Spark Shuffle過程分析:Map階段處理流程
默認配置情況下,Spark在Shuffle過程中會使用SortShuffleManager來管理Shuffle過程中需要的基本組件,以及對RDD各個Partition數據的計算。我們可以在Driver和Executor對應的SparkEnv對象創建過程中看到對應的配置,如下代碼所示:
- // Let the user specify short names for shuffle managers
- val shortShuffleMgrNames = Map(
- "sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
- "tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
- val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
- val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
- val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
如果需要修改ShuffleManager實現,則只需要修改配置項spark.shuffle.manager即可,默認支持sort和 tungsten-sort,可以指定自己實現的ShuffleManager類。
因為Shuffle過程中需要將Map結果數據輸出到文件,所以需要通過注冊一個ShuffleHandle來獲取到一個ShuffleWriter對象,通過它來控制Map階段記錄數據輸出的行為。其中,ShuffleHandle包含了如下基本信息:
- shuffleId:標識Shuffle過程的唯一ID
- numMaps:RDD對應的Partitioner指定的Partition的個數,也就是ShuffleMapTask輸出的Partition個數
- dependency:RDD對應的依賴ShuffleDependency
下面我們看下,在SortShuffleManager中是如何注冊Shuffle的,代碼如下所示:
- override def registerShuffle[K, V, C](
- shuffleId: Int,
- numMaps: Int,
- dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
- if (SortShuffleWriter.shouldBypassMergeSort(SparkEnv.get.conf, dependency)) {
- new BypassMergeSortShuffleHandle[K, V](
- shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
- } else if (SortShuffleManager.canUseSerializedShuffle(dependency)) {
- new SerializedShuffleHandle[K, V](
- shuffleId, numMaps, dependency.asInstanceOf[ShuffleDependency[K, V, V]])
- } else {
- new BaseShuffleHandle(shuffleId, numMaps, dependency)
- }
- }
上面代碼中,對應如下3種ShuffleHandle可以選擇,說明如下:
- BypassMergeSortShuffleHandle
如果dependency不需要進行Map Side Combine,并且RDD對應的ShuffleDependency中的Partitioner設置的Partition的數量(這個不要和parent RDD的Partition個數混淆,Partitioner指定了map處理結果的Partition個數,每個Partition數據會在Shuffle過程中全部被拉取而拷貝到下游的某個Executor端)小于等于配置參數spark.shuffle.sort.bypassMergeThreshold的值,則會注冊BypassMergeSortShuffleHandle。默認情況下,spark.shuffle.sort.bypassMergeThreshold的取值是200,這種情況下會直接將對RDD的 map處理結果的各個Partition數據寫入文件,并***做一個合并處理。
- SerializedShuffleHandle
如果ShuffleDependency中的Serializer,允許對將要輸出數據對象進行排序后,再執行序列化寫入到文件,則會選擇創建一個SerializedShuffleHandle。
- BaseShuffleHandle
除了上面兩種ShuffleHandle以后,其他情況都會創建一個BaseShuffleHandle對象,它會以反序列化的格式處理Shuffle輸出數據。
Map階段處理流程分析
Map階段RDD的計算,對應ShuffleMapTask這個實現類,它最終會在每個Executor上啟動運行,每個ShuffleMapTask處理RDD的一個Partition的數據。這個過程的核心處理邏輯,代碼如下所示:
- val manager = SparkEnv.get.shuffleManager
- writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
- writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
上面代碼中,在調用rdd的iterator()方法時,會根據RDD實現類的compute方法指定的處理邏輯對數據進行處理,當然,如果該Partition對應的數據已經處理過并存儲在MemoryStore或DiskStore,直接通過BlockManager獲取到對應的Block數據,而無需每次需要時重新計算。然后,write()方法會將已經處理過的Partition數據輸出到磁盤文件。
在Spark Shuffle過程中,每個ShuffleMapTask會通過配置的ShuffleManager實現類對應的ShuffleManager對象(實際上是在SparkEnv中創建),根據已經注冊的ShuffleHandle,獲取到對應的ShuffleWriter對象,然后通過ShuffleWriter對象將Partition數據寫入內存或文件。所以,接下來我們可能關心每一種ShuffleHandle對應的ShuffleWriter的行為,可以看到SortShuffleManager中獲取到ShuffleWriter的實現代碼,如下所示:
- /** Get a writer for a given partition. Called on executors by map tasks. */
- override def getWriter[K, V](
- handle: ShuffleHandle,
- mapId: Int,
- context: TaskContext): ShuffleWriter[K, V] = {
- numMapsForShuffle.putIfAbsent(
- handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
- val env = SparkEnv.get
- handle match {
- case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
- new UnsafeShuffleWriter(
- env.blockManager,
- shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
- context.taskMemoryManager(),
- unsafeShuffleHandle,
- mapId,
- context,
- env.conf)
- case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
- new BypassMergeSortShuffleWriter(
- env.blockManager,
- shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
- bypassMergeSortHandle,
- mapId,
- context,
- env.conf)
- case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
- new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
- }
- }
我們以最簡單的SortShuffleWriter為例進行分析,在SortShuffleManager可以通過getWriter()方法創建一個SortShuffleWriter對象,然后在ShuffleMapTask中調用SortShuffleWriter對象的write()方法處理Map輸出的記錄數據,write()方法的處理代碼,如下所示:
- /** Write a bunch of records to this task's output */
- override def write(records: Iterator[Product2[K, V]]): Unit = {
- sorter = if (dep.mapSideCombine) {
- require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
- new ExternalSorter[K, V, C](
- context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
- } else {
- // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
- // care whether the keys get sorted in each partition; that will be done on the reduce side
- // if the operation being run is sortByKey.
