Cinder磁盤備份原理與實踐
一、背景
1.1 數據保護技術概述
快照(Snapshot)、復制(Replication)、備份(Backup)是存儲領域中最為常見的數據保護技術。快照用于捕捉數據卷在某一個時刻的狀態,用戶可以隨時回滾到這個狀態,也可以基于該快照創建新的數據卷。備份就是對數據進行導出拷貝并傳輸到遠程存儲設備中。當數據損壞時,用戶可以從遠端下載備份的數據,手動從備份數據中恢復,從而避免了數據損失。快照類似于git的commit操作,我們可以隨時reset/checkout到任意歷史commit中,但一旦保存git倉庫的磁盤損壞,提交的commit信息將永久丟失,不能恢復。而備份則類似于git的push操作,即使本地的數據損壞,我們也能從遠端的git倉庫中恢復。簡而言之,快照主要用于快速回溯,而備份則用于容災,還能避免誤刪除操作造成數據丟失。數據復制則類似于mysql的master/slave主從同步,通常只有master支持寫操作,slave不允許用戶直接寫數據,它只負責自動同步master的數據,但一旦master出現故障,slave能夠提升為master接管寫操作。因此復制不僅提供了實時備份的功能,還實現了故障自動恢復(即高可用)。
1.2 Cinder數據保護功能介紹
Cinder是OpenStack中相對成熟的組件(總分為8分的成熟度評分中獲得了8分滿分),也是OpenStack的核心組件之一,為OpenStack云主機提供彈性的塊存儲服務,承載著用戶大多數的業務數據,即使出現數據的絲毫損壞也將可能導致災難性后果,因此數據的完整性保護至關重要。不得不說Cinder對數據卷保護方面支持度還是比較給力的,目前Cinder已經同時支持了對數據卷的快照、復制和備份功能。
快照應該是Cinder非常熟悉非常受歡迎的功能了,也是Cinder默認支持的功能,幾乎所有的存儲后端都支持快照。而備份作為Cinder的可選功能之一,由于數據卷的存儲后端很多已經提供了多副本功能(比如Ceph存儲后端默認為三副本),通常很少人會再部署一套備份存儲集群,因此部署率并不是很高。復制也是Cinder的可選功能之一,目前支持的存儲后端還非常有限,最常采用的RBD存儲后端也是在Ocata版本才開始支持,并且要求Ceph版本需要支持rbd-mirror(jewel版本以上),因此受到用戶的關注度還不是很高,部署率較低。
二、深入理解Cinder數據卷備份原理
2.1 cinder backup功能介紹
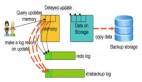
cinder磁盤備份為用戶的數據卷實例提供備份和恢復功能,實現了基于塊的容災功能。從K版本開始,Cinder引入了增量備份功能,相對全量備份需要拷貝和傳輸整個數據卷,增量備份只需要傳輸變化的部分,大大節省了傳輸開銷和存儲開銷。通常情況下,當用戶執行備份或者恢復操作時,需要手動卸載數據卷,即數據卷不支持在掛載狀態下熱備份。從L版本開始,新增了force選項,當用戶指定force選項時能夠對掛載的數據卷強制執行備份操作,這樣可能帶來數據不一致的風險,不過社區針對這種情況做了些優化,比如在創建備份前先基于該數據卷快照創建臨時數據卷,然后基于臨時數據卷執行后續備份操作。
Cinder開啟備份功能,需要單獨部署cinder-backup服務。cinder-backup服務和cinder-volume服務類似,也支持各種不同的驅動,對接不同的存儲后端,目前支持的存儲驅動列表如下:
- swift,備份數據保存在OpenStack Swift對象存儲中。
- google,備份數據保存在Google Cloud Storage(GCS)中。
- glusterfs,保存到glusterfs中。
- nfs,保存到NFS中。
- posix,保存到本地文件系統。
- tsm,保存在IBM Tivoli Storage Manager(TSM)。
- ceph,保存到ceph集群中。
從列表中看,目前cinder backup尚不支持備份數據到AWS S3中。
除了數據卷本身的備份,cinder backup還支持將元數據序列化導出(export record),這樣即使數據庫中的數據丟失了,也能從導出的元數據中快速恢復。
2.2 cinder backup原理剖析
前面提到cinder backup支持多種后端存儲驅動,但大體可以分為兩類:
- 存儲系統本身就提供塊存儲服務,比如ceph。這種情況只需要直接導入到該存儲系統即可。
- 存儲系統不支持塊存儲服務,只支持基于文件的存儲,以上除了ceph和tsm都屬于此類。此時備份采取了分塊備份策略,即首先把數據卷切割為一個個獨立的文件,然后分別把這些文件存儲到設備中。恢復時只需要重組這些小文件即可。
