













Apache Impala引領(lǐng)傳統(tǒng)分析數(shù)據(jù)庫技術(shù)的發(fā)展
與傳統(tǒng)的分析數(shù)據(jù)庫(Greenplum)相比,未經(jīng)修改的基于TPC-DS的性能基準(zhǔn)測試表現(xiàn)出了Impala的領(lǐng)導(dǎo)地位,特別是對于多用戶并發(fā)工作負(fù)載而言。此外,基準(zhǔn)測試還進(jìn)一步證明了分析數(shù)據(jù)庫與Hive LLAP、Spark SQL和Presto等SQL-on-Hadoop引擎之間存在的顯著性能差距。
過去一年是Apache Impala(正在孵化中)發(fā)展變化***的一年。Impala團(tuán)隊不僅繼續(xù)努力不斷擴(kuò)大其規(guī)模和穩(wěn)定性,而且還推出了一系列的關(guān)鍵功能,進(jìn)一步鞏固了Impala作為高性能商務(wù)智能(BI)和SQL分析的開放標(biāo)準(zhǔn)地位。對于云計算和混合部署而言,Impala現(xiàn)在可以提供云端-本地部署彈性、靈活性,以及直接從Amazon S3對象存儲中(以及為未來一年制定的其他對象存儲)讀取/寫入的能力。隨著Apache Kudu的GA,用戶現(xiàn)在可以使用Impala對接收到或更新的數(shù)據(jù)立即進(jìn)行高性能分析。另外,也很容易將現(xiàn)有的商務(wù)智能(BI)工作負(fù)載從傳統(tǒng)分析數(shù)據(jù)庫或數(shù)據(jù)倉庫遷移至由Impala構(gòu)建的Cloudera分析數(shù)據(jù)庫中,同時可以使用Navigator Optimizer優(yōu)化其性能。而且如同以往一樣,對于更大的并發(fā)性工作負(fù)載的性能改進(jìn)仍然是全年工作的重中之重。
除了這些性能改進(jìn)之外,隨著越來越多的企業(yè)機(jī)構(gòu)(例如紐約證券交易所(NYSE)和奎斯特診斷公司(Quest Diagnostics))已經(jīng)注意到Cloudera現(xiàn)代分析數(shù)據(jù)庫(而不是傳統(tǒng)分析數(shù)據(jù)庫)的靈活性、可擴(kuò)展性和支持SQL及非SQL工作負(fù)載(例如數(shù)據(jù)科學(xué)、機(jī)器學(xué)習(xí)和操作性工作負(fù)載)的開放式架構(gòu),Impala的采用率也在不斷增長。
對于該基準(zhǔn)測試而言,我們使用未經(jīng)修改的多用戶TPC-DS查詢對具有Impala的Cloudera現(xiàn)代分析數(shù)據(jù)庫與傳統(tǒng)分析數(shù)據(jù)庫(Greenplum)進(jìn)行了性能比較。我們還研究了分析數(shù)據(jù)庫與SQL-on-Hadoop引擎,例如:Hive LLAP、Spark SQL和Presto的對比。總的來說,我們發(fā)現(xiàn):
- Impala相對于傳統(tǒng)分析數(shù)據(jù)庫而言性能更為先進(jìn),包括超過8倍的高并發(fā)工作負(fù)載性能。
- 分析數(shù)據(jù)庫和其他SQL-on-Hadoop引擎之間存在顯著的性能差異,使用Impala可以使多用戶工作負(fù)載的性能提高近22倍。
- 其他SQL-on-Hadoop引擎也無法完成大規(guī)模基準(zhǔn)測試來與分析數(shù)據(jù)庫進(jìn)行比較,因此需要一個簡化的、規(guī)模較小的基準(zhǔn)測試(Hive甚至還需要修改,Presto無法完成多用戶測試)。
