意想不到的MySQL復制延遲原因
導讀
線上有個MySQL實例,存在嚴重的復制延遲問題,原因出乎意料。
線上有個MySQL 5.7版本的實例,從服務器延遲了3萬多秒,而且延遲看起來好像還在加劇。
MySQL版本
- Server version: 5.7.18-log MySQL Community Server (GPL)
看下延遲狀況
- yejr@imysql.com:mysql3306.sock : (none) > show slave status\G
- Master_Log_File: mysql-bin.013225
- Read_Master_Log_Pos: 1059111551
- Relay_Master_Log_File: mysql-bin.013161
- Exec_Master_Log_Pos: 773131396
- Master_UUID: e7c35a95-ffb1-11e6-9620-90e2babb5b90
我們看到,binlog文件落后了64個,相當的夸張。
MySQL 5.7不是已經實現并行復制了嗎,怎么還會延遲這么厲害?
先檢查系統負載。
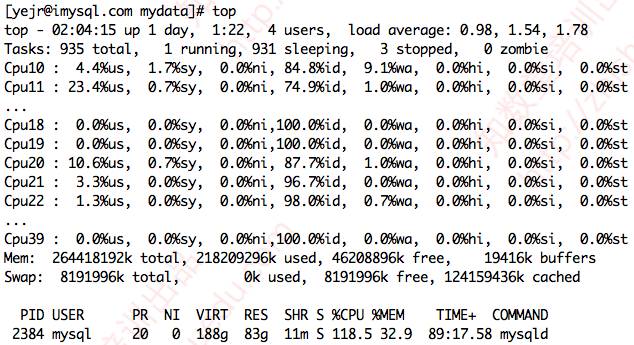
看到mysqld進程其實負載還好,不算太高,也不存在嚴重的SWAP等問題。
再看I/O子系統負載,沒看到這方面存在瓶頸(await\svctm\%util都不高)。

再看mysqld進程的CPU消耗。
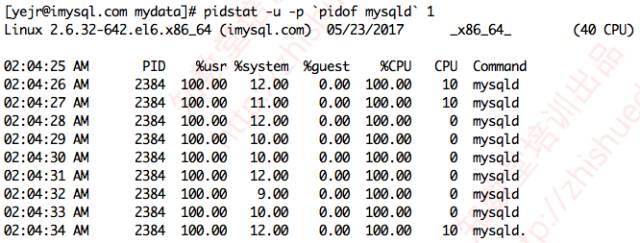
雖然mysqld進程的CPU消耗總是超過100%,不過也不算太高。
再檢查MySQL復制現場,確認了幾個頻繁更新的表都有主鍵,以及必要的索引。相應的DML操作也幾乎都是基于主鍵或唯一索引條件執行的,排除無主鍵、無合理索引方面的因素。
***只能祭出perf top神器了。
perf top -p `pidof mysqld`
看到perf top***的報告是這樣的
- Samples: 107K of event 'cycles', Event count (approx.): 29813195000
- Overhead Shared Object Symbol
- 56.19% mysqld [.] bitmap_get_next_set
- 16.18% mysqld [.] build_template_field
- 4.61% mysqld [.] ha_innopart::try_semi_consistent_read
- 4.44% mysqld [.] dict_index_copy_types
- 4.16% libc-2.12.so [.] __memset_sse2
- 2.92% mysqld [.] ha_innobase::build_template
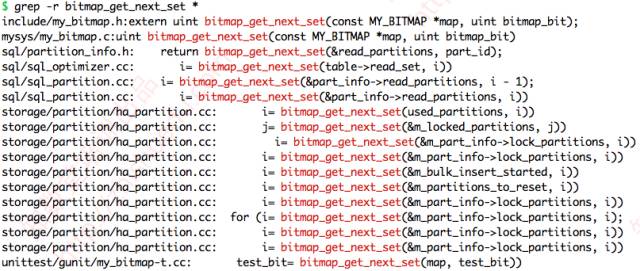
我們看到, bitmap_get_next_set 這個函數調用占到了 56.19%,非常高,其次是 build_template_field 函數,占了 16.18%。
經過檢查MySQL源碼并請教MySQL內核開發專家,***確認這兩個函數跟啟用表分區有關系。
查詢下當前實例有多少個表分區:
- yejr@imysql.com:mysql3306.sock : (none) > select count(*) from partitions where partition_name is not null;
- +----------+
- | count(*) |
- +----------+
- | 32128 |
- +----------+
- 1 row in set (11.92 sec)
額滴神啊,竟然有3萬多個表分區,難怪上面那兩個函數調用那么高。
這個業務數據庫幾個大表采用每天一個分區方案,而且把直到當年年底所有分區也都給提前創建好了,所以才會有這么多。
不過,雖然有這么多表分區,在master服務器上卻不存在這個瓶頸,看起來是在主從復制以及大量表分區的綜合因素下才有這個瓶頸,最終導致主從復制延遲越來越嚴重。
知道問題所在,解決起來就簡單了。把到下個月底前用不到的表分區全部刪除,之后約只剩下1.6萬個分區。重啟slave線程,問題解決,主從復制延遲很快就消失了。