













深入淺出時序數(shù)據(jù)庫之壓縮篇
據(jù)庫之壓縮篇")
物聯(lián)網(wǎng)鄰域近期如火如荼,互聯(lián)網(wǎng)和傳統(tǒng)公司爭相布局物聯(lián)網(wǎng)。作為物聯(lián)網(wǎng)鄰域數(shù)據(jù)存儲的***時序數(shù)據(jù)庫也越來越多進(jìn)入人們的視野,而早在 2016 年 7 月,百度云在其天工物聯(lián)網(wǎng)平臺上發(fā)布了國內(nèi)***多租戶的分布式時序數(shù)據(jù)庫產(chǎn)品 TSDB,成為支持其發(fā)展制造,交通,能源,智慧城市等產(chǎn)業(yè)領(lǐng)域的核心產(chǎn)品,同時也成為百度戰(zhàn)略發(fā)展產(chǎn)業(yè)物聯(lián)網(wǎng)的標(biāo)志性事件。
壓縮對于時序數(shù)據(jù)庫是至關(guān)重要的。因為時序數(shù)據(jù)庫面對的物聯(lián)網(wǎng)場景每天都會產(chǎn)生上億條數(shù)據(jù)。眾所周知,在大數(shù)據(jù)時代的今天數(shù)據(jù)的重要性是不言而喻的,數(shù)據(jù)就是公司的未來。但如果無法對這些時序數(shù)據(jù)進(jìn)行很好的管理和壓縮,那將給客戶帶來非常高的成本壓力。
如前文提到的,工業(yè)物聯(lián)網(wǎng)環(huán)境監(jiān)控方向的客戶,一年產(chǎn)生 1P 的數(shù)據(jù),如果每臺服務(wù)器 10T 的硬盤,那么總共需要 100 多臺。按照每臺服務(wù)器 3 萬來算,一年就需要 300 萬的支出,這還不包括維護(hù)人員的成本。
壓縮是個非常大的話題,本文希望能夠先從大的宏觀角度給出一個輪廓,講述壓縮的本質(zhì),壓縮的可計算性問題。再從時序數(shù)據(jù)壓縮這一個垂直領(lǐng)域,給出無損壓縮和有損壓縮各一個例子進(jìn)行說明,希望能夠拋磚引玉。
壓縮的故事
先來講個有關(guān)壓縮的故事,外星人拜訪地球,看中了大英百科全書,想要把這套書帶回去。但這套書太大,飛船放不下。于是外星人根據(jù)飛船的長度,在飛船上畫了一個點。這樣外星人心滿意足的返回了自己的星球,因為這個點就存儲了整個大英百科全書。
這個并不是很嚴(yán)謹(jǐn)?shù)墓适拢瑓s道出了壓縮的本質(zhì):用計算時間換取存儲空間。外星人在飛船上畫的點非常有技術(shù)含量,可以說是黑科技,代表一個位數(shù)非常長的不循環(huán)小數(shù)。而這串?dāng)?shù)字正代表了整個大英百科全書的內(nèi)容。
壓縮的兩個問題
再來回答兩個宏觀的問題,幫助我們認(rèn)識在壓縮這件事上哪些是我們能做的,哪些是不能做的。
