數據科學家用得最多的十種數據挖掘算法

圖 1 :數據科學家使用度***的 10 大算法
文末有全部算法的集合列表
每個受訪者平均使用 8.1 個算法,這相比于 2011 的相似調查顯示的結果有了巨大的增長
與 2011 年關于數據分析/數據挖掘的調查相比,我們注意到最常用的方法仍然是回歸、聚類、決策樹/Rules 和可視化。相對來說***的增長是由 (pct2016 /pct2011 – 1) 測定的以下算法:
- Boosting,從 2011 年的 23.5% 至 2016 年的 32.8%,同比增長 40%
- 文本挖掘,從 2011 年的 27.7% 至 2016 年的 35.9%,同比增長 30%
- 可視化,從 2011 年的 38.3% 至 2016 年的 48.7%,同比增長 27%
- 時間序列/序列分析,從 2011 年的 29.6% 至 2016 年的 37.0%,同比增長 25%
- 異常/偏差檢測,從 2011 年的 16.4% 至 2016 年的 19.5%,同比增長 19%
- 集成方法,從 2011 年的 28.3%至 2016 年的 33.6%,同比增長 19%
- 支持向量機,從 2011 年的 28.6% 至 2016 年的 33.6%,同比增長 18%
- 回歸,從 2011 年的 57.9% 至 2016 年的 67.1%,同比增長 16%
***算法在 2016 年的調查中有了新的上榜名單:
- K-近鄰,46%
- 主成分分析,43%
- 隨機森林,38%
- 優化,24%
- 神經網絡 – 深度學習,19%
- 奇異值分解,16%
***幅下降的有:
- 關聯規則,從 2011 年的 28.6% 至 2016 年的 15.3%,同比下降 47%
- 隆起造型,從 2011 年的 4.8% 至 2016 年的 3.1%,同比下降 36%
- 因素分析,從 2011 年的 18.6% 至 2016 年的 14.2%,同比下降 24%
- 生存分析,從 2011 年的 9.3% 至 2016 年的 7.9%,同比下降 15%
下表顯示了不同的算法類型的使用:監督算法、無監督算法、元算法,以及職業類型決定的對算法的使用。我們排除 NA(4.5%)和其他(3%)的職業類型。
職業類型% 投票者比例平均算法使用個數% 監督算法使用度% 無監督算法使用度% 元使用度%其他方法使用度
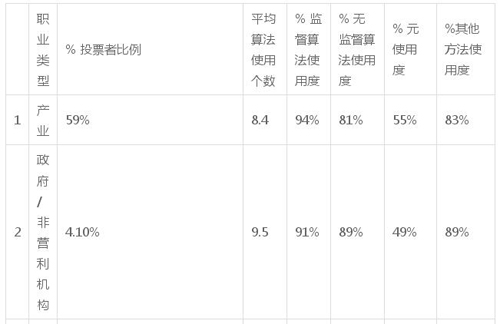
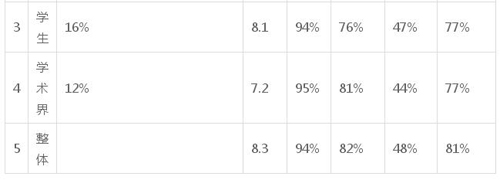
表 1:根據職業類型顯示的不同算法使用度
我們注意到,幾乎每個人都使用監督學習算法。
政府和產業業數據科學家比學生和學術研究人員使用更多不同類型的算法,而產業數據科學家們更傾向于使用元算法。
接下來,我們根據職業類型分析了前 10 名的算法+深度學習使用情況。
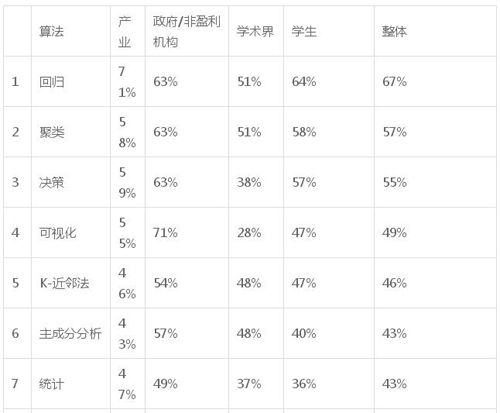
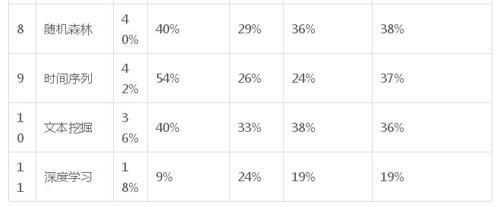
表 2:根據職業類型分類的 10 大算法+深度學習使用情況
