主流開源SQL引擎總結,不斷改進的Hive始終遙遙領先
本文涵蓋了6個開源***:Hive、Impala、Spark SQL、Drill、HAWQ 以及Presto,還加上Calcite、Kylin、Phoenix、Tajo 和Trafodion。以及2個商業化選擇Oracle Big Data SQL 和IBM Big SQL,IBM 尚未將后者更名為“Watson SQL”。
(有讀者問:Druid 呢?我的回答是:檢查后,我同意Druid 屬于這一類別。)
使用SQL 引擎一詞是有點隨意的。例如Hive 不是一個引擎,它的框架使用MapReduce、TeZ 或者Spark 引擎去執行查詢,而且它并不運行SQL,而是HiveQL,一種類似SQL 的語言,非常接近SQL。“SQL-in-Hadoop” 也不適用,雖然Hive 和Impala 主要使用Hadoop,但是Spark、Drill、HAWQ 和Presto 還可以和各種其他的數據存儲系統配合使用。
不像關系型數據庫,SQL 引擎獨立于數據存儲系統。相對而言,關系型數據庫將查詢引擎和存儲綁定到一個單獨的緊耦合系統中,這允許某些類型的優化。另一方面,拆分它們,提供了更大的靈活性,盡管存在潛在的性能損失。
下面的圖1展示了主要的SQL 引擎的流行程度,數據由奧地利咨詢公司Solid IT 維護的DB-Engines 提供。DB-Engines 每月為超過200個數據庫系統計算流行得分。得分反應了搜索引擎的查詢,在線討論的提及,提供的工作,專業資歷的提及,以及tweets。
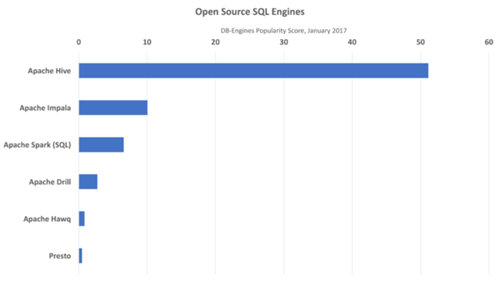
來源:DB-Engines,2017年1月 http://db-engines.com/en/ranking。
雖然Impala、Spark SQL、Drill、Hawq 和Presto 一直在運行性能、并發量和吞吐量上擊敗Hive,但是Hive 仍然是***的(至少根據DB-Engines 的標準)。原因有3個:
Hive 是Hadoop 的默認SQL 選項,每個版本都支持。而其他的要求特定的供應商和合適的用戶;
Hive 已經在減少和其他引擎的性能差距。大多數Hive 的替代者在2012年推出,分析師等待Hive 查詢的完成等到要自殺。然而當Impala、Spark、Drill 等大步發展的時候,Hive只是一直跟著,慢慢改進。現在,雖然Hive 不是最快的選擇,但是它比五年前要好得多;
雖然前沿的速度很酷,但是大多數機構都知道世界并沒有盡頭。即使一個年輕的市場經理需要等待10秒鐘來查明上周二Duxbury 餐廳的雞翅膀的銷量是否超過了牛肉漢堡。
在下面的圖2中可以看出,相對于領先的商業數據倉庫應用,用戶對***的SQL 引擎更感興趣。
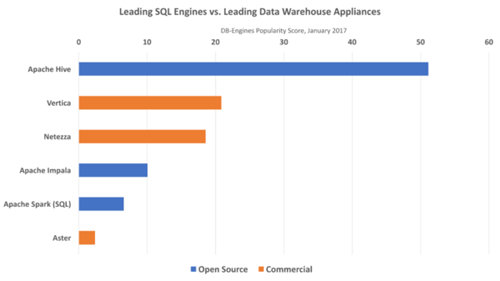
來源:DB-Engines,2017年1月 http://db-engines.com/en/ranking。
對于開源項目來說,***的健康度量是它的活躍開發者社區的大小。如下面的圖3所示,Hive 和Presto 有***的貢獻者基礎。(Spark SQL 的數據暫缺)
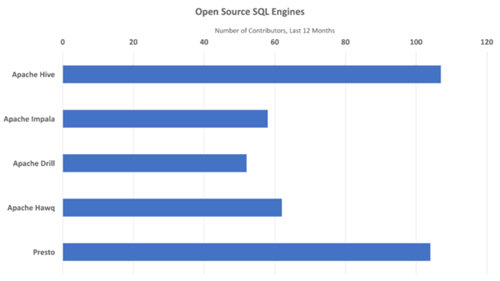
來源:Open Hub https://www.openhub.net/。
在2016年,Cloudera、Hortonworks、Kognitio 和Teradata 陷入了Tony Baer 總結的基準測試之戰,令人震驚的是,供應商偏愛的SQL 引擎在每一個研究中都擊敗了其他選擇,這帶來一個問題:基準測試還有意義嗎?