***個問題:是否存在一個通用的壓縮算法(Universal Compression),也就是說某個壓縮算法能夠壓縮任意的數(shù)據(jù)。答案是否定的,并不存在這樣的通用壓縮算法。
用反證法可以做個快速的證明。假設(shè)存在通用的壓縮算法,也就是說有個壓縮算法,對于長度為 n 的字符串,總能壓縮到長度小于 n 的字符串。總共有 2^n 個長度為 n 的不同字符串;但卻只有 2^n-1 個長度小于 n 的字符串。那么必定存在兩個長度為 n 的字符串 A,B,經(jīng)過壓縮得到同一個字符串。這樣解壓縮算法沒有辦法正確的解壓。所以假設(shè)錯誤,并不存在通用的壓縮算法。
第二個問題:是否能寫出一個函數(shù),輸入字符串,可以得到這個字符串最短表示的長度。答案也是否定的,也就是說我們無法證明某個算法是***的算法。柯爾莫哥洛夫復(fù)雜性的不可計算性解釋的就是這個問題。用的也是反證法,有興趣的朋友可以自行百度了解(注 1)。
這兩個問題的答案,告訴我們?nèi)虑椋?/p>
- 壓縮算法的選擇需要具體情況具體分析,不可壓縮的字符串總是存在。
- 不要妄圖獲得***的壓縮算法,它是不可計算的。因為總有你想不到的壓縮算法存在。舉個例子,[一百萬個 0 的字符串,以“foo”作為 key,經(jīng)過 AES 加密算法的 CBC 模式得到的字符串]。這串字符串看起來完全是隨機(jī)的,不可壓縮的。但我卻用 43 個中文(中括號之間的內(nèi)容)就表示了出來。
- 壓縮是件很難很有技術(shù)含量的事情,需要不斷的挖掘,才能將他做到更好。
時序數(shù)據(jù)壓縮
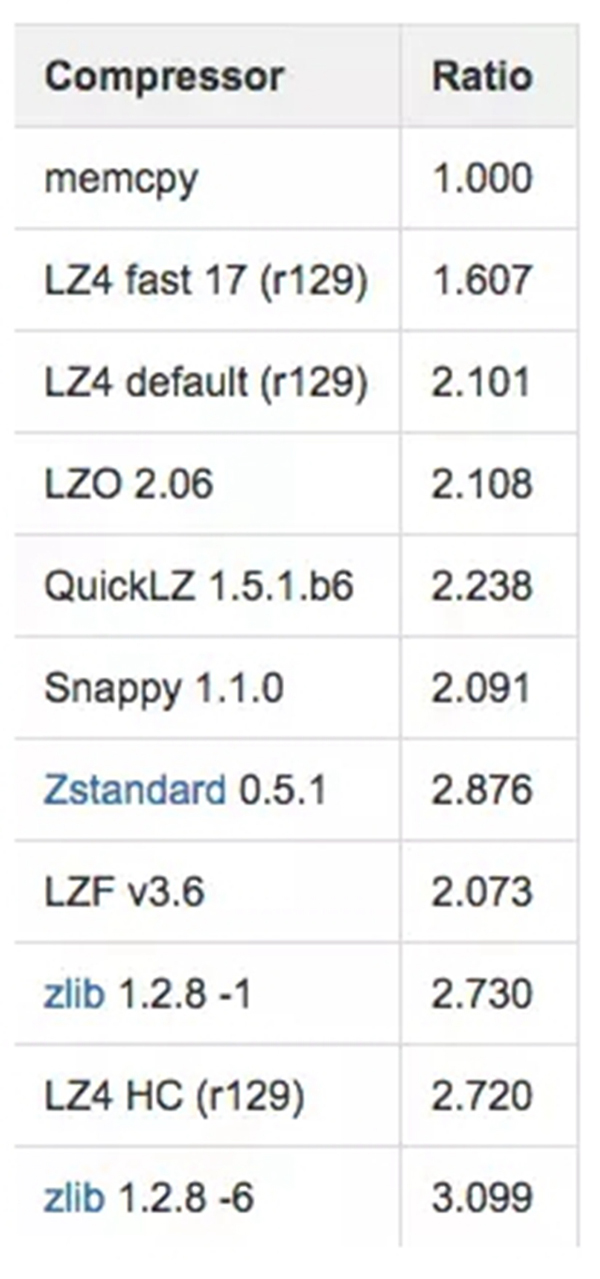
針對不同的數(shù)據(jù),會有不同的壓縮,大致壓縮的對象可以分為文檔、音頻、視頻等。如果直接采用文檔的壓縮算法用于時序數(shù)據(jù),效果并不理想。下圖是一些常用的壓縮算法的 benchmark,可以看到壓縮率那一欄***也只能夠達(dá)到 3 左右的壓縮率(壓縮率 = 原始數(shù)據(jù)大小 / 壓縮后的數(shù)據(jù)大小)。更多壓縮算法可以查看注 2。
如果要得到更好的壓縮率,我們需要采取更加適合時序數(shù)據(jù)的壓縮算法。時序數(shù)據(jù)的壓縮可以分為無損壓縮和有損壓縮。
無損壓縮
無損壓縮是說被壓縮的數(shù)據(jù)和解壓后的數(shù)據(jù)完全一樣,不存在精度的損失。對數(shù)據(jù)的壓縮說到底是對數(shù)據(jù)規(guī)律性的總結(jié)。時序數(shù)據(jù)的規(guī)律可以總結(jié)為兩點:1、timestamp 穩(wěn)定遞增、2、數(shù)值有規(guī)律性,變化穩(wěn)定。下面來舉個例子。
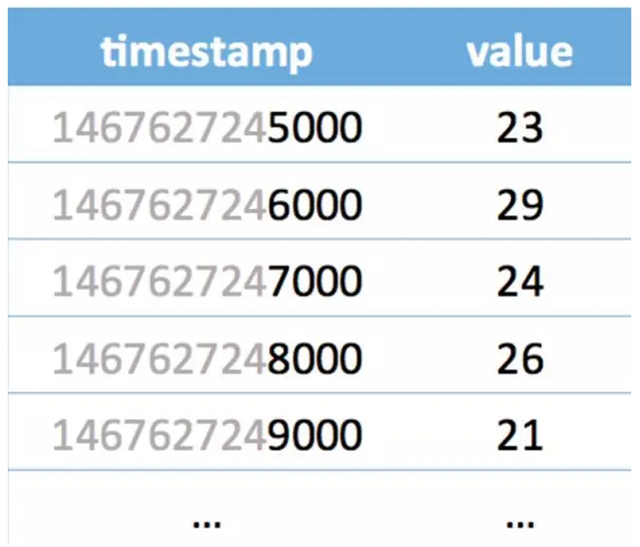
上圖是一組時序數(shù)據(jù),如果我們一行一行的看感覺壓縮有點困難,但如果我們一列一列的看,壓縮方案就呼之欲出了。
先看 timestamp 那一列是等差遞增數(shù)列,可以用 [1467627245000,1000,4] 來表示。1467627245000 代表了***個時間,1000 代表后一個時間比前一個時間的大 1000,4 代表了這樣的規(guī)律出現(xiàn)了 4 次。如果一共有 100 個這樣規(guī)律的 timestamp,那就意味著,我們用 3 個 Long 型就可以表示出來。timestamp 壓縮率高達(dá) 33。
