分割也無關,而執行計劃上看也沒什么問題。那么只好一段一段的來看SQL了。
1、兩張小表是要分發到各節點的,所以不考慮,我們按條件讀一次大表的數據,統計下行數
- SELECT COUNT(1)
- FROM xx.xxx_log
- WHERE etl_dt = '2017-01-12'
- AND exk IN ('xxID', 'yyID')
結果發現時間只花了2分鐘左右,說明SQL不慢在這里。只能慢在join兩張小表上了,而小表join是mapjoin,理論上應該不慢才對。
2、考慮只join一張表來看 先選表xx.xxx_model_info
- SELECT COUNT(1)
- from (
- SELECT
- t1.exk,
- t1.exv,
- M.makename AS m_makename
- FROM
- (SELECT
- exk,
- exv
- FROM xx.xxx_log
- WHERE etl_dt='2017-01-12'
- AND exk IN ('xxID', 'yyID') ) t1
- LEFT JOIN xx.xxx_model_info M ON (M.modelid=t1.exv AND t1.exk='xxID')) tmp
上面是跟3118的一張小表join,可以看到執行計劃是mapjoin,而執行時間則出乎意料,用了大概2分鐘,與單獨計算大表行數差不多。
由此可以想到,mapjoin很慢應該與另一張表有關系,我們下面再執行跟另一張表join的情況,如果還是這么快,那說明兩個同時mapjoin在Hive上可能存在缺陷,而如果很慢,則說明mapjoin只跟那張小表有關系。
再選表xx.xxx_style_info
- SELECT COUNT(1)
- from (
- SELECT
- t1.exk,
- t1.exv,
- S.makename AS s_makename
- FROM
- (SELECT
- exk,
- exv
- FROM xx.xxx_log
- WHERE etl_dt='2017-01-12'
- AND exk IN ('xxID', 'yyID') ) t1
- LEFT JOIN xx.xxx_style_info S ON (S.styleid=t1.exv AND t1.exk='yyID') ) tmp
這下執行結果奇慢無比,map階段進展很緩慢。由此說明大表與這張小表的mapjoin存在問題,可是mapjoin為啥還存在問題呢? 問題又在哪呢?
第五步,仍不放棄執行計劃
當看到上面問題的時候,一頭霧水,所以著重再看執行計劃是一個不錯的方案。很容易想到,同是兩個數據量相差不大的小表,mapjoin的運行速度為什么會不一樣?是字段類型導致join連接出問題?
當我們仔細再去看最上面的執行計劃的時候,我們會發現我們之前忽視的一個細節,那就是執行計劃里有UDFToDouble這個轉換,很奇怪我們并沒有調用這樣的UDF啊,怎么會有這樣的轉換呢? 唯一的解釋只能是join字段匹配。
我們查一下join字段發現,大表的exv字段是string類型,兩個小表的關聯字段都是int型,它們在join的時候,居然都先轉成了double型??? 這是什么鬼? 難道不應該都往string類型轉換,然后再join嗎?
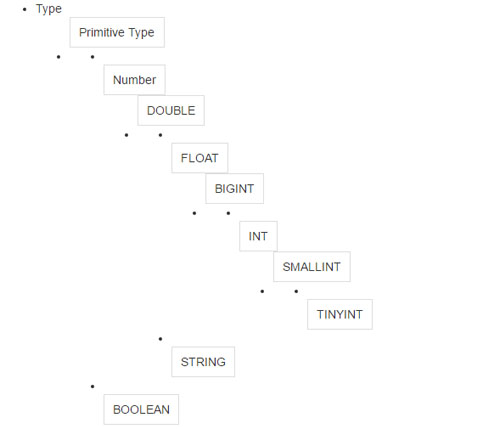
查下Hive官網才發現,類型關系是醬紫的...
![]()
double類型是string類型和int類型的公共類型,所以它們都會往公共類型上轉!
