統計語言模型淺談
統計語言模型
統計語言模型(Statistical Language Model)即是用來描述詞、語句乃至于整個文檔這些不同的語法單元的概率分布的模型,能夠用于衡量某句話或者詞序列是否符合所處語言環境下人們日常的行文說話方式。統計語言模型對于復雜的大規模自然語言處理應用有著非常重要的價值,它能夠有助于提取出自然語言中的內在規律從而提高語音識別、機器翻譯、文檔分類、光學字符識別等自然語言應用的表現。好的統計語言模型需要依賴大量的訓練數據,在上世紀七八十年代,基本上模型的表現優劣往往會取決于該領域數據的豐富程度。IBM 曾進行過一次信息檢索評測,發現二元語法模型(Bi-gram)需要數以億計的詞匯才能達到***表現,而三元語法模型(TriGram)則需要數十億級別的詞匯才能達成飽和。本世紀初,***的統計語言模型當屬 N-gram,其屬于典型的基于稀疏表示(Sparse Representation)的語言模型;近年來隨著深度學習的爆發與崛起,以詞向量(WordEmbedding)為代表的分布式表示(Distributed Representation)的語言模型取得了更好的效果,并且深刻地影響了自然語言處理領域的其他模型與應用的變革。除此之外,Ronald Rosenfeld[7] 還提到了基于決策樹的語言模型(Decision Tree Models)、***熵模型以及自適應語言模型(Adaptive Models)等。
統計語言模型可以用來表述詞匯序列的統計特性,譬如學習序列中單詞的聯合分布概率函數。如果我們用w1w1 到 wtwt 依次表示這句話中的各個詞,那么該句式的出現概率可以簡單表示為:
- P(w1,...,wt)=∏i=1tP(wi|w1,...,wi−1)=∏i=1tP(wi|Context)P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)(1)(1)P(w1,...,wt)=∏i=1tP(wi|w1,...,wi−1)=∏i=1tP(wi|Context)P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)
統計語言模型訓練目標也可以是采用極大似然估計來求取***化的對數似然,公式為1T∑Tt=1∑−c≤j≤c,j≠0logp(wt+j|wt)1T∑t=1T∑−c≤j≤c,j≠0logp(wt+j|wt)。其中cc是訓練上下文的大小。譬如cc取值為 5 的情況下,一次就拿 5 個連續的詞語進行訓練。一般來說cc越大,效果越好,但是花費的時間也會越多。p(wt+j|wt)p(wt+j|wt)表示wtwt條件下出現wt+jwt+j的概率。常見的對于某個語言模型度量的標準即是其困惑度(Perplexity),需要注意的是這里的困惑度與信息論中的困惑度并不是相同的含義。這里的困惑度定義公式參考Stolcke[11],為exp(−logP(wt)/|w⃗ |)exp(−logP(wt)/|w→|),即是1/P(wt|wt−11)1/P(wt|w1t−1)的幾何平均數。最小化困惑度的值即是***化每個單詞的概率,不過困惑度的值嚴重依賴于詞表以及具體使用的單詞,因此其常常被用作評判其他因素相同的兩個系統而不是通用的絕對性的度量參考。
N-gram 語言模型
參照上文的描述,在統計學語言模型中我們致力于計算某個詞序列E=wT1E=w1T的出現概率,可以形式化表示為:
- P(E)=P(|E|=T,wT1)(2)(2)P(E)=P(|E|=T,w1T)