為了更明顯的看到差異,我們計算了具體職業分類相比于平均算法使用度的一個算法偏差,即偏差(ALG,類型)=使用(ALG,類型)/使用(ALG,所有的)
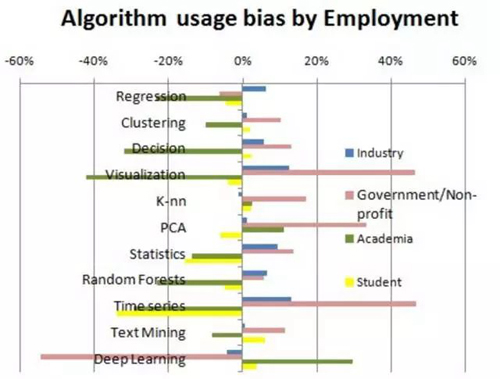
圖 2:職業對算法的使用偏好
我們注意到,產業數據科學家們更傾向于使用回歸、可視化、統計、隨機森林和時間序列。政府/非營利更傾向于使用可視化、主成分分析和時間序列。學術研究人員更傾向于使用主成分分析和深度學習。學生普遍使用更少的算法,但多為文本挖掘和深度學習。
接下來,我們看看某一具體地域的參與度,表示整體的 KDnuggets 的用戶:
- 美國/加拿大,40%
- 歐洲,32%
- 亞洲,18%
- 拉丁美洲,5%
- 非洲/中東,3.4%
- 澳洲/新西蘭,2.2%
由于在 2011 年的調查中,我們將產業/政府分在了一組,而將學術研究/學生分在了第二組,并計算了算法對于業界/政府的親切度:
- N(Alg,Ind_Gov) / N(Alg,Aca_Stu)
- ------------------------------- - 1
- N(Ind_Gov) / N(Aca_Stu)
因此親切度為 0 的算法表示它在產業/政府和學術研究人員或學生之間的使用情況對等。越高 IG 親切度表示算法越被產業界普遍使用,反之越接近「學術」。
最「產業」的算法是:
- 異常檢測,1.61
- 生存分析,1.39
- 因子分析,0.83
- 時間序列/序列,0.69
- 關聯規則,0.5
而 uplifting modeling 又是最「產業的算法」,令人驚訝的發現是,它的使用率極低 – 只有 3.1% – 是本次調查的算法中***的。
最學術的算法是:
- 常規神經網絡,-0.35
- 樸素貝葉斯,-0.35
- 支持向量機,-0.24
- 深度學習,-0.19
- EM,-0.17
下圖顯示了所有的算法及其產業/學術親切度。
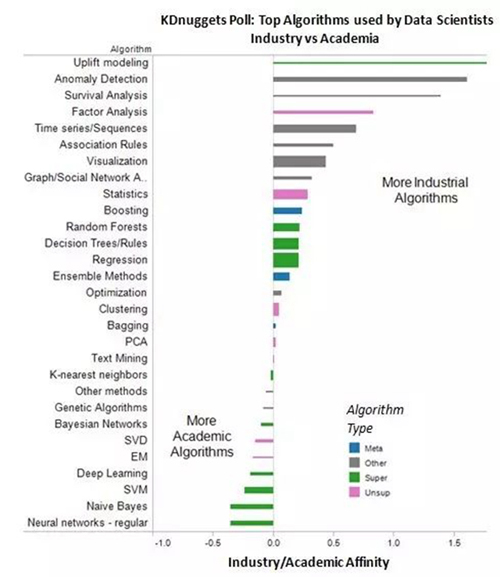
圖 3:KDnuggets 投票:最常被數據科學家使用的算法:產業界 VS 學術界
下表有關于算法的細節、兩次調查中使用算法的比例、以及像上面解釋的產業親切度。
接下來的圖表展示了算法的細節,按列
- N:根據使用度排名
- 算法:算法名稱,
- 類型:S – 監督,U – 無監督,M – 元,Z – 其他,
- 在 2016 年調查中使用這種算法的調查者比例
- 在 2011 年調查中使用這種算法的調查者比例
- 變動(%2016 年/2011% – 1),
- 產業親切度(如上所述)
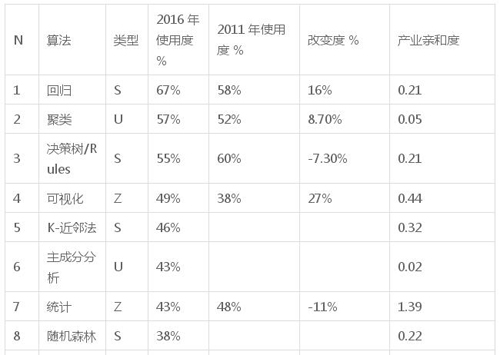
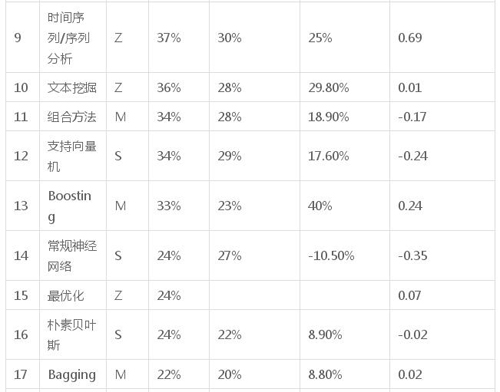
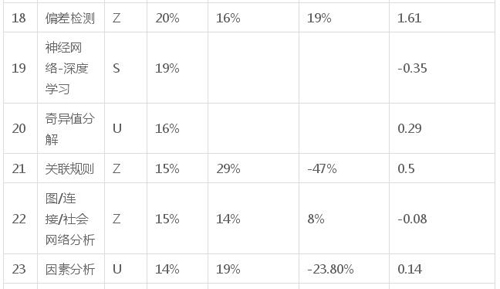
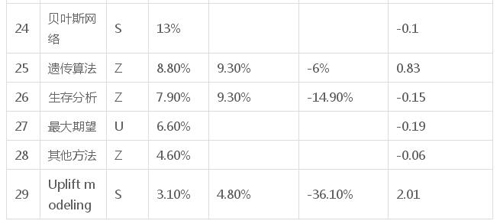
表 3:KDnuggets 2016 調查:數據科學家使用的算法