- new ExternalSorter[K, V, V](
- context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
- }
- sorter.insertAll(records)
- // Don't bother including the time to open the merged output file in the shuffle write time,
- // because it just opens a single file, so is typically too fast to measure accurately
- // (see SPARK-3570).
- val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
- val tmp = Utils.tempFileWith(output)
- val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
- val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
- shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
- mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
- }
從SortShuffleWriter類中的write()方法可以看到,最終調用了ExeternalSorter的insertAll()方法,實現了Map端RDD某個Partition數據處理并輸出到內存或磁盤文件,這也是處理Map階段輸出記錄數據最核心、最復雜的過程。我們將其分為兩個階段進行分析:***階段是,ExeternalSorter的insertAll()方法處理過程,將記錄數據Spill到磁盤文件;第二階段是,執行完insertAll()方法之后的處理邏輯,創建Shuffle Block數據文件及其索引文件。
內存緩沖寫記錄數據并Spill到磁盤文件
查看SortShuffleWriter類的write()方法可以看到,在內存中緩存記錄數據的數據結構有兩種:一種是Buffer,對應的實現類PartitionedPairBuffer,設置mapSideCombine=false時會使用該結構;另一種是Map,對應的實現類是PartitionedAppendOnlyMap,設置mapSideCombine=false時會使用該結構。根據是否指定mapSideCombine選項,分別對應不同的處理流程,我們分別說明如下:
設置mapSideCombine=false時
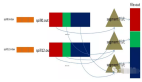
這種情況在Map階段不進行Combine操作,在內存中緩存記錄數據會使用PartitionedPairBuffer這種數據結構來緩存、排序記錄數據,它是一個Append-only Buffer,僅支持向Buffer中追加數據鍵值對記錄,PartitionedPairBuffer的結構如下圖所示:

默認情況下,PartitionedPairBuffer初始分配的存儲容量為capacity = initialCapacity = 64,實際上這個容量是針對key的容量,因為要存儲的是鍵值對記錄數據,所以實際存儲鍵值對的容量為2*initialCapacity = 128。PartitionedPairBuffer是一個能夠動態擴充容量的Buffer,內部使用一個一維數組來存儲鍵值對,每次擴容結果為當前Buffer容量的2倍,即2*capacity,***支持存儲2^31-1個鍵值對記錄(1073741823個)。
通過上圖可以看到,PartitionedPairBuffer存儲的鍵值對記錄數據,鍵是(partition, key)這樣一個Tuple,值是對應的數據value,而且curSize是用來跟蹤寫入Buffer中的記錄的,key在Buffer中的索引位置為2*curSize,value的索引位置為2*curSize+1,可見一個鍵值對的key和value的存儲在PartitionedPairBuffer內部的數組中是相鄰的。
使用PartitionedPairBuffer緩存鍵值對記錄數據,通過跟蹤實際寫入到Buffer內的記錄數據的字節數來判斷,是否需要將Buffer中的數據Spill到磁盤文件,如下代碼所示:
- protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
- var shouldSpill = false
- if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
- // Claim up to double our current memory from the shuffle memory pool
- val amountToRequest = 2 * currentMemory - myMemoryThreshold
- val granted = acquireMemory(amountToRequest)
- myMemoryThreshold += granted
- // If we were granted too little memory to grow further (either tryToAcquire returned 0,
- // or we already had more memory than myMemoryThreshold), spill the current collection
- shouldSpill = currentMemory >= myMemoryThreshold
- }
- shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
- // Actually spill
- if (shouldSpill) {
- _spillCount += 1
- logSpillage(currentMemory)
- spill(collection)
- _elementsRead = 0
- _memoryBytesSpilled += currentMemory
- releaseMemory()
- }
- shouldSpill
- }
上面elementsRead表示存儲到PartitionedPairBuffer中的記錄數,currentMemory是對Buffer中的總記錄數據大小(字節數)的估算,myMemoryThreshold通過配置項spark.shuffle.spill.initialMemoryThreshold來進行設置的,默認值為5 * 1024 * 1024 = 5M。當滿足條件elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold時,會先嘗試向MemoryManager申請2 * currentMemory – myMemoryThreshold大小的內存,如果能夠申請到,則不進行Spill操作,而是繼續向Buffer中存儲數據,否則就會調用spill()方法將Buffer中數據輸出到磁盤文件。
向PartitionedPairBuffer中寫入記錄數據,以及滿足條件Spill記錄數據到磁盤文件,具體處理流程,如下圖所示:

為了查看按照怎樣的規則進行排序,我們看一下,當不進行Map Side Combine時,創建ExternalSorter對象的代碼如下所示:
- // In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
- // care whether the keys get sorted in each partition; that will be done on the reduce side
- // if the operation being run is sortByKey.