- 比較集分析數(shù)據(jù)庫(采用10TB和1TB級別的數(shù)據(jù)進(jìn)行測試,未經(jīng)修改的查詢)。● Impala 2.8 from CDH 5.10;
- Greenplum Database 4.3.9.1。
附加的SQL-on-Hadoop引擎(采用1TB級別的數(shù)據(jù)進(jìn)行測試,并對Hive進(jìn)行了一些查詢修改)。
- Spark SQL 2.1;
- Presto 0.160;
- Hive 2.1 with LLAP from HDP 2.5。
配置每一個集群由七個工作節(jié)點組成,每個節(jié)點采用以下配置:● CPU:2 塊E5-2698 v4 @ 2.20GHz;
- 存儲器:8 塊2TB硬盤;
- 內(nèi)存:256GB內(nèi)存。
我們配置了三個由相同硬件組成的集群,其中一個用于Impala、Spark和Presto(負(fù)責(zé)運行CDH),另一個用于Greenplum,還有一個用于具有LLAP(負(fù)責(zé)運行HDP)的Hive。每個集群都裝載了相同的TPC-DS數(shù)據(jù):針對Impala和Spark的Parquet/Snappy,以及針對Hive和Presto的ORCFile/Zlib,而Greenplum使用內(nèi)部的柱狀格式與QuickLZ壓縮文件。
查詢工作負(fù)載:● 數(shù)據(jù):TPC-DS 10TB和1TB(比例系數(shù));
- 查詢:TPC-DS v2.4查詢模板(未經(jīng)修改的TPC-DS)。
- 我們運行了77個查詢,所有引擎的運行都具有語言支持,無需修改TPC-DS規(guī)范(Hive除外)。1其中22個已排除的查詢都使用以下幾個不常見的SQL功能:
- 使用ROLLUP進(jìn)行的11個查詢(TPC-DS允許的變體在本測試中未使用);
- 3個INTERSECT或EXCEPT查詢;
- 8個具有高級子查詢位置的查詢(例如HAVING子句中的子查詢等)。
由于Hive對子查詢位置的更大限制,我們被迫進(jìn)行了一些修改以創(chuàng)建語義上等同的查詢。我們針對Hive運行了這些經(jīng)過修改的查詢。
雖然Greenplum、Presto和Spark SQL也聲稱支持所有99個未經(jīng)修改的查詢,但是即使沒有并發(fā)執(zhí)行,Spark SQL和Presto也無法成功完成10TB級別的99個查詢。Greenplum隨著多用戶并發(fā)性的增加而出現(xiàn)越來越多的查詢失敗(詳見下文)。
分析數(shù)據(jù)庫基準(zhǔn)測試結(jié)果10 TB級別上Impala與Greenplum的比較我們使用常見的77個未修改的TPC-DS查詢在10TB級別數(shù)據(jù)下對Impala和Greenplum進(jìn)行了測試。在單用戶測試和更實際的多用戶測試集上比較了兩個、四個和八個并發(fā)流。總結(jié)如下:● 總體來說,Impala在單用戶和多用戶并發(fā)測試方面優(yōu)于Greenplum。
- 相比Greenplum而言,Impala 線性擴(kuò)展表現(xiàn)更優(yōu)異,隨著并發(fā)度增加,Impala與Greenplum的性能比率從2倍上升到了8.3倍,,同時保持了更高的成功率。
在單用戶測試中,當(dāng)比較查詢中的幾何平均值時,Impala的性能是Greenplum的2.8倍;完成查詢流的總時間是Greenplum的1.8倍:
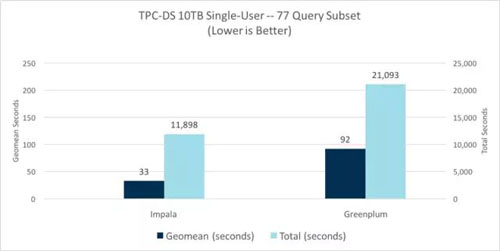
對于多用戶吞吐量比較,我們使用TPC-DS dsqgen工具運行同一組77個未修改的查詢來生成并發(fā)查詢流。每個查詢流由隨機(jī)排序的77個通用查詢組成,并且每個查詢流使用不同的查詢替換值。我們運行了多個測試,增加了超過系統(tǒng)飽和點的查詢流數(shù)量,并且測量了各個并發(fā)級別的所有后續(xù)查詢的吞吐量。
如下圖所示,與Greenplum相比,Impala的性能指標(biāo)隨著并發(fā)速度從2個查詢流2倍的速度提升加速到8個查詢流8.3倍的速度提升。
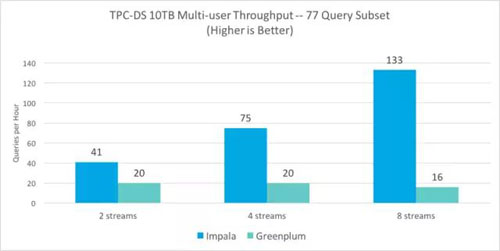
鑒于集群的規(guī)模與數(shù)據(jù)集大小和并發(fā)性相比較而言較小,對于Impala和Greenplum這兩個系統(tǒng)而言,預(yù)期在并發(fā)性增加時會發(fā)現(xiàn)一些查詢失敗。Impala和Greenplum這兩個系統(tǒng)在兩個查詢流測試中達(dá)到了100%的成功率。對于四個和八個查詢流測試,Impala系統(tǒng)的平均成功率為97%,而Greenplum系統(tǒng)的成功率下降到50%。如果這些測試在大于7節(jié)點集群的集群上運行,則可以預(yù)期這兩個系統(tǒng)的成功率都會相應(yīng)提高。分析數(shù)據(jù)庫與SQL-on-Hadoop引擎1TB基準(zhǔn)測試我們已經(jīng)嘗試針對SQL-on-Hadoop引擎使用相同的77個查詢和10TB級別基準(zhǔn)測試,但是,Hive、Presto和Spark SQL都無法成功完成77個未修改查詢中的大多數(shù)查詢,甚至僅僅是單用戶結(jié)果也未能成功,因此無法在10TB級上進(jìn)行比較。因此,我們在1TB規(guī)模下運行了單獨的比較,將分析數(shù)據(jù)庫引擎與其余的SQL-on-Hadoop引擎進(jìn)行比較。除了Hive之外,所有的引擎都使用相同的77個TPC-DS查詢,但是需要進(jìn)行一些修改,以尋找方法去繞過這些限制條件,從而解決無法解析的子查詢。
通過這些簡化的標(biāo)準(zhǔn)(對于其他SQL-on-Hadoop引擎來說是非常必要的),我們再次對所有五個引擎進(jìn)行了單用戶測試和更為真實環(huán)境的多用戶測試。測試結(jié)果匯總?cè)缦拢?/p>
- 分析數(shù)據(jù)庫 – Impala和Greenplum系統(tǒng)在各個并發(fā)級別展現(xiàn)出的性能都優(yōu)于所有的SQL-on-Hadoop引擎。
- 隨著并發(fā)性的提高,再次看到Impala在性能方面拔得頭籌,是其他引擎的8.5倍 – 21.6倍。
- 在所有引擎中,Presto在單用戶測試中表現(xiàn)出最慢的性能,甚至無法完成多用戶測試。
在該單用戶測試中,我們再次看到,在幾何平均值方面相較而言Impala仍然保持了其性能優(yōu)勢,但是,Greenplum在總時間上略有下降。這兩個分析數(shù)據(jù)庫的性能顯著優(yōu)于其他引擎,與其他SQL-on-Hadoop引擎相比,Impala在幾何平均值方面性能優(yōu)勢在3.6倍至13倍之間,在總時間方面性能優(yōu)勢在2.8倍-8.3倍之間。
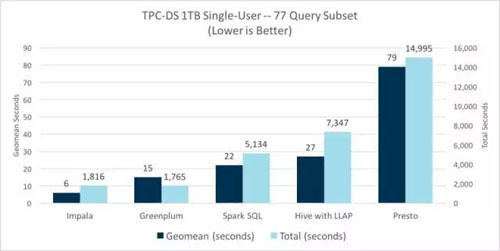