接下來我們針對此兩種情況深入研究下cinder backup的實現原理。
2.2.1 分塊備份策略在介紹之前先了解兩個重要的參數
- chunk_size: 表示將volume切割成多大的塊進行備份,一個塊稱為一個chunk。在NFS中這個值叫做backup_file_size,默認是1999994880Byte,大約1.8G。在Swift中這個值叫做backup_swift_object_size,默認是52428800Byte,也就是50M。這個參數決定數據卷備份后塊的數量(Object Count),比如一個2GB的數據卷,如果chunk_size為500MB,則大約需要4個塊,如果使用本地文件系統存儲的話,對應就是4個文件。
- sha_block_size: 這個值用于增量備份,決定多大的塊求一次hash,hash相同說明內容沒有變化,不需要備份。它決定了增量備份的粒度。在NFS中,這個值叫做backup_sha_block_size_bytes,在Swift中,這個值叫做backup_swift_block_size。默認都是32768Byte,也就是32K。在Ceph,沒有對應的概念。
對一個數據卷做全量備份時,每次從數據卷讀入chunk_size字節的數據構成一個chunk,然后每sha_block_size個字節做一次sha計算,并將結果保存起來,最后把chunk_size的數據進行壓縮(可以配置不壓縮)后保存到對應的存儲系統上,這就形成了NFS上的一個文件或者Swift中的一個object[6]。如此循環直到把整個數據卷都備份到存儲系統。
那恢復的時候怎么重組呢?這就需要保存元數據信息,元數據信息包括:
- backup信息:其實就是數據庫中的信息,或者說就是一個backup object實例的序列化,包括backup name、description、volume_id等。
- volume信息:數據卷信息,即volume實例的序列化,包括size、name等。
- 塊信息:即objects信息,這是最重要的數據,記錄了每一個塊的長度、偏移量、壓縮算法、md5值,備份恢復時主要通過這些塊信息拼接而成。
- 版本:序列化和持久化必不可少的參數。
除了保存以上元數據信息,還會按順序保存每一個block的sha256值。這些信息主要用于支持增量備份。做增量備份時,也是每次從數據卷讀入chunk_size字節的chunk數據,然后計算該chunk的每個block的sha值。不同的是,Cinder會把每一個block的sha值與其父備份對應的sha值比較,僅當該block的sha值與父備份block的sha值不一樣時,才保存對應的block數據。如果sha值和父備份的sha值相同,說明這個block的數據沒有更新,不需要重新保存該block數據,而只需要保存sha值。當然,如果有多個連續block的sha值都不一樣,則保存時會合并成一個object,通過元數據記錄該object在原volume的偏移量以及長度。
如圖1所示,假設一個chunk分為9個block,每個block為100KB,注意每個block都保存了sha256值,圖中沒有標識。基于該chunk做一次增量備份后,假設只有block 2、7、8有更新,則增量備份只會保存block 2、7、8,由于7和8是連續的,因此會自動合并成一個chunk,而block 2單獨形成一個chunk,即原來的chunk分裂成了兩個chunk,但總大小為300KB,節省了1/3的存儲空間。

圖1 增量備份原理圖
備份的恢復參考文獻[6]講得非常清楚,這里直接引用:
全量備份的恢復很簡單,只需要找到對應的備份,將其內容寫回對應的volume即可。那么這里有個問題,每個備份都對應存儲上哪些文件呢,每個文件又對于原始volume中哪些數據?還記得創建備份時生成的metadata文件嗎,答案就在其中。恢復備份時,會讀取這個文件,然后將每一個備份文件恢復到對應的位置。當然,如果有壓縮也會根據metadata中的描述,先解壓再寫入對應的volume中。
增量備份的恢復稍微復雜一些,正如之前的描述,增量備份之間有依賴,會形成備份鏈,我們需要恢復所選備份及其在備份鏈上之前所有的數據。在恢復時,需要查詢數據庫,獲取當前備份及備份鏈上之前的所有備份,其順序是[所選備份,父備份,父父備份,…,全量備份],恢復的時候會按照相反的順序依次進行,即首先恢復全量備份,接著創建的第一個增量備份,第二個增量備份,直到所選的備份。每個備份恢復時依賴創建備份時生成的metadata文件,將備份包含的文件,恢復到volume中。每個備份的恢復和全量備份的恢復方式一樣。