AtScale 一年兩次的基準測試并不是毫無根據的。作為一個BI 初創公司,AtScale 銷售銜接BI 前端和SQL 后端的軟件。公司的軟件是引擎中立的,它嘗試盡可能多的兼容,其在BI 領域的廣泛經驗讓這些測試有了實際的意義。
AtScale 最近的關鍵發現,包括了Hive、Impala、Spark SQL 和Presto:
4個引擎都成功運行了AtScale 的BI 基準查詢;
取決于數據量、查詢復雜度和并發用戶數,每個引擎都有自己的性能優勢:
Impala 和Spark SQL 在小數據量的查詢上擊敗了其他人;
Impala 和Spark SQL 在大數據量的復雜join 上擊敗了其他人;
Impala 和Presto 在并發測試上表現的更好。
對比6個月之前的基準測試,所有的引擎都有了2-4倍的性能提升。
Alex Woodie 報告了測試結果,Andrew Oliver 對其進行分析。
讓我們來深入了解這些項目。
Apache Hive
Apache Hive 是Hadoop 生態系統中的***個SQL 框架。Facebook 的工程師在2007年介紹了Hive,并在2008年將代碼捐獻給Apache 軟件基金會。2010年9月,Hive 畢業成為Apache ***項目。Hadoop 生態系統中的每個主要參與者都發布和支持Hive,包括Cloudera、MapR、Hortonworks 和IBM。Amazon Web Services 在Elastic MapReduce(EMR)中提供了Hive 的修改版作為云服務。
早期發布的Hive 使用MapReduce 運行查詢。復雜查詢需要多次傳遞數據,這會降低性能。所以Hive 不適合交互式分析。由Hortonworks 領導的Stinger 明顯的提高了Hive 的性能,尤其是通過使用Apache Tez,一個精簡MapReduce 代碼的應用框架。Tez 和ORCfile,一種新的存儲格式,對Hive 的查詢產生了明顯的提速。
Cloudera 實驗室帶領一個并行項目重新設計Hive 的后端,使其運行在Apache Spark 上。經過長期測試后,Cloudera 在2016年初發布了Hive-on-Spark 的正式版本。
在2016年,Hive 有100多人的貢獻者。該團隊在2月份發布了Hive 2.0,并在6月份發布了Hive 2.1。Hive 2.0 的改進包括了對Hive-on-Spark 的多個改進,以及性能、可用性、可支持性和穩定性增強。Hive 2.1 包括了Hive LLAP(”Live Long and Process“),它結合持久化的查詢服務器和優化后的內存緩存,來實現高性能。該團隊聲稱提高了25倍。
9月,Hivemall 項目進入了Apache 孵化器,正如我在我的機器學習年度總結的第二部分中指出的。Hivemall 最初由Treasure Data 開發并捐獻給Apache 軟件基金會,它是一個可擴展的機器學習庫,通過一系列的Hive UDF 來實現,設計用于在Hive、Pig 和Spark SQL 上運行MapReduce。該團隊計劃在2017年***季度發布了***個版本。
Apache Impala
2012年,Cloudera 推出了Impala,一個開源的MPP SQL 引擎,作為Hive 的高性能替代品。Impala 使用HDFS 和HBase,并利用了Hive 元數據。但是,它繞開了使用MapReduce 運行查詢。
Cloudera 的***戰略官Mike Olson 在2013年底說到Hive 的架構是有根本缺陷的。在他看來,開發者只能用一種全新的方式來實現高性能SQL,例如Impala。2014年的1月、5月和9月,Cloudera 發布了一系列的基準測試。在這些測試中,Impala 展示了其在查詢運行的逐步改進,并且顯著優于基于Tez 的Hive、Spark SQL 和Presto。除了運行快速,Impala 在并發行、吞吐量和可擴展性上也表現優秀。
