神經圖靈機深度講解:從圖靈機基本概念到可微分神經計算機
")
嗨,大家好,我是 Talla 公司的高級數據科學家 Daniel Shank,今天我要談談一個新的振奮人心的機器學習架構,它被稱為神經圖靈機(Neutral Turing Machine/NTM)。

首先,我要對這個架構做一個總體的概述,即這個架構是什么?然后我會開始討論為何說這個架構是重要的,以及它是如何與未來的機器學習相關的,再然后,我會談為什么我們不能馬上在每個地方用到這些東西。例如,假如它非常有作用,那為何我們不將它立即用在產品中。***我會討論最近發表在 Nature 上的神經圖靈機(Neutral Machine)的論文以及它后續的架構,并且我會展示對這個模型的一些有趣的擴展。
的論文")
為什么我們要關心神經圖靈機?為了解釋神經圖靈機為何如此重要,我們必須實實在在解釋一下普通的圖靈機(Turing machine)是什么。
是什么")
圖靈機就是一種簡單的計算機模型。正如現代計算機一樣,其思想中也包含了一個外部存儲器和某種處理器。本質上,圖靈機包含上面寫有指令的磁帶和能夠沿著磁帶讀取的設備。根據從磁帶上讀取到的指令,計算機能夠決定在磁帶上不同的方向上移動以寫入或者擦除新符號等等。
")
那什么又是神經圖靈機(Neural Turing Machine)呢?簡而言之,神經圖靈機就是一種神經網絡,但是它從圖靈機中獲得靈感來嘗試執行一些計算機可以解決得很好而機器學習模型并不能很好地解決的任務。本質上,它包括一個神經網絡控制器(controller)、讀取磁帶設備的模擬器或處理器,如果你愿意的話,還可以加上外部存儲或記憶(memory)。它在所有讀取到的輸入上都是持續的。就像長短期記憶(LSTM)網絡或者其他相關的模型一樣,它是一個循環神經網絡(recurrent neural network)。這意味著,像我們大多數人熟悉的一樣,它讀取類似變量的輸入,但是,神經圖靈機和圖靈機也有不同之處:除了有一個記憶/內存之外,神經圖靈機也可以接受一連串連續的輸入并提供輸出。
")
這里的關鍵思想是神經圖靈機基本上就是可微分的圖靈機,這是很重要的,因為我們每天在計算機上做的算法和事情對計算機來說是非常困難的,原因是計算機的計算是絕對的。要么是 0 要么是 1。計算機在「非此即彼」的邏輯或者整數中運作。然而大多數的神經網絡和機器學習實際上不是這樣的。它們使用實數。它們使用更加平滑的曲線,使得它們更加容易訓練,這意味著,在看到它們的輸出時,你可以輕易地通過輸出追蹤回去調整參數以得到希望的輸出。當計算機 CPU 盡是諸如異或門(XOR)和與門(AND)等跳變函數時,這是非常難以實現的。神經圖靈機采用了基本的圖靈機中的所有功能找到了平滑的模擬函數。因此,比如在磁帶上,神經圖靈機可以決定稍微向左或者向右移動,而不是單純的向左或者向右,這可以讓你完成一些了不起的事情
")
在神經圖靈機能夠執行的事情中,我們有一些激動人心的例子,當然也有一些不那么令人激動的......

但是缺點是它只能夠學習簡單的算法。例如接受輸入并復制它。這看起來是極其平常的,但是對當前的神經網絡來說,這實際上是一件非常困難的事情,因為神經網絡需要學習出一個算法才能把這個工作做得足夠好。神經圖靈機能夠接受輸入和輸出,并且學習得到能夠從輸入映射到輸出的算法。這確實相當令人興奮,因為這本質上是在嘗試著取代程序員。雖然我們還未實現,但是這的確很酷。這意味著一旦習得了算法,它們可以接受輸入并且外推到基于該算法的任何變量輸出。接下來你會立即明白這為什么很酷。因為它們還非常擅長語言建模(language modeling)。如果你不知道什么是語言建模,你可以思考一下自動完成(autocomplete)。語言建模就是猜測一個單詞在句子或者文檔語境中的意思。神經圖靈機也能夠在 Facebook 的 bAbI 數據集上表現得很有前景,bAbI 數據集是被設計用來鼓勵研究者們提升神經網絡的通用認知推理能力的。