從備份的原理可以看出,增量備份能夠節省存儲空間,但隨著備份鏈長度越來越長,恢復時會越來越慢,性能越來越差,實際生產環境中應該權衡存儲空間和性能,控制備份鏈的長度。
Swift、NFS、本地文件系統、GCS等都是使用以上的備份策略,實際上實現也是完全一樣的,區別僅僅在于實現不同存儲系統的Reader、Writer驅動。
2.2.2 直接導入策略
直接導入策略即把原數據卷導出后直接導入到目標存儲系統中。對于支持差量導入的存儲系統,增量備份時則可以進一步優化。
以Ceph為例,我們知道Ceph RBD支持將某個image在不同時刻的狀態進行比較后導出(export-diff)補丁(patch)文件,然后可以隨時將這個補丁文件打到某個image中(import-diff)。即ceph原生支持差量備份,利用該特性實現增量備份就不難了。不過有個前提是,必須保證cinder-volume后端和cinder-backup后端都是ceph后端,否則仍然是一塊一塊的全量拷貝。
如果是對volume進行第一次備份,則:
- 在用于備份的ceph集群創建一個base image,size和原volume一樣,name為"volume-VOLUMD_UUID.backup.base" % volume_id。
- 在原volume創建一個新的快照,name為backup.BACKUP_ID.snap.TIMESTRAMP。
- 在原RBD image上使用export-diff命令導出與創建時比較的差量數據,然后通過管道將差量數據導入剛剛在備份集群上新創建的RBD image中。
如果不是對volume第一次備份,則:
- 在原volume中找出滿足r"^backup\.([a-z0-9\-]+?)\.snap\.(.+)$"的最近的一次快照。
- 在原volume創建一個新的快照,name為backup.BACKUP_ID.snap.TIMESTRAMP。
- 在原RBD image上使用export-diff命令導出與最近的一次快照比較的差量數據,然后通過管道將差量數據導入到備份集群的RBD image中。
恢復時相反,只需要從備份集群找出對應的快照并導出差量數據,導入到原volume即可。
注意:
- volume和backup都使用ceph后端存儲時,每次都會嘗試使用增量備份,無論用戶是否傳遞incremental參數值。
- 使用直接導入策略,不需要元數據信息以及sha256信息。
三、踩過的“坑”
雖然在前期做了大量關于cinder backup的調研工作,但實際部署過程中仍然踩了不少坑,PoC測試過程也非一帆風順,還好我們在填坑的過程還是比較順利的。本小節總結我們在實踐過程中遇到的坑,避免后來者重復踩“坑”。
3.1 熱備份導致quota值異常
我們知道備份是一個IO開銷和網絡開銷都比較大的操作,非常耗時。當對已經掛載的數據卷執行在線備份時,Cinder為了優化性能,減少數據不一致的風險,首先會基于該數據卷創建一個臨時卷,然后基于臨時卷創建備份,備份完成時會自動刪除臨時數據卷。從代碼中看,創建臨時卷時并沒有計算quota,換句話說,創建的臨時磁盤是不占用quota值的。但刪除時調用的是標準的刪除接口,該接口會釋放對應數據卷占用的數據卷quota值(主要影響gigabytes和volumes值)。也就是說,創建的臨時磁盤使volume quota值只減不增,用戶可以通過這種方式繞過quota限制。目前該問題社區還未修復,已提交bug:https://bugs.launchpad.net/cinder/+bug/1670636。
3.2 不支持ceph多后端情況
我們內部cinder對接了多個ceph集群,不同的ceph集群通過不同的配置文件區分。但cinder-backup服務向cinder-volume服務獲取connection info時并沒有返回ceph的配置文件路徑,于是cinder-backup服務使用默認的配置文件/etc/ceph/ceph.conf,該ceph集群顯然找不到對應volume的RBD image,因此在多backend情況下可能導致備份失敗。不過該問題在新版本中不存在了。
3.3 使用ceph存儲后端時不支持差量備份
我們前面提到如果cinder-volume和cinder-backup后端都是ceph,則會利用ceph內置的rbd差量備份實現增量備份。那cinder-backup服務怎么判斷數據卷對應的后端是否ceph呢?實現非常簡單,只需要判斷數據卷的連接信息是否存在rbd_image屬性,實現代碼如下:
- def _file_is_rbd(self, volume_file):
- """Returns True if the volume_file is actually an RBD image."""