上式中我們求取概率的目標詞序列EE的長度為TT,序列中***個詞為w1w1,第二個詞為w2w2,等等,直到***一個詞為wTwT。上式非常直觀易懂,不過在真實環境下卻是不可行的,因為序列的長度TT是未知的,并且詞表中詞的組合方式也是非常龐大的數目,無法直接求得。為了尋找實際可行的簡化模型,我們可以將整個詞序列的聯合概率復寫為單個詞或者單個詞對的概率連乘。即上述公式可以復寫為P(w1,w2,w3)=P(w1)P(w2|w1)P(w3|w1,w2)P(w1,w2,w3)=P(w1)P(w2|w1)P(w3|w1,w2),推導到通用詞序列,我們可以得到如下形式化表示:
- P(E)=∏t=1T+1P(wt|wt−11)(3)(3)P(E)=∏t=1T+1P(wt|w1t−1)
此時我們已經將整個詞序列的聯合概率分解為近似地求 P(wt|w1,w2,…,wt−1)P(wt|w1,w2,…,wt−1)。而這里要討論的 N-gram 模型就是用 P(wt|wt−n+1,…,wt−1)P(wt|wt−n+1,…,wt−1) 近似表示前者。根據NN的取值不同我們又可以分為一元語言模型(Uni-gram)、二元語言模型(Bi-gram)、三元語言模型(Tri-gram)等等類推。該模型在中文中被稱為漢語語言模型(CLM, Chinese Language Model),即在需要把代表字母或筆畫的數字,或連續無空格的拼音、筆畫,轉換成漢字串(即句子)時,利用上下文中相鄰詞間的搭配信息,計算出***概率的句子;而不需要用戶手動選擇,避開了許多漢字對應一個相同的拼音(或筆畫串、數字串)的重碼問題。
一元語言模型又稱為上下文無關語言模型,是一種簡單易實現但實際應用價值有限的統計語言模型。該模型不考慮該詞所對應的上下文環境,僅考慮當前詞本身的概率,即是 N-gram 模型中當N=1N=1的特殊情形。
- p(wt|Context)=p(wt)=NwtN(4)(4)p(wt|Context)=p(wt)=NwtN
N-gram 語言模型也存在一些問題,這種模型無法建模出詞之間的相似度,有時候兩個具有某種相似性的詞,如果一個詞經常出現在某段詞之后,那么也許另一個詞出現在這段詞后面的概率也比較大。比如“白色的汽車”經常出現,那完全可以認為“白色的轎車”也可能經常出現。N-gram 語言模型無法建模更遠的關系,語料的不足使得無法訓練更高階的語言模型。大部分研究或工作都是使用 Tri-gram,就算使用高階的模型,其統計 到的概率可信度就大打折扣,還有一些比較小的問題采用 Bi-gram。訓練語料里面有些 n 元組沒有出現過,其對應的條件概率就是 0,導致計算一整句話的概率為 0。最簡單的計算詞出現概率的方法就是在準備好的訓練集中計算固定長度的詞序列的出現次數,然后除以其所在上下文的次數;譬如以 Bi-gram 為例,我們有下面三條訓練數據:
- i am from jiangsu.
- i study at nanjing university.
- my mother is from yancheng.
我們可以推導出詞 am, study 分別相對于 i 的后驗概率:
- p(w2=am|w1=i)=w1=i,w2=amc(w1=1)=12=0.5p(w2=study|w1=i)=w1=i,w2=studyc(w1=1)=12=0.5(5)
- (5)p(w2=am|w1=i)=w1=i,w2=amc(w1=1)=12=0.5p(w2=study|w1=i)=w1=i,w2=studyc(w1=1)=12=0.5
上述的計算過程可以推導為如下的泛化公式:
- PML(wt|wt−11)=cprefix(wt1)cprefix(wt−11)(6)(6)PML(wt|w1t−1)=cprefix(w1t)cprefix(w1t−1)