在復制/重復任務上的泛化
這是一個神經圖靈機執行復制/重復任務的例子。它已經學會了接受相對短的序列,并重復幾次。正如你可以在上圖看到的一樣,開始的時候它犯錯。但是最終看起來相當好,圖中上邊的是目標,下邊的是輸出。

神經圖靈機的表現超越了長短時記憶網絡
相反,你拿這個例子與長短時記憶網絡(LSTM)相比,LSTM 實際上是一種非常強大的神經網絡模型。它們會很快就傾向于崩潰。出現這種情況的原因是,LSTM 確實是在學習一些東西,但是它們并不是在學習算法。LSTM 試圖一次解決整個問題,所以它們意識不到前兩次所做的事情就是它們之后應該做的。

平衡括號表達式
在神經圖靈機可以做到的事中,一個有趣的例子是它們可以識別平衡的括號。這個是特別有趣的,因為這涉及到的使用了棧(stack)的算法,所以本質上你可以隨著左括號的進入去跟蹤它們,然后嘗試去匹配與之對應的右括號。這件事神經網絡可以做,但是會以更加統計的方式完成,而神經圖靈機實際上可以像人類程序員一樣去完成這個任務。

好了,現在我們談一下 bAbI 數據集以及為什么我們如此關注它。bAbI 數據集本質上是一系列后面帶有問題的故事,而且所有的問題都被設計成需要某種形式的推理能力才能回答。我這里有一個簡單的例子——使用位置來進行推理。這里的關鍵點是,如果你問某人在哪里,實際上問的是他們***去了哪里。這看起來非常明顯,當涉及到人物撿起東西或者行走時,這個問題實際上會變得有些復雜。故事也會涉及到關于物體相對尺寸的實際推理。基本上,這件事情背后的基本理念永遠是,一個在所有這種任務中表現良好的系統,接近一個更加通用的知識推理系統。

bAbI 數據集上的結果
這里僅僅是一些基于 bAbI 數據集的結果。注意,實際上 bAbI 數據集是訓練集。就像我之前給你展示的,給定其中的每一個故事,你會看到的是,訓練集實際上提供了一個提示,這涉及到實際故事中的什么內容對回答問題是重要的。事實證明,導致這個問題非常困難的原因,不僅是你必須做出邏輯推理,你還必須意識到什么東西是相關的。你會看到,這兩者之間是存在競爭的。bAbI 數據集的許多子任務或者子部分都達到了超過 95% 的準確率,這作為系統通過給定領域的基準測試。

挑戰和建議
神經圖靈機可以做這些炫酷的事情:它們可以學會算法,它們可以理解一個小故事的意思,但是為什么我們不能一直用這些東西呢?嗯,它們的結構是如此地有趣,但也伴隨著一些問題。

問題:
- 架構依賴;
- 大量的參數;
- 并不能從 GPU 加速中受益;
- 難以訓練
首先,一旦你指定了一般的架構,在實現它的時候仍然需要做出很多決策。例如,對于每一個給定的輸入或輸出單元,在給定的時間步長下你能夠讀取或者寫入多少向量?這些都很重要,它不僅僅是提高你的識別準確率的問題。如果你不能正確地做到這些,那它很有可能永遠都得不到一個合理的結果。參數的數量是極其大的,這會讓你的 RAM 壓力很大。這是機器學習中的一個重要部分,它們并不會受益于 GPU 加速,雖然正如我們所見,GPU 加速是機器學習中的重要一部分。原因是這是序列式的,很難并行化,因為它們當下所做的都是基于之前的輸入。很難將這些部分分解成容易的并行計算。它是很難訓練的,這一點和我剛才提到的所有問題都有所不同。