2015年,Cloudera 將Impala 捐獻給Apache 軟件基金會,進入了Apache 孵化計劃。Cloudera、MapR、Oracle 和Amazon Web Services 分發Impala,Cloudera、MapR 和Oracle 提供了商業構建和安裝支持。
2016年,Impala 在Apache 孵化器中取得了穩步發展。該團隊清理了代碼,將其遷移到Apache 基礎架構,并在10月份發布了***個Apache 版本2.7.0。新版本包括了性能提升和可擴展性改進,以及一些其他小的增強。
9月,Cloudera 發布了一項研究結果,該研究比較了Impala 和Amazon Web Services 的Redshift 列存儲數據庫。報告讀起來很有意思,雖然主題一貫的需要注意供應商的基準測試。
Spark SQL
Spark SQL 是Spark 用于結構化數據處理的組件。Apache Spark 團隊 在2014年發布了Spark SQL,并吸收了一個叫Shark 的早期的Hive-on-Spark 項目。它迅速成為最廣泛使用的Spark 模塊。
Spark SQL 用戶可以運行SQL 查詢,從Hive 中讀取數據,或者使用它來創建Spark Dataset和DataFrame(Dataset 是分布式的數據集合,DataFrame 是統一命名的Dataset 列)。Spark SQL 的接口向Spark 提供了數據結構和執行操作的信息,Spark 的Catalyst 優化器使用這些信息來構造一個高效的查詢。
2015年,Spark 的機器學習開發人員引入了ML API,一個利用Spark DataFrame 代替低級別Spark RDD API 的包。這種方法被證明是有吸引力和富有成果的;2016年,隨著2.0 的發布,Spark 團隊將基于RDD 的API改為維護模式。DataFrame API現在是Spark 機器學習的主要接口。
此外,在2016年,該團隊還在Spark 2.1.0的Alpha 版本中發布了結構化的流式處理。結構化的流式處理是構建在Spark SQL 上的一個流處理引擎。用戶可以像對待靜態源一樣,用同樣的方式查詢流式數據源,并且可以在單個查詢中組合流式和靜態源。Spark SQL 持續運行查詢,并且在流式數據到達的時候更新結果。結構化的流通過檢查點和預寫日志來提供一次性的容錯保障。
Apache Drill
2012年,由Hadoop 分銷商的***之一MapR 領導的一個團隊,提出構建一個Google Dremel 的開源版本,一個交互式的分布式熱點分析系統。他們將其命名為Apache Drill。Drill 在Apache 孵化器中被冷落了兩年多,最終在2014年底畢業。該團隊在2015年發布了1.0。
MapR 分發和支持Apache Drill。
2016年,超過50個人對Drill 做出了貢獻。該團隊在2016年發布了5個小版本,關鍵的增強功能包括:
- Web 認證
- 支持Apache Kudu 列數據庫
- 支持HBase 1.x
- 動態UDF 支持
2015年,兩位關鍵的Drill 貢獻者離開了MapR,并啟動了Dremio,該項目尚未發布。
Apache HAWQ
Pivotal 軟件在2012年推出了一款商業許可的高性能SQL 引擎HAWQ,并在嘗試市場營銷時取得了小小的成功。改變戰略后,Pivotal 在2015年6月將項目捐獻給了Apache,并于2015年9月進入了Apache 孵化器程序。
15個月之后,HAWQ 仍然待在孵化器中。2016年12月,該團隊發布了HAWQ 2.0.0.0,加入了一些錯誤修復。我猜它會在2017年畢業。
對HAWQ 喜愛的一個小點是它支持Apache MADlib,一個同樣在孵化器中的SQL 機器學習項目。HAWQ 和MADlib 的組合,應該是對購買了Greenplum 并且想知道發生了什么的人們的一個很好的安慰。
Presto
Facebook 工程師在2012年發起了Presto 項目,作為Hive 的一個快速交互的取代。在2013年推出時,成功的支持了超過1000個Facebook 用戶和每天超過30000個PB級數據的查詢。2013年Facebook 開源了Presto。
