OpenAI官方基準測試:承認Claude遙遙領先(狗頭)
OpenAI承認Claude是最好的了(狗頭)。
剛剛開源的新基準測試PaperBench,6款前沿大模型驅動智能體PK復現AI頂會論文,新版Claude-3.5-Sonnet顯著超越o1/r1排名第一。

與去年10月OpenAI考驗Agent機器學習代碼工程能力MLE-Bnch相比,PaperBench更考驗綜合能力,不再是只執行單一任務。
具體來說,智能體在評估中需要復刻來自ICML 2024的論文,任務包括理解論文、編寫代碼和執行實驗。

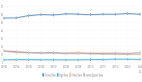
最終成績如下:
Claude-3.5-Sonnet斷崖式領先,第二名o1-high分數只有第一的60%,第三名DeepSeek-R1又只有第二名的一半。
此外GPT-4o超過了推理模型o3-mini-high也算一個亮點。

除了AI之間的PK, OpenAI這次還招募頂尖的機器學習博士對比o1。
雖然最終結論是AI在復現頂會論文上還無法超越人類,但展開時間軸發現,在工作時間1-6小時內Ai的進度還是比人類要快的。
12-24小時階段AI與人類的進度相當,人類需要工作24-48小時才能超過AI。

有創業者稱贊OpenAI這波真的Open了,而且不避諱競爭對手的出色表現,咱們科技圈就需要這種精神。

Agent復現頂會論文
PaperBench選取20篇ICML 2024 Spotlight和Oral論文,要求AI創建代碼庫并執行實驗,復制論文成果,且不能使用原作者代碼。

OpenAI與每篇論文的原作者共同制定詳細評分標準,總共包含8316個可單獨評分的任務。
開卷考試,也就是允許Agent有限聯網搜索,把原論文代碼庫和其他人復現的代碼庫拉黑名單。
完整評估流程分為3個階段:
- Agent在ubuntu容器中創建并提交復制論文的代碼庫。
- 在具有GPU訪問權限的新容器中執行代碼
- 裁判模型在第三個容器中給復現結果打分

評估時用分級標準打分,按葉節點、父節點逐級評分,主要指標是所有論文的平均復制分數。

評分也是由大模型自動執行,實驗發現o3-mini當裁判的性價比最高。
給每篇論文評分花費66美元,比聘請人類專家當裁判要便宜,速度也更快。

運行評估所需的代碼和數據、Docker鏡像等正在GitHub逐步開源。

One More Thing
在論文的附錄中,OpenAI還給出了讓AI復現頂會論文的Prompt,有需要的朋友可以學習一下。
BasicAgent System Prompt:
- 強調智能體要完整復制論文,明確最終目標是讓運行reproduce.sh能復現論文所有指標
- 指導智能體使用工具逐步完成任務,避免一次性執行過多操作
- 要求智能體充分利用時間優化解決方案,而不是急于提交初步結果

IterativeAgent System/Continue Prompt:
- 強調時間很充裕,要逐步完成任務
- 每一步都提醒智能體使用可用的工具
- 強調代碼編寫規范

Task Instructions:
- 明確任務、可用資源、提交要求等多方面信息

- 給出代碼示例
- 最后再次強調權限、考試時間等,還提醒AI要真的去執行復現,而不只是寫一個計劃。

就有點像人類準考證上寫的考場須知了。