再進(jìn)一步觀察看 value 那一列,如果取差值,可以得到(6,-5,2,-5),全部都加 5 得到(11,0,7,0),這些數(shù)值都可以用 4bit 來表示。也就是用 [23,5,4,0xb0700000] 來表示(23,22,24,25,24)。其中的 4 代表后續(xù)一共有 4 個數(shù)。如果這樣的規(guī)律一直維持到 100 個 Int 的 value,就可以用 16 個 Int 來代表,壓縮率高達(dá) 6.3。
具體的情景會復(fù)雜很多,在此只是簡單舉個例子。InfluxDB 無損壓縮算法在其頁面上有完整的闡述(注 3),可以配合開源源碼進(jìn)行更加深入的理解。針對于浮點數(shù)類型,F(xiàn)acebook 在 Gorilla 論文中(注 4)提到的非常高效的無損壓縮算法,已經(jīng)有很多文章進(jìn)行分析。InfluxDB 對于浮點型也采用這個算法。
有損壓縮
有損壓縮的意思是說解壓后的數(shù)據(jù)和被壓縮的數(shù)據(jù)在精度上有損失,主要針對于浮點數(shù)。通常都會設(shè)置一個壓縮精度,控制精度損失。時序數(shù)據(jù)的有損壓縮的思路是擬合。也就是用一條線盡可能的匹配到這些點,可以是直線,也可以是曲線。
最有名的時序數(shù)據(jù)有損壓縮是 SOIsoft 公司的 SDA 算法,中文稱為旋轉(zhuǎn)門壓縮算法。
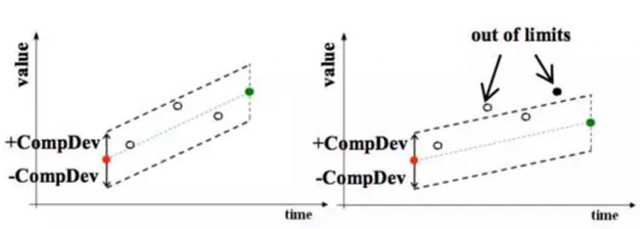
在上圖中,紅色的點是上一個記錄的點,空心的點是被丟掉的點,綠色的點是當(dāng)前的點,黑色的點是當(dāng)前要記錄的點。
可以看到圖左邊,當(dāng)前點和上一個記錄點以及壓縮精度的偏差值形成的矩形可以包含中間的點,所以這些點都是可以丟掉的。
再看圖右邊,當(dāng)前點和上一個記錄點形成的矩形無法包含中間的點,所以把上一個點記錄下來。如此進(jìn)行下去,可以看到,大部分的數(shù)據(jù)點都會被丟掉。查詢的時候需要根據(jù)記錄的點把丟掉的點在插值找回來。
有損壓縮除了可以大幅減少存儲成本。如果結(jié)合設(shè)備端的能力,甚至可以減少數(shù)據(jù)的寫入,降低網(wǎng)絡(luò)帶寬。
總結(jié)
雖然判斷壓縮算法***是不可計算的,但是設(shè)計好的壓縮算法仍然是可計算的問題。可以看到,前面提到的時序數(shù)據(jù)的無損壓縮有損壓縮算法都會基于時序數(shù)據(jù)的特征采取方案,達(dá)到更好的壓縮率。現(xiàn)在 deep learning 非常的火,讓人很好奇它是不是可以給數(shù)據(jù)壓縮帶來新的方案。
注 1:請點擊
注 2:請點擊
注 3:請點擊
注 4:請點擊














