你真的懂TensorFlow嗎?Tensor是神馬?為什么還會Flow?
也許你已經下載了TensorFlow,而且準備開始著手研究深度學習。但是你會疑惑:TensorFlow里面的Tensor,也就是“張量”,到底是個什么鬼?也許你查閱了維基百科,而且現在變得更加困惑。也許你在NASA教程中看到它,仍然不知道它在說些什么?問題在于大多數講述張量的指南,都假設你已經掌握他們描述數學的所有術語。
別擔心!
我像小孩子一樣討厭數學,所以如果我能明白,你也可以!我們只需要用簡單的措辭來解釋這一切。所以,張量(Tensor)是什么,而且為什么會流動(Flow)?
讓我們先來看看tensor(張量)是什么?
張量=容器
張量是現代機器學習的基礎。它的核心是一個數據容器,多數情況下,它包含數字,有時候它也包含字符串,但這種情況比較少。因此把它想象成一個數字的水桶。
張量有多種形式,首先讓我們來看最基本的形式,你會在深度學習中偶然遇到,它們在0維到5維之間。我們可以把張量的各種類型看作這樣(對被題目中的貓咪吸引進來小伙伴說一句,不要急!貓咪在后面會出現哦!):

0維張量/標量
裝在張量/容器水桶中的每個數字稱為“標量”。
標量是一個數字。
你會問為什么不干脆叫它們一個數字呢?
我不知道,也許數學家只是喜歡聽起來酷?標量聽起來確實比數字酷。
實際上,你可以使用一個數字的張量,我們稱為0維張量,也就是一個只有0維的張量。它僅僅只是帶有一個數字的水桶。想象水桶里只有一滴水,那就是一個0維張量。
本教程中,我將使用Python,Keras,TensorFlow和Python庫Numpy。在Python中,張量通常存儲在Nunpy數組,Numpy是在大部分的AI框架中,一個使用頻率非常高的用于科學計算的數據包。

你將在Kaggle(數據科學競賽網站)上經常看到Jupyter Notebooks(安裝見文末閱讀鏈接,“數學爛也要學AI:帶你造一個經濟試用版AI終極必殺器”)關于把數據轉變成Numpy數組。Jupyter notebooks本質上是由工作代碼標記嵌入。可以認為它把解釋和程序融為一體。
我們為什么想把數據轉換為Numpy數組?
很簡單。因為我們需要把所有的輸入數據,如字符串文本,圖像,股票價格,或者視頻,轉變為一個統一得標準,以便能夠容易的處理。
這樣我們把數據轉變成數字的水桶,我們就能用TensorFlow處理。
它僅僅是組織數據成為可用的格式。在網頁程序中,你也許通過XML表示,所以你可以定義它們的特征并快速操作。同樣,在深度學習中,我們使用張量水桶作為基本的樂高積木。
1維張量/向量
如果你是名程序員,那么你已經了解,類似于1維張量:數組。
每個編程語言都有數組,它只是單列或者單行的一組數據塊。在深度學習中稱為1維張量。張量是根據一共具有多少坐標軸來定義。1維張量只有一個坐標軸。
1維張量稱為“向量”。
我們可以把向量視為一個單列或者單行的數字。

如果想在Numpy得出此結果,按照如下方法:

我們可以通過NumPy’s ndim函數,查看張量具有多個坐標軸。我們可以嘗試1維張量。

2維張量
你可能已經知道了另一種形式的張量,矩陣——2維張量稱為矩陣

不,這不是基努·里維斯(Keanu Reeves)的電影《黑客帝國》,想象一個excel表格。
我們可以把它看作為一個帶有行和列的數字網格。
這個行和列表示兩個坐標軸,一個矩陣是二維張量,意思是有兩維,也就是有兩個坐標軸的張量。
在Numpy中,我們可以如下表示:
- x = np.array([[5,10,15,30,25],
- [20,30,65,70,90],
- [7,80,95,20,30]])
我們可以把人的特征存儲在一個二維張量。有一個典型的例子是郵件列表。
比如我們有10000人,我們有每個人的如下特性和特征:
- First Name(名)
- Last Name(姓)
- Street Address(街道地址)
- City(城市)
- State(州/省)
- Country(國家)
- Zip(郵政編碼)
這意味著我們有10000人的七個特征。
張量具有“形狀”,它的形狀是一個水桶,即裝著我們的數據也定義了張量的最大尺寸。我們可以把所有人的數據放進二維張量中,它是(10000,7)。
你也許想說它有10000列,7行。
不。
張量能夠被轉換和操作,從而使列變為行或者行變為列。
3維張量
這時張量真正開始變得有用,我們經常需要把一系列的二維張量存儲在水桶中,這就形成了3維張量。
在NumPy中,我們可以表示如下:
- x = np.array([[[5,10,15,30,25],
- [20,30,65,70,90],
- [7,80,95,20,30]]
- [[3,0,5,0,45],
- [12,-2,6,7,90],
- [18,-9,95,120,30]]
- [[17,13,25,30,15],
- [23,36,9,7,80],
- [1,-7,-5,22,3]]])
你已經猜到,一個三維張量有三個坐標軸,可以這樣看到:
- x.ndim
輸出為:
- 3
讓我們再看一下上面的郵件列表,現在我們有10個郵件列表,我們將存儲2維張量在另一個水桶里,創建一個3維張量,它的形狀如下:
- (number_of_mailing_lists, number_of_people, number_of_characteristics_per_person)
- (10,10000,7)
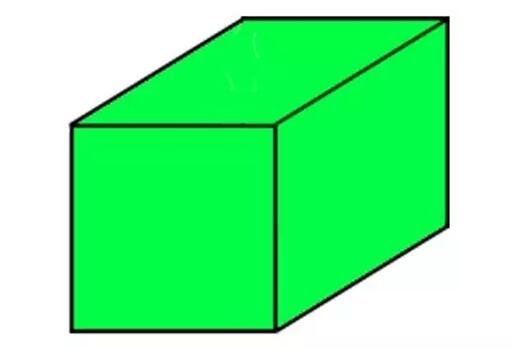
你也許已經猜到它,但是一個3維張量是一個數字構成的立方體。
我們可以繼續堆疊立方體,創建一個越來越大的張量,來編輯不同類型的數據,也就是4維張量,5維張量等等,直到N維張量。N是數學家定義的未知數,它是一直持續到無窮集合里的附加單位。它可以是5,10或者無窮。
實際上,3維張量最好視為一層網格,看起來有點像下圖:

存儲在張量數據中的公式
這里有一些存儲在各種類型張量的公用數據集類型:
- 3維=時間序列
- 4維=圖像
- 5維=視頻
幾乎所有的這些張量的共同之處是樣本量。樣本量是集合中元素的數量,它可以是一些圖像,一些視頻,一些文件或者一些推特。
通常,真實的數據至少是一個數據量。
把形狀里不同維數看作字段。我們找到一個字段的最小值來描述數據。
因此,即使4維張量通常存儲圖像,那是因為樣本量占據張量的第4個字段。
例如,一個圖像可以用三個字段表示:
- (width, height, color_depth) = 3D
但是,在機器學習工作中,我們經常要處理不止一張圖片或一篇文檔——我們要處理一個集合。我們可能有10,000張郁金香的圖片,這意味著,我們將用到4D張量,就像這樣:

- (sample_size, width, height, color_depth) = 4D
我們來看看一些多維張量存儲模型的例子:
時間序列數據
用3D張量來模擬時間序列會非常有效!
醫學掃描——我們可以將腦電波(EEG)信號編碼成3D張量,因為它可以由這三個參數來描述:
- (time, frequency, channel)
這種轉化看起來就像這樣:
如果我們有多個病人的腦電波掃描圖,那就形成了一個4D張量:
- (sample_size, time, frequency, channel)
- Stock Prices
在交易中,股票每分鐘有最高、最低和最終價格。如下圖的蠟燭圖所示:
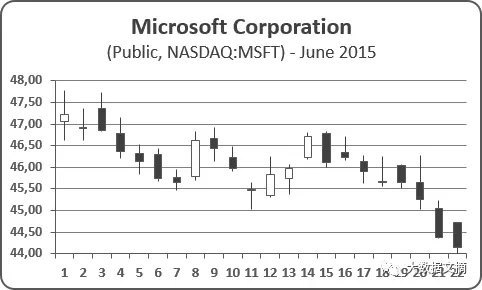
紐交所開市時間從早上9:30到下午4:00,即6.5個小時,總共有6.5 x 60 = 390分鐘。如此,我們可以將每分鐘內最高、最低和最終的股價存入一個2D張量(390,3)。如果我們追蹤一周(五天)的交易,我們將得到這么一個3D張量:
- (week_of_data, minutes, high_low_price)
即:
- (5,390,3)
同理,如果我們觀測10只不同的股票,觀測一周,我們將得到一個4D張量
- (10,5,390,3)
假設我們在觀測一個由25只股票組成的共同基金,其中的每只股票由我們的4D張量來表示。那么,這個共同基金可以有一個5D張量來表示:
- (25,10,5,390,3)
文本數據
我們也可以用3D張量來存儲文本數據,我們來看看推特的例子。
首先,推特有140個字的限制。其次,推特使用UTF-8編碼標準,這種編碼標準能表示百萬種字符,但實際上我們只對前128個字符感興趣,因為他們與ASCII碼相同。所以,一篇推特文可以包裝成一個2D向量:
- (140,128)
如果我們下載了一百萬篇川普哥的推文(印象中他一周就能推這么多),我們就會用3D張量來存:
- (number_of_tweets_captured, tweet, character)
這意味著,我們的川普推文集合看起來會是這樣:
- (1000000,140,128)
圖片
4D張量很適合用來存諸如JPEG這樣的圖片文件。之前我們提到過,一張圖片有三個參數:高度、寬度和顏色深度。一張圖片是3D張量,一個圖片集則是4D,第四維是樣本大小。
著名的MNIST數據集是一個手寫的數字序列,作為一個圖像識別問題,曾在幾十年間困擾許多數據科學家。現在,計算機能以99%或更高的準確率解決這個問題。即便如此,這個數據集仍可以當做一個優秀的校驗基準,用來測試新的機器學習算法應用,或是用來自己做實驗。