Presto 支持多種數據源的ANSI SQL 查詢,包括Hive、Cassandra、關系型數據庫和專有文件系統(例如Amazon Web Service 的S3)。Presto 的查詢可以聯合多個數據源。用戶可以通過C、Java、Node.js、PHP、Python、R和Ruby 來提交查詢。
Airpal 是Airbnb 開發的一個基于web 的查詢工具,讓用戶可以通過瀏覽器來提交查詢到Presto。Qubole 位Presto 提供了管理服務。AWS 在EMR 上提供Presto 服務。
2015年6月,Teradata 宣布計劃開發和支持該項目。根據宣布的三階段計劃,Teredata 提出將Presto 集成導Hadoop 生態系統中,能夠在YARN 中進行操作,并且通過ODBC 和JDBC 增強連接性。Teredata 提供了自己的Presto 發行版,附帶一份數據表。2016年6月,Teradata 宣布了Information Builders、Looker、Qlik、Tableau 和ZoomData 的鑒定結果,以及正在進行中的MicroStrategy 和Microsoft Power BI。
Presto 是一個非常活躍的項目,有一個巨大的和充滿活力的貢獻者社區。該團隊發布的速度比Miki Sudo 吃熱狗的速度還要快--我統計了下,2016年共發布了42個版本。Teradata 并沒有打算總結有什么新的東西,我也不打算在42個發行說明里去篩選,所以就讓我們說它更好吧。
其他Apache 項目
這里還有5個其他的Apache 生態系統的SQL 混合項目。
Apache Calcite
Apache Calcite 是一個開源的數據庫構建框架。它包括:
SQL 解析器、驗證器和JDBC 驅動
查詢優化工具,包括關系代數API,基于規則的計劃器和基于成本的查詢優化器
Apache Hive 使用Calcite 進行基于成本的查詢優化,而Apache Drill 和Apache Kylin 使用SQL 解析器。
Calcite 團隊在2016年推出了5個版本包括bug 修復和用于Cassandra、Druid 和Elasticsearch 的新適配器。
Apache Kylin
Apache Kylin 是一個具有SQL 接口的OLAP 引擎。由eBay 開發并捐獻給Apache,Kylin 在2015年畢業成為***項目。
2016年成立的創業公司Kyligence 提供商業支持和一個叫做KAP 的數據倉庫產品,雖然在Crunchbase 上沒有列出它的資金情況,有消息來源稱它有一個強大的背景,并且在上海有個大辦公室。
Apache Phoenix
Apache Phoenix 是一個運行在HBase 上的SQL 框架,繞過了MapReduce。Salesforce 開發了該軟件并在2013年捐獻給了Apache。2014年5月項目畢業成為***項目。Hortonworks 的Hortonworks 數據平臺中包含該項目。自從領先的SQL 引擎都適配HBase 之后,我不清楚為什么我們還需要Phoenix。
Apache Tajo
Apache Tajo 是Gruter 在2011年推出的一個快速SQL 數據倉庫框架,一個大數據基礎設施公司,并在2013年捐獻給Apache。2014年Tajo 畢業成為***項目。在作為Gruter 主要市場的韓國之外,該項目很少吸引到預期用戶和貢獻者的興趣。除了Gartner 的Nick Heudecker 曾提過,該項目不在任何人的工作臺上。
Apache Trafodion
Apache Trafodion 是另一個SQL-on-HBase 項目,由HP 實驗室構思,它告訴你幾乎所有你需要知道的。2014年6月HP 發布Trafodion,一個月之后,Apache Phoenix 畢業投產。6個月之后,HP 的高管們認為相對于另一款SQL-on-HBase 引擎,它的商業潛力有限,所以他們將項目捐獻給了Apache,項目于2015年5月進入孵化器。
如果孵化結束,Trafodion 承諾成為一個事務數據庫。不幸的是,這個領域有大量的選擇,而開發團隊唯一的競爭優勢似乎是“它是開源的,所以它很便宜”。