難以訓練:
- 數值不穩定性;
- 很難使用記憶(memory);
- 需要很好的優化;
- 實際中很難使用
它們往往具有很強的數值不穩定性。部分原因是實際中給它們設計的任務。因為它們是在學習算法,所以它們往往不會犯小錯誤,它們傾向于犯大錯誤。如果你在算法中犯了一個錯誤,那么所有的輸出結果都會是不正確的。這意味著,當你訓練它們的時候,它們總是很難找到需要的算法。如果喂給大量的數據,給予足夠的時間,大多數神經網絡都會得到一些結果。而神經圖靈機經常會卡住。大家知道,它們經常一遍又一遍地一味地產生那些經常重復的值。這是因為使用記憶是很困難的。他們不僅必須學會記住以后解決問題所需要的東西,還必須記住不要意外地忘記它,這一層要求額外地增加了復雜性。因此,為了解決這個問題,你最終會用一些循環神經網絡通用的巧妙的優化方法。但是為了讓這些方法起作用,你需要想盡一切辦法。所有的這些問題都讓神經圖靈機很難用在日常應用中。

有很多應對數學不穩定性的方法。非常通用的一個方法就是梯度裁剪(gradient clipping),尤其是在使用 LSTM 的時候。梯度裁剪的本質就是,無論我們怎么認為一個壞的結果由初始參數導致的,我們都要限制一下其改變的程度。這可以幫助我們避免在任何時候當我們得到壞結果的時候就去擦除一切參數。當機器犯錯時,我們不能完全丟掉已經學到的東西。

損失裁剪本質上是梯度裁剪的擴展。相同的基本思想就是,神經圖靈機會非常遠離它們的目標。就像損失函數的總值一樣,給我們能夠改變的參數總和設置一個上限。我們經常結合這兩種方法。基本上,我們需要把很多有效果的更改綁定到一個有不同含義的參數上面。

好了,實際上另一個有趣的方向是 Graves 的 RMSprop。RMSprop 實際上是常見的反向傳播算法的一個擴展,這個大家可能比較熟悉。反向傳播是如今訓練所有的神經網絡的關鍵。RMSprop 是一個用來平滑梯度的系統。所以,在有序的數據點中,本質上你所做的就是對任何給定參數的效果取一個平均值。Graves 的 RMSprop 實際上是這個方法的一個變體。它本質上是做一個運行估計的方差,而非僅僅取一個平均值。它標準化并且保證損失的極值在實際中不會衰減太多,或者不會把參數減小那么多。這是一個非常聰明的方法,它也非常有趣,因為為了解決這個問題,人們不得不通讀 Alex Graves 的一些論文。如果你僅僅實現普通的 RMSprop,它往往效果不佳。所幸,還有一些可以替代的優化方法。

說實在的,盡管為了找出哪一個方法能夠幫助你,你常常必須嘗試多個算法,但是 Adam 優化器確實是一個常用的優化方法,并且它還支持了如今的大多數機器學習框架。像 Graves 的 RMSprop 方法一樣,它基本上也是平滑梯度。這個方法有些復雜,所以我不會在這里討論它是如何起作用的。但是一般而言,它確實是一個不錯的備選方法。

另一件值得注意的事就是值的初始化,尤其是記憶。一些人確實利用了由快速訓練神經圖靈機所帶來的記憶偏差。但是一般來說,這實際上是他們的架構有問題的特點。因為初始記憶會讓以后的計算產生很大的偏差,所以如果你以一組壞的參數開始的話,它可以徹底毀掉整個模型。就像很多其他這種技術一樣,它們有助于提升通用神經網絡的性能。但是在這種情況下,如果你做得不正確,它很可能不會收斂,你將不會得到一個合理的結果,所以為了合理地優化,你必須頻繁地嘗試不同的參數值作為初始點。