這里cprefix(⋅)cprefix(⋅)表示指定字符串在訓練集中出現的次數,這種方法也就是所謂的***似然估計(Maximum Likelihood Estimation);該方法十分簡單易用,同時還能保證較好地利用訓練集中的統計特性。根據這個方法我們同樣可以得出 Tri-gram 模型似然計算公式如下:
- P(wt|wt−2,wt−1)=count(wt−2wt−1wt)count(wt−2wt−1)(7)(7)P(wt|wt−2,wt−1)=count(wt−2wt−1wt)count(wt−2wt−1)
我們將 N-gram 模型中的參數記作θθ,其包含了給定前n−1n−1個詞時第nn個詞出現的概率,形式化表示為:
- θwtt−n+1=PML(wt|wt−1t−n+1)=c(wtt−n+1)c(wt−1t−n+1)(8)(8)θwt−n+1t=PML(wt|wt−n+1t−1)=c(wt−n+1t)c(wt−n+1t−1)
樸素的 N-gram 模型中對于訓練集中尚未出現過的詞序列會默認其概率為零 ,因為我們的模型是多個詞概率的連乘,最終會導致整個句式的概率為零。我們可以通過所謂的平滑技巧來解決這個問題,即組合對于不同的NN取值來計算平均概率。譬如我們可以組合 Uni-gram 模型與 Bi-gram 模型:
- P(wt|wt−1)=(1−α)PML(wt|wt−1)+αPML(wt)(9)(9)P(wt|wt−1)=(1−α)PML(wt|wt−1)+αPML(wt)
其中αα表示分配給 Uni-gram 求得的概率的比重,如果我們設置了α>0α>0,那么詞表中的任何詞都會被賦予一定的概率。這種方法即是所謂的插入平滑(Interpolation),被應用在了很多低頻稀疏的模型中以保證其魯棒性。當然,我們也可以引入更多的NN的不同的取值,整個組合概率遞歸定義如下:
- P(wt|wt−1t−m+1)=(1−αm)PML(wt|wt−1t−m+1)+αmP(wt|wt−1t−m+2)(10)(10)P(wt|wt−m+1t−1)=(1−αm)PML(wt|wt−m+1t−1)+αmP(wt|wt−m+2t−1)
[Stanley et al., 1996] 中還介紹了很多其他復雜但精致的平滑方法,譬如基于上下文的平滑因子計算(Context-dependent Smoothing Coefficients),其并沒有設置固定的αα值,而是動態地設置為αwt−1t−m+1αwt−m+1t−1。這就保證了模型能夠在有較多的訓練樣例時將更多的比重分配給高階的 N-gram 模型,而在訓練樣例較少時將更多的比重分配給低階的 N-gram 模型。目前公認的使用最為廣泛也最有效的平滑方式也是 [Stanley et al., 1996] 中提出的 Modified Kneser-Ney smoothing( MKN ) 模型,其綜合使用了上下文平滑因子計算、打折以及低階分布修正等手段來保證較準確地概率估計。
神經網絡語言模型
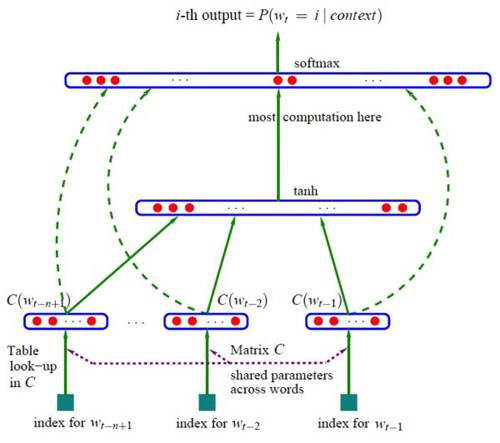
顧名思義,神經網絡語言模型(Neural Network Language Model)即是基于神經網絡的語言模型,其能夠利用神經網絡在非線性擬合方面的能力推導出詞匯或者文本的分布式表示。在神經網絡語言模型中某個單詞的分布式表示會被看做激活神經元的向量空間,其區別于所謂的局部表示,即每次僅有一個神經元被激活。標準的神經網絡語言模型架構如下圖所示:
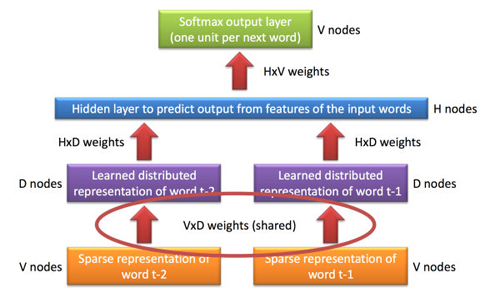