實際寫SQL中,也強烈建議自己做類型匹配的處理,不要拜托給解析器,不然問題很嚴重。
我們把小表的int類型轉換為string類型再做上面第二張表的join,如下:
- SELECT COUNT(1)
- from (
- SELECT
- t1.exk,
- t1.exv,
- S.makename AS s_makename
- FROM
- (SELECT
- exk,
- exv
- FROM xx.xxx_log
- WHERE etl_dt='2017-01-12'
- AND exk IN ('xxID', 'yyID') ) t1
- LEFT JOIN xx.xx_style_info S ON (cast(S.styleid as string)=t1.exv AND t1.exk='yyID') ) tmp
結果符合預料,2分鐘左右的時間可以完成這個SQL任務。而當整個任務也這么改之后,任務跑完也只要幾分鐘!
由此可見,事情都因細節而起!做join操作的時候,寫SQL的人其實是最清楚字段類型的,做上字段類型匹配小菜一碟,可以避免很多問題!!!
第六步,解開謎團
到這里,我們這個Hive任務的問題已經找到,那就是join兩邊key的數據類型不對,導致兩邊的數據類型都要向上做提升才能關聯。
但其實還是有問題的,上面第四步的實驗提到,當用大表與3118條數據的小表xx.xxx_model_info進行關聯的時候,很快可以出結果。但是當用大表與另一張小表xx.xxx_style_info進行關聯時,卻發現奇慢無比,也即問題跟它有很大關系。大表無論與哪張小表關聯,都要做類型提升,兩張小表的數據量相比大表而言,其實相差不大,但為啥數據量稍大的小表關聯就出問題呢?
我們單獨對三張表做類型轉換,轉為double類型,結果發現三張表的類型轉換都很快,并不存在因為數據不同導致轉換速度不一樣的情況,由此排除是類型提升時出的問題。因而問題最有可能出現在MapJoin身上!
在MapJoin階段,會把小表的內容加載到內存中,使用容器HashMap做存儲,然后對大表的關聯列進行掃描,每掃描一行都會去查看HashMap中有沒有對應的關聯列。這樣做起來其實是很快的,同時在Map端也減少了大量數據輸出到Reduce端。
HashMap不允許key有重復,在Hive里,如果key有重復怎么辦呢?顯然是不能把重復數據直接覆蓋的,因為key重復不代表value里的其他列也是重復的。這時Hive會把小表的存儲由HashMap降級為LinkedList,而HashMap里key是否重復由key對應類型的hashcode和equals方法決定。
在MapJoin階段,double類型使用的是DoubleWriteable,它的hashcode實現是一個錯誤的實現,如下:
- return (int)Double.doubleToLongBits(value);
long轉為int會產生溢出,因此不同的value很可能得到相同的hashcode,hashcode碰撞非常明顯。
這個問題早在 Hadoop-12217 里被提到,因為他們在使用Hive的時候碰到了和我相同的問題,就是類型提升為double時出現MapJoin異常緩慢的情況。其描述如下:
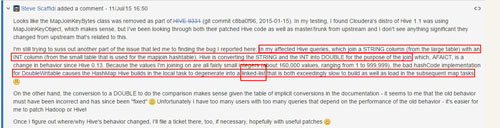
其patch里提到正確的更改方式如下:
- long dblBits = Double.doubleToLongBits(value);
- return (int) (dblBits ^ (dblBits >>> 32));
不過這個bug目前并未修復(當前版本:Hadoop 2.6.0-cdh5.5.1, Hive 1.1.0-cdh5.5.1),由于它導致我們數據量稍大的那張小表在MapJoin階段由HashMap轉為了LinkedList,因此數據掃描及其緩慢。而另一張3118條數據的小表,則剛好不存在hash code碰撞的問題,所以Map Join很快。
所以,最終的問題就在于此,所有的表象皆由它引起。***的解決辦法是在Join之前先做轉換,讓join時的鍵關聯保持類型一致并不為double類型即可。這個需要在寫HQL時時常注意,問題雖小,但是要找到它確實不容易,很是花時間。