另外一個方法,也是比較有趣的,那就是 curriculum learning,就是在開始的時候喂一些簡單的數據。你從序列開始,讓它學習復制一些東西到某一長度,比如說 5。當它可以把這個做得很好時,你再將長度增加到 10,然后再某一點,你達到了新的長度,比如說 20,然后在某一點你相當自信你可以將模型泛化,就像我們之前看到的,將復制序列的長度增大到 100 或者更大。

現在我要繼續討論最近的擴展。非常令人興奮,如果我沒有記錯的話,它是在幾個星期之前出現在 Nature 上的。它以一些有趣的方式擴展了神經圖靈機,并且幫助解決了一些問題。

可微分神經計算機(參見機器之心文章《DeepMind 深度解讀 Nature 論文:可微神經計算機》)或者最近的一些模型本質上就是經過一些修改的神經圖靈機。從某種程度來說,它們放棄了基于索引移動的尋址方式。我之前一直在講沿著記憶或者磁帶的移動。它們不再這樣做;它們嘗試基于它們看到的東西直接在記憶中搜索給定的向量。它們還有分配記憶和釋放記憶的能力,如果你曾經使用過某種低水平的編程語言的話,你就會理解這個。以同樣的方式,很難跟蹤記憶區域中的內容,所以你不會在編程中犯錯誤,這樣很容易將記憶中的某個區域標記為禁止訪問,因此你不會在以后意外地刪除它們,這有助于優化。它們也有那種將序列輸入序列進行本地記憶地能力。當神經圖靈機學習復制的時候,它們學習將所有地輸入按順序寫進記憶,并回到記憶地開頭將它們讀出來這個過程。在這種情況下,從某種程度來說它們擁有了某種形式的時間記憶(temporal memory),在瞬時記憶中它們可以回想起它們所做的上一件事,上一件事的上一件事,以此類推,這意味著它們可以遍歷由它們需要做的事組成地一個鏈表。
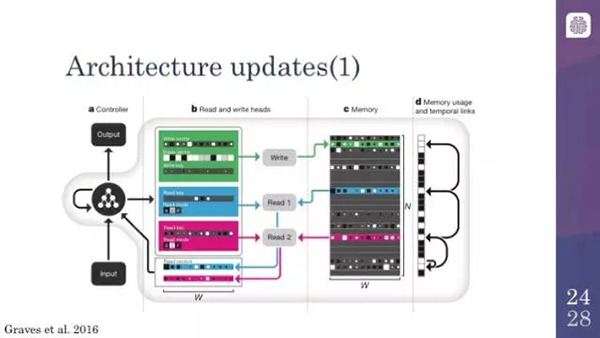
這是可微分神經計算機體系結構的總結。你們看到的左邊的圖表代表的是輸入和輸出變量的長度,然后讀頭和寫頭允許計算機在記憶區進行存取。這里你可以看到它一次讀入整個向量并在第 6 區域寫入。就像我之前描述過的,記憶區域在右邊有一個附加的暫時鏈接。如果你追蹤這些箭頭,你會看到實際上這些箭頭就是模型能夠回想并重復它最近的輸入和輸出的方式。