神經網絡語言模型中***的當屬 Bengio[10] 中提出的概率前饋神經網絡語言模型(Probabilistic Feedforward Neural Network Language Model),它包含了輸入(Input)、投影(Projection)、隱藏(Hidden)以及輸出(Output)這四層。在輸入層中,會從VV個單詞中挑選出NN個單詞以下標進行編碼,其中VV是整個詞表的大小。然后輸入層會通過N×DN×D這個共享的投影矩陣投射到投影層PP;由于同一時刻僅有NN個輸入值處于激活狀態,因此這個計算壓力還不是很大。NNLM 模型真正的計算壓力在于投影層與隱層之間的轉換,譬如我們選定N=10N=10,那么投影層PP的維度在 500 到 2000 之間,而隱層HH的維度在于500500到10001000之間。同時,隱層HH還負責計算詞表中所有單詞的概率分布,因此輸出層的維度也是VV。綜上所述,整個模型的訓練復雜度為:
- Q=N×D+N×D×H+H×VQ=N×D+N×D×H+H×V
其訓練集為某個巨大但固定的詞匯集合VV 中的單詞序列w1...wtw1...wt;其目標函數為學習到一個好的模型f(wt,wt−1,…,wt−n+2,wt−n+1)=p(wt|wt−11)f(wt,wt−1,…,wt−n+2,wt−n+1)=p(wt|w1t−1),約束為f(wt,wt−1,…,wt−n+2,wt−n+1)>0f(wt,wt−1,…,wt−n+2,wt−n+1)>0并且Σ|V|i=1f(i,wt−1,…,wt−n+2,wt−n+1)=1Σi=1|V|f(i,wt−1,…,wt−n+2,wt−n+1)=1。每個輸入詞都被映射為一個向量,該映射用CC表示,所以C(wt−1)C(wt−1)即為wt−1wt−1的詞向量。定義gg為一個前饋或者遞歸神經網絡,其輸出是一個向量,向量中的第ii個元素表示概率p(wt=i|wt−11)p(wt=i|w1t−1)。訓練的目標依然是***似然加正則項,即:
- MaxLikelihood=max1T∑tlogf(wt,wt−1,…,wt−n+2,wt−n+1;θ)+R(θ)MaxLikelihood=max1T∑tlogf(wt,wt−1,…,wt−n+2,wt−n+1;θ)+R(θ)
其中θθ為參數,R(θ)R(θ)為正則項,輸出層采用sofamax函數:
- p(wt|wt−1,…,wt−n+2,wt−n+1)=eywt∑ieyip(wt|wt−1,…,wt−n+2,wt−n+1)=eywt∑ieyi
其中yiyi是每個輸出詞ii的未歸一化loglog概率,計算公式為y=b+Wx+Utanh(d+Hx)y=b+Wx+Utanh(d+Hx)。其中b,W,U,d,Hb,W,U,d,H都是參數,xx為輸入,需要注意的是,一般的神經網絡輸入是不需要優化,而在這里,x=(C(wt−1),C(wt−2),…,C(wt−n+1))x=(C(wt−1),C(wt−2),…,C(wt−n+1)),也是需要優化的參數。在圖中,如果下層原始輸入xx不直接連到輸出的話,可以令b=0b=0,W=0W=0。如果采用隨機梯度算法的話,梯度的更新規則為:
- θ+ϵ∂logp(wt|wt−1,…,wt−n+2,wt−n+1)∂θ→θθ+ϵ∂logp(wt|wt−1,…,wt−n+2,wt−n+1)∂θ→θ
其中ϵϵ為學習速率,需要注意的是,一般神經網絡的輸入層只是一個輸入值,而在這里,輸入層xx也是參數(存在CC中),也是需要優化的。優化結束之后,詞向量有了,語言模型也有了。這個 Softmax 模型使得概率取值為(0,1),因此不會出現概率為0的情況,也就是自帶平滑,無需傳統 N-gram 模型中那些復雜的平滑算法。Bengio 在 APNews 數據集上做的對比實驗也表明他的模型效果比精心設計平滑算法的普通 N-gram 算法要好10%到20%。
循環神經網絡語言模型