Keras 甚至能用以下語句幫助我們自動導入MNIST數據集:
- from keras.datasets import mnist
- (train_images, train_labels), (test_images, test_labels) = mnist.load_data()
這個數據集被分成兩個部分:訓練集和測試集。數據集中的每張圖片都有一個標簽。這個標簽寫有正確的讀數,例如3,7或是9,這些標簽都是通過人工判斷并填寫的。
訓練集是用來訓練神經網絡學習算法,測試集則用來校驗這個學習算法。
MNIST圖片是黑白的,這意味著它們可以用2D張量來編碼,但我們習慣于將所有的圖片用3D張量來編碼,多出來的第三個維度代表了圖片的顏色深度。
MNIST數據集有60,000張圖片,它們都是28 x 28像素,它們的顏色深度為1,即只有灰度。
TensorFlow這樣存儲圖片數據:
- (sample_size, height, width, color_depth).
于是我們可以認為,MNIST數據集的4D張量是這樣的:
- (60000,28,28,1)
彩色圖片
彩色圖片有不同的顏色深度,這取決于它們的色彩(注:跟分辨率沒有關系)編碼。一張典型的JPG圖片使用RGB編碼,于是它的顏色深度為3,分別代表紅、綠、藍。
這是一張我美麗無邊的貓咪(Dove)的照片,750 x750像素,這意味著我們能用一個3D張量來表示它:
- (750,750,3)

My beautiful cat Dove (750 x 750 pixels)
這樣,我可愛的Dove將被簡化為一串冷冰冰的數字,就好像它變形或流動起來了。

然后,如果我們有一大堆不同類型的貓咪圖片(雖然都沒有Dove美),也許是100,000張吧,不是DOVE它的,750 x750像素的。我們可以在Keras中用4D張量來這樣定義:
- (10000,750,750,3)
5D張量
5D張量可以用來存儲視頻數據。TensorFlow中,視頻數據將如此編碼:
- (sample_size, frames, width, height, color_depth)
如果我們考察一段5分鐘(300秒),1080pHD(1920 x 1080像素),每秒15幀(總共4500幀),顏色深度為3的視頻,我們可以用4D張量來存儲它:
- (4500,1920,1080,3)
當我們有多段視頻的時候,張量中的第五個維度將被使用。如果我們有10段這樣的視頻,我們將得到一個5D張量:
- (10,4500,1920,1080,3)
實際上這個例子太瘋狂了!
這個張量的大是很荒謬的,超過1TB。我們姑且考慮下這個例子以便說明一個問題:在現實世界中,我們有時需要盡可能的縮小樣本數據以方便的進行處理計算,除非你有無盡的時間。
這個5D張量中值的數量為:
10 x 4500 x 1920 x 1080 x 3 = 279,936,000,000
在Keras中,我們可以用一個叫dype的數據類型來存儲32bits或64bits的浮點數
我們5D張量中的每一個值都將用32 bit來存儲,現在,我們以TB為單位來進行轉換:
279,936,000,000 x 32 = 8,957,952,000,000
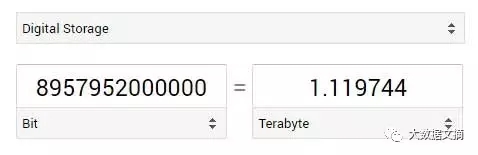
這還只是保守估計,或許用32bit來儲存根本就不夠(誰來計算一下如果用64bit來存儲會怎樣),所以,減小你的樣本吧朋友。
事實上,我舉出這最后一個瘋狂的例子是有特殊目的的。我們剛學過數據預處理和數據壓縮。你不能什么工作也不做就把大堆數據扔向你的AI模型。你必須清洗和縮減那些數據讓后續工作更簡潔更高效。
降低分辨率,去掉不必要的數據(也就是去重處理),這大大縮減了幀數,等等這也是數據科學家的工作。如果你不能很好地對數據做這些預處理,那么你幾乎做不了任何有意義的事。
結論
好了,現在你已經對張量和用張量如何對接不同類型數據有了更好的了解。
原文:https://hackernoon.com/learning-ai-if-you-suck-at-math-p4-tensors-illustrated-with-cats-27f0002c9b32
【本文是51CTO專欄機構大數據文摘的原創譯文,微信公眾號“大數據文摘( id: BigDataDigest)”】