這里我們看到的圖片展示的是可微分計算機也在執行復制的任務。你看到的綠色的方塊是它寫入記憶中的東西,紫色的方塊是它從記憶中讀出來的內容。通常,當你給它輸入一些序列的時候,如果你沿著左邊看的話,你所看到的正在發生的事是計算機正在釋放某些區域的記憶,因為它需要寫入東西,所以這是在分配記憶,底部的方塊顯示了這個活動。然后,當寫入完成之后,輸出。然后,它就會說,「做好了,我們可以重新分配這塊記憶了」。你就會得到這種交替的模式,「我需要這塊記憶。好了,我做好了。我需要這塊記憶......」可微分神經計算機確實學會了做這件事,這使事情變得更加容易,讓這些事情變得更加有趣。
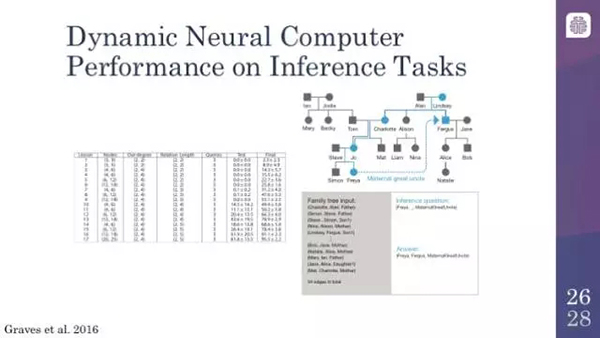
動態神經計算機在推理任務上的性能
我從為見過的讓計算機之間顯得有些不同的例子就是它們能夠做這種邏輯推理的事情,雖然是結合了某種模糊的推理。你在這里看到的是一個家族樹(family tree),用這個家族樹去訓練模型,本質上,「Mary 是 Jodie 的女兒」,或者「Simon 是 Steve 的兒子」。那么,你問計算機:「Freya 和 Fergus 是什么關系?」或者「Freya 和 Fergus 是什么關系?」答案是舅舅,所以它們確實是能夠回答這個問題的。如果你去讀這篇論文的話,你會發現一些有趣的例子,例如學會找最短路徑,橫穿倫敦地鐵系統的圖結構以及類似的東西,這些都是有趣的。我這里沒有相關的幻燈片,但是如果你對它很感興趣,強烈建議你讀一下 Nature 上的這篇文章,鏈接如下:http://www.nature.com/nature/journal/v538/n7626/abs/nature20101.html
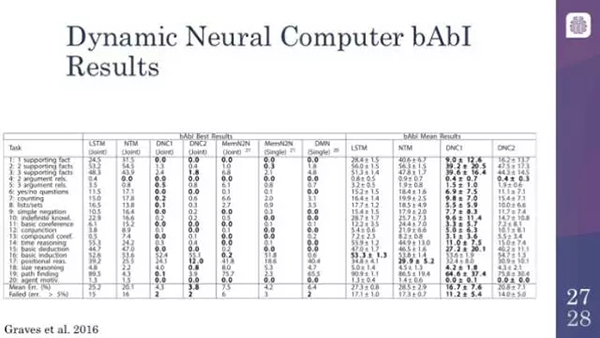
動態神經計算機在 bAbI 數據集上也有良好的表現。bAbI 數據集在過去一年左右有了很大的進步。實際上你會看到,除了少數幾個之外,大多數先進的模型都已經通過了 bAbI 數據集,而且做得相當好。你會看到,動態神經計算機(DNC)只在兩個領域沒有通過,其他的都通過了,而且還和可以 Facebook 的模型相媲美,Facebook 的模型被設計得非常好,因為這些數據集就是它們自己的數據集。這非常令人興奮,你可以說,只剩下不多的幾個領域需要攻克了,這是將神經網絡的學習任務向前推進的一大步,而之前我們是沒有能力去觸及這些任務的。

謝謝大家。這里有一些參考資料;我推薦 Theano、Lasagne 和 Go 的實現。我要推薦列表上的***一篇文章,這是一種使用更少的內存使這些東西工作的方式,越來越接近在實際產品中應用神經圖靈機的要求。
本文作者為 Talla 公司的高級數據科學家 Daniel Shank。他最近在舊金山舉辦的機器學習會議上發表了關于神經圖靈機的報告。
原文:http://blog.talla.com/neural-turing-machines-perils-and-promise
【本文是51CTO專欄機構機器之心的原創譯文,微信公眾號“機器之心( id: almosthuman2014)”】