好的語言模型應當至少捕獲自然語言的兩個特征:語法特性與語義特性。為了保證語法的正確性,我們往往只需要考慮生成詞的前置上下文;這也就意味著語法特性往往是屬于局部特性。而語義的一致性則復雜了許多,我們需要考慮大量的乃至于整個文檔語料集的上下文信息來獲取正確的全局語義。神經網絡語言模型相較于經典的 N-gram 模型具有更強大的表現力與更好的泛化能力,不過傳統的 N-gram 語言模型與 [Bengio et al., 2003] 中提出的神經網絡語言模型都不能有效地捕獲全局語義信息。為了解決這個問題,[Mikolov et al., 2010; 2011] 中提出的基于循環神經網絡(Recurrent Neural Network, RNN)的語言模型使用了隱狀態來記錄詞序的歷史信息,其能夠捕獲語言中的長程依賴。在自然語言中,往往在句式中相隔較遠的兩個詞卻具備一定的語法與語義關聯,譬如He doesn't have very much confidence in himself 與 She doesn't have very much confidence in herself 這兩句話中的<He, himself>與<She, herself>這兩個詞對,盡管句子中間的詞可能會發生變化,但是這兩種詞對中兩個詞之間的關聯卻是固定的。這種依賴也不僅僅出現在英語中,在漢語、俄羅斯語中也都存在有大量此類型的詞對組合。而另一種長期依賴(Long-term Dependencies)的典型就是所謂的選擇限制(Selectional Preferences);簡而言之,選擇限制主要基于已知的某人會去做某事這樣的信息。譬如我要用叉子吃沙拉與我要和我的朋友一起吃沙拉這兩句話中,叉子指代的是某種工具,而我的朋友則是伴侶的意思。如果有人說我要用雙肩背包來吃沙拉就覺得很奇怪了,雙肩背包并不是工具也不是伴侶;如果我們破壞了這種選擇限制就會生成大量的無意義句子。***,某個句式或者文檔往往都會歸屬于某個主題下,如果我們在某個技術主題的文檔中突然發現了某個關于體育的句子,肯定會覺得很奇怪,這也就是所謂的破壞了主題一致性。
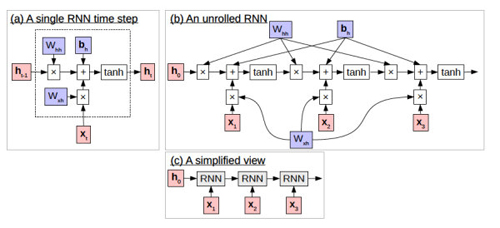
[Eriguchi et al., 2016] 中介紹的循環神經網絡在機器翻譯上的應用就很值得借鑒,它能夠有效地處理這種所謂長期依賴的問題。它的思想精髓在于計算新的隱狀態h⃗ h→時引入某個之前的隱狀態ht−1→ht−1→,形式化表述如下:
- h⃗ t={tanh(Wxhx⃗ t+Whhh⃗ t−1+b⃗ h),0,t ≥1,otherwises(11)(11)h→t={tanh(Wxhx→t+Whhh→t−1+b→h),t ≥1,0,otherwises
我們可以看出,在t≥1t≥1時其與標準神經網絡中隱層計算公式的區別在于多了一個連接Whhh⃗ t−1Whhh→t−1,該連接源于前一個時間點的隱狀態。在對于 RNN 有了基本的了解之后,我們就可以將其直接引入語言模型的構建中,即對于上文討論的神經網絡語言模型添加新的循環連接:
- m⃗ t=M⋅,wt−1h⃗ t={tanh(Wxhx⃗ t+Whhh⃗ t−1+b⃗ h),0,t ≥1,otherwisesp⃗ t=softmax(Whsh⃗ t+bs)(12)(12)m→t=M⋅,wt−1h→t={tanh(Wxhx→t+Whhh→t−1+b→h),t ≥1,0,otherwisesp→t=softmax(Whsh→t+bs)
注意,與上文介紹的前饋神經網絡語言模型相對,循環神經網絡語言模型中只是將前一個詞而不是前兩個詞作為輸入;這是因為我們假設wt−2wt−2的信息已經包含在了隱狀態ht−1→ht−1→中,因此不需要重復代入。
【本文是51CTO專欄作者“張梓雄 ”的原創文章,如需轉載請通過51CTO與作者聯系】