- new ExternalSorter[K, V, V](
- context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
上面aggregator = None,ordering = None,在對PartitionedPairBuffer中的記錄數據Spill到磁盤之前,要使用默認的排序規則進行排序,排序的規則是只對PartitionedPairBuffer中的記錄按Partition ID進行升序排序,可以查看WritablePartitionedPairCollection伴生對象類的代碼(其中PartitionedPairBuffer類實現了特質WritablePartitionedPairCollection),如下所示:
- /**
- * A comparator for (Int, K) pairs that orders them by only their partition ID.
- */
- def partitionComparator[K]: Comparator[(Int, K)] = new Comparator[(Int, K)] {
- override def compare(a: (Int, K), b: (Int, K)): Int = {
- a._1 - b._1
- }
- }
上面圖中,引用了SortShuffleWriter.writeBlockFiles這個子序列圖,用來生成Block數據文件和索引文件,后面我們會單獨說明。通過對RDD進行計算生成一個記錄迭代器對象,通過該迭代器迭代出的記錄會存儲到PartitionedPairBuffer中,當滿足Spill條件時,先對PartitionedPairBuffer中記錄進行排序,***Spill到磁盤文件,這個過程中PartitionedPairBuffer中的記錄數據的變化情況,如下圖所示:

上圖中,對內存中PartitionedPairBuffer中的記錄按照Partition ID進行排序,并且屬于同一個Partition的數據記錄在PartitionedPairBuffer內部的data數組中是連續的。排序結束后,在Spill到磁盤文件時,將對應的Partition ID去掉了,只在文件temp_shuffle_4c4b258d-52e4-47a0-a9b6-692f1af7ec9d中連續存儲鍵值對數據,但同時在另一個內存數組結構中會保存文件中每個Partition擁有的記錄數,這樣就能根據Partition的記錄數來順序讀取文件temp_shuffle_4c4b258d-52e4-47a0-a9b6-692f1af7ec9d中屬于同一個Partition的全部記錄數據。
ExternalSorter類內部維護了一個SpillFile的ArrayBuffer數組,最終可能會生成多個SpillFile,SpillFile的定義如下所示:
- private[this] case class SpilledFile(
- file: File,
- blockId: BlockId,
- serializerBatchSizes: Array[Long],
- elementsPerPartition: Array[Long])
每個SpillFile包含一個blockId,標識Map輸出的該臨時文件;serializerBatchSizes表示每次批量寫入到文件的Object的數量,默認為10000,由配置項spark.shuffle.spill.batchSize來控制;elementsPerPartition表示每個Partition中的Object的數量。調用ExternalSorter的insertAll()方法,最終可能有如下3種情況:
- Map階段輸出記錄數較少,沒有生成SpillFile,那么所有數據都在Buffer中,直接對Buffer中記錄排序并輸出到文件
- Map階段輸出記錄數較多,生成多個SpillFile,同時Buffer中也有部分記錄數據
- Map階段輸出記錄數較多,只生成多個SpillFile
- 有關后續如何對上面3種情況進行處理,可以想見后面對子序列圖SortShuffleWriter.writeBlockFiles的說明。
- 設置mapSideCombine=true時
這種情況在Map階段會執行Combine操作,在Map階段進行Combine操作能夠降低Map階段數據記錄的總數,從而降低Shuffle過程中數據的跨網絡拷貝傳輸。這時,RDD對應的ShuffleDependency需要設置一個Aggregator用來執行Combine操作,可以看下Aggregator類聲明,代碼如下所示:
- /**
- * :: DeveloperApi ::
- * A set of functions used to aggregate data.
- *
- * @param createCombiner function to create the initial value of the aggregation.
- * @param mergeValue function to merge a new value into the aggregation result.