- return hasattr(volume_file, 'rbd_image')
社區從M版開始把與存儲后端交互的代碼獨立出來,建立了一個新的項目–os-brick,與之前的ceph驅動存在不兼容,沒有rbd_image這個屬性。因此backup服務會100%判斷數據卷不是ceph后端,因此100%執行全量備份。該問題社區還未完全修復,可參考https://bugs.launchpad.net/cinder/+bug/1578036。
四、我們的改進
4.1 獲取父備份ID
當備份存在子備份時,用戶無法直接刪除該備份,而必須先刪除所有依賴的子備份。目前Cinder API只返回備份是否存在依賴的子備份,而沒有返回子備份的任何信息,也沒有返回父備份的信息。當用戶創建了很多備份實例時,很難弄清楚備份之間的父子關系。我們修改了Cinder API,向用戶返回備份的父備份id(parent_id),并且支持基于parent_id過濾搜索備份。當用戶發現備份存在依賴時,能夠快速檢索出被依賴的子備份。當然,如果存在很長的父子關系時,需要一層一層判斷,仍然不太方便,并且不能很清楚的輸出備份的父子關系。于是我們引入了備份鏈的概念,下節詳細討論。
4.2 引入備份鏈概念
為了方便查看備份之間的父子關系,我們引入了備份鏈(backup chain)的概念,一個數據卷可以有多個備份鏈,每條備份鏈包括一個全量備份以及多個增量備份組成。我們新增了兩個API,其中一個API輸出指定數據卷的備份鏈列表,另一個API輸出指定備份鏈的所有備份點,按照父子關系輸出。目前我們的備份鏈只支持線性鏈,暫時不支持分叉的情況。通過備份鏈,用戶能夠非常方便地查看備份之間的父子關系和備份時間序列,如圖2。

圖2 備份鏈展示
4.3 創建備份時指定備份鏈
創建增量備份時,默認是基于時間戳選擇最新的備份點作為父備份,我們擴展了該特性,支持用戶選擇在指定備份鏈上創建備份,這樣也可以避免備份鏈過長的情況。
五、后續工作
Cinder backup功能已經相對比較完善了,但仍然存在一些功能不能滿足客戶需求,我們制定了二期規劃,主要工作包括如下:
5.1 級聯刪除
目前Cinder不支持備份的級聯刪除,即如果一個備份實例存在依賴的子備份,則不能刪除該備份,必須先刪除其依賴的所有子備份。如果備份鏈很長時,刪除備份時非常麻煩。在二期規劃中,我們將實現備份的級聯刪除功能,通過指定--force選項,支持刪除備份以及其依賴的所有備份,甚至刪除整個備份鏈。
5.2 獲取增量備份大小
目前Cinder備份的實例大小是繼承自原volume的大小,基于分塊策略備份還有Object Count(chunk 數量)的概念,但這只是顯示分成了幾個chunk,每個chunk大小不一定是一樣的,并不能根據chunk數量計算實際占用的存儲空間。備份存儲空間是我們計費系統的計量標準之一,全量備份和增量備份成本肯定是不一樣的,如果價錢一樣,則用戶并不一定樂于使用增量備份。在二期規劃中,我們將實現計算備份占用的實際存儲空間的接口。
5.3 備份到S3
很多私有云用戶考慮各種成本,不一定會部署額外用于備份的Ceph集群,也不一定需要Swift對象存儲,而更傾向于將數據備份到價格低廉、穩定可靠的AWS S3中。目前Cinder backup后端還不支持S3接口,為了滿足客戶需求,我們計劃在二期中實現S3接口,用戶可以隨時把volume數據備份到S3中。
六、總結
本文首先介紹了數據保護的幾種常用技術,指出備份是數據保護的關鍵技術之一。接下來重點介紹了cinder backup的原理,對比了基于分塊備份策略和直接導入策略。然后吐槽了我們在實踐中踩到的各種“坑”。最后分享了我們做的一些優化改進工作以及后期工作。
【本文是51CTO專欄作者“付廣平”的原創文章,如需轉載請通過51CTO獲得聯系】