Presto對除了過濾、分組和聚合的簡單單表掃描之外的其他常見的 SQL 查詢表現(xiàn)的很掙扎。對于非常簡單的查詢類型,它更符合Spark SQL的性能,但是如上所述,對于使用更多標(biāo)準(zhǔn)SQL(包括連接)的更典型的商務(wù)智能(BI)查詢,是執(zhí)行效果最差的SQL-on-Hadoop集群。
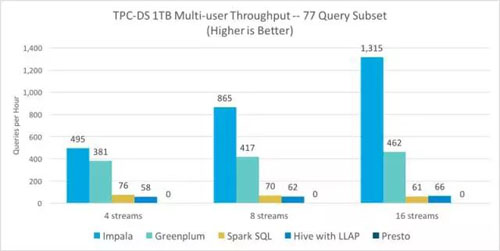
使用TPC-DS通過四個、八個和十六個并發(fā)流運行更具代表性的多用戶比較測試,以生成與上述的10TB分析數(shù)據(jù)庫比較一樣的隨機(jī)查詢流。除Presto之外,所有引擎都能夠在三個并發(fā)級別的1TB級別下完成流,而不會出現(xiàn)任何查詢失敗。即使只運行四個并發(fā)查詢,Presto也可能由于內(nèi)存不足錯誤而使大多數(shù)查詢失敗。
對于能夠成功完成多用戶并發(fā)測試的引擎,分析數(shù)據(jù)庫組群和SQL-on-Hadoop組群之間的性能差異變得更加明顯。Impala在每一個并發(fā)級別上都展示出了優(yōu)異的吞吐量 – 不僅比Greenplum快1.3-2.8倍,與Spark SQL相比,其速度快達(dá)6.5-21.6倍,并且比Hive快8.5-19.9倍。
結(jié)論各企業(yè)機(jī)構(gòu)越來越期待現(xiàn)代化改造其系統(tǒng)架構(gòu),但是不愿意犧牲重要商務(wù)智能(BI)和SQL分析所需的交互式、多用戶性能。Impala作為Cloudera公司平臺的一部分,能夠獨特地提供一個現(xiàn)代化分析數(shù)據(jù)庫。通過設(shè)計,Impala可以靈活地支持更多種類的數(shù)據(jù)和使用案例,而無需任何前期建模工作;Impala可以有彈性地和成本高效地在公司內(nèi)部部署和云端部署方式下按需進(jìn)行擴(kuò)展;并且,作為共享平臺的一部分,這些相同的數(shù)據(jù)可用于其他團(tuán)隊和工作負(fù)載,而不僅僅只是SQL分析,因此可以進(jìn)一步拓展其價值。此外,從上述基準(zhǔn)測試結(jié)果可以看出,與傳統(tǒng)分析數(shù)據(jù)庫相比,Impala還提供了領(lǐng)先的性能。無論整體性能還是大規(guī)模運算以及不斷激增的并發(fā)性工作負(fù)載能力方面,分析數(shù)據(jù)庫群(Impala、Greenplum)和SQL-on-Hadoop組群(Hive,Presto,Spark)之間的差異也變得非常明顯。雖然其他SQL-on-Hadoop引擎不能滿足分析數(shù)據(jù)庫工作負(fù)載的要求,但這并不意味著對其他工作負(fù)載沒有價值。事實上,絕大多數(shù)Cloudera客戶充分利用平臺的開放架構(gòu),通過Hive準(zhǔn)備數(shù)據(jù),通過Spark建立和測試模型,通過Impala運行商務(wù)智能(BI)并提供報告,而無需在不同的孤島中復(fù)制數(shù)據(jù)。
在接下來的一年中,我們將以Impala為核心繼續(xù)推動現(xiàn)代化分析數(shù)據(jù)庫的重大性能改進(jìn),包括增加商務(wù)智能(BI)體驗的智能化和自動化,并且不斷擴(kuò)大云計算支持,進(jìn)一步提高多租戶能力和可擴(kuò)展性。請點擊此博客了解更多詳情。
像往常一樣,我們鼓勵您通過基于開放式基準(zhǔn)測試工具包運行您自己的基準(zhǔn)測試以獨立驗證這些結(jié)果。
