- * @param mergeCombiners function to merge outputs from multiple mergeValue function.
- */
- @DeveloperApi
- case class Aggregator[K, V, C] (
- createCombiner: V => C,
- mergeValue: (C, V) => C,
- mergeCombiners: (C, C) => C) {
- ... ...
- }
由于在Map階段只用到了構造Aggregator的幾個函數參數createCombiner、mergeValue、mergeCombiners,我們對這幾個函數詳細說明如下:
- createCombiner:進行Aggregation開始時,需要設置初始值。因為在Aggregation過程中使用了類似Map的內存數據結構來管理鍵值對,每次加入前會先查看Map內存結構中是否存在Key對應的Value,***次肯定不存在,所以***將某個Key的Value加入到Map內存結構中時,Key在Map內存結構中***次有了Value。
- mergeValue:某個Key已經在Map結構中存在Value,后續某次又遇到相同的Key和一個新的Value,這時需要通過該函數,將舊Value和新Value進行合并,根據Key檢索能夠得到合并后的新Value。
- mergeCombiners:一個Map內存結構中Key和Value是由mergeValue生成的,那么在向Map中插入數據,肯定會遇到Map使用容量達到上限,這時需要將記錄數據Spill到磁盤文件,那么多個Spill輸出的磁盤文件中可能存在同一個Key,這時需要對多個Spill輸出的磁盤文件中的Key的多個Value進行合并,這時需要使用mergeCombiners函數進行處理。
該類中定義了combineValuesByKey、combineValuesByKey、combineCombinersByKey,由于這些函數是在Reduce階段使用的,所以在這里先不說明,后續文章我們會單獨詳細來分析。
我們通過下面的序列圖來描述,需要進行Map Side Combine時的處理流程,如下所示:

對照上圖,我們看一下,當需要進行Map Side Combine時,對應的ExternalSorter類insertAll()方法中的處理邏輯,代碼如下所示:
- val shouldCombine = aggregator.isDefined
- if (shouldCombine) {
- // Combine values in-memory first using our AppendOnlyMap
- val mergeValue = aggregator.get.mergeValue
- val createCombiner = aggregator.get.createCombiner
- var kv: Product2[K, V] = null
- val update = (hadValue: Boolean, oldValue: C) => {
- if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
- }
- while (records.hasNext) {
- addElementsRead()
- kv = records.next()
- map.changeValue((getPartition(kv._1), kv._1), update)
- maybeSpillCollection(usingMap = true)
- }
- }
上面代碼中,map是內存數據結構,最重要的是update函數和map的changeValue方法(這里的map對應的實現類是PartitionedAppendOnlyMap)。update函數所做的工作,其實就是對createCombiner和mergeValue這兩個函數的使用,***次遇到一個Key調用createCombiner函數處理,非***遇到同一個Key對應新的Value調用mergeValue函數進行合并處理。map的changeValue方法主要是將Key和Value在map中存儲或者進行修改(對出現的同一個Key的多個Value進行合并,并將合并后的新Value替換舊Value)。
PartitionedAppendOnlyMap是一個經過優化的哈希表,它支持向map中追加數據,以及修改Key對應的Value,但是不支持刪除某個Key及其對應的Value。它能夠支持的存儲容量是0.7 * 2 ^ 29 = 375809638。當達到指定存儲容量或者指定限制,就會將map中記錄數據Spill到磁盤文件,這個過程和前面的類似,不再累述。
創建Shuffle Block數據文件及其索引文件
無論是使用PartitionedPairBuffer,還是使用PartitionedAppendOnlyMap,當需要容量滿足Spill條件時,都會將該內存結構(buffer/map)中記錄數據Spill到磁盤文件,所以Spill到磁盤文件的格式是相同的。對于后續Block數據文件和索引文件的生成邏輯也是相同,如下圖所示:

假設,我們生成的Shuffle Block文件對應各個參數為:shuffleId=2901,mapId=11825,reduceId=0,這里reduceId是一個NOOP_REDUCE_ID,表示與DiskStore進行磁盤I/O交互操作,而DiskStore期望對應一個(map, reduce)對,但是對于排序的Shuffle輸出,通常Reducer拉取數據后只生成一個文件(Reduce文件),所以這里默認reduceId為0。經過上圖的處理流程,可以生成一個.data文件,也就是Block數據文件;一個.index文件,也就是包含了各個Partition在數據文件中的偏移位置的索引文件。這個過程生成的文件,示例如下所示:
- shuffle_2901_11825_0.data
- shuffle_2901_11825_0.index
這樣,對于每個RDD的多個Partition進行處理后,都會生成對應的數據文件和索引文件,后續在Reduce端就可以讀取這些Block文件,這些記錄數據在文件中都是經過分區(Partitioned)的。