更簡單、更快捷:探討深度學習的未來發(fā)展步伐
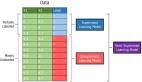
譯文【51CTO.com快譯】機器學習是一門多領域交叉學科,專門研究計算機怎樣模擬或?qū)崿F(xiàn)人類的學習行為,以獲取新的知識或技能,重新組織已有的知識結構使之不斷改善自身的性能。它是人工智能的核心,是使計算機具有智能的根本途徑。
如果論及哪一個機器學習的領域最為熱門,非人工智能莫屬,這就是深度學習。深度學習框架又名深度神經(jīng)網(wǎng)絡,一個復雜的模式識別系統(tǒng),可以實現(xiàn)從自動語言翻譯到圖像識別的功能。
深度學習需要收集大量的數(shù)據(jù),并且擁有處理這些數(shù)據(jù)的能力,做到這些并非易事,但深度學習技術正在蓬勃發(fā)展的道路上,并且已經(jīng)突破了很多障礙。深度學習對于分析非結構化數(shù)據(jù)具有非常大的優(yōu)勢。
各大軟件巨頭們也在醞釀一場深度學習技術的爭霸戰(zhàn),比如谷歌的TensorFlow項目與百度的paddle。多個軟件框架之間的競爭蓄勢待發(fā)。軟件和硬件間的戰(zhàn)爭開始了。有預言稱,專門的硬件設計模型和服務會是深度學習的下一個大的進步,或許有更好、更智能、更高效的算法,無需硬件的輔助就可以把功能服務推向更多人。問題也由此產(chǎn)生,我們中的大多數(shù)人都能逐漸理解和接受深度學習技術嗎?還是我們一直需要計算機博士們來把握這項技術工作?
微軟比谷歌更緊張
一項重要技術展示給世界的好辦法,就是引起技術巨頭公司們的興趣。像過去的NoSQL、Hadoop和Spark。在深度學習框架領域,谷歌的TensorFlow已經(jīng)發(fā)展得十分可觀,而谷歌云和谷歌專有硬件的研發(fā)也緊隨其后。
作為競爭對手,微軟反擊谷歌的殺手锏是認知工具包,也叫CNTK。CNTK2.0版在多個層面挑戰(zhàn)TensorFlow。CNTK現(xiàn)在提供JavaAPI,可接受Spark處理框架,同時支持Keras神經(jīng)網(wǎng)絡圖書館代碼,這實際上就是TensorFlow的前端。這樣一來,Keras的用戶就可以避開谷歌的解決方案而轉(zhuǎn)向微軟。
對于谷歌TensorFlow,微軟最直接、最有意義的應對方法是讓CNTK更快速和準確,并且使PythonAPI提供高級別和低級別的功能。這是微軟想出來的***應對策略。
當然,所謂的快速和準確并不是吹牛,如果微軟的系統(tǒng)比TensorFlow更快,那便意味著人們有更多的選擇而不只是去砸硬件設備。比如,
Tensorflow通過谷歌的定制TPU處理器進行硬件加速,那就意味著第三方項目,TensorFlow和CNTK的接口,就像Spark一樣,都能得到加速。承蒙雅虎的牽線,TensorFlow和Spark已經(jīng)協(xié)同工作,但是如果CNTK和Spark提供更少的工作和更高的報酬,CNTK就成為了Spark所在領域中最為誘人的選擇。
硬件:Graphcore和波計算
谷歌TPU的一個缺點是,他們只在谷歌云中有效。對于那些已經(jīng)投資了GCP的人來說,這可能不是個問題,但是對于大多數(shù)人,這是一個潛在的"阻斷劑"。為深入學習專用硅,如NVIDIA的GPU需要的附加條件較少。
幾家公司最近推出了專門的硅優(yōu)于GPU深度學習的應用。啟動Graphcore深度學習處理器,專門的硅片設計過程中采用神經(jīng)網(wǎng)絡的圖形數(shù)據(jù)。該公司稱面臨的挑戰(zhàn)是創(chuàng)建硬件優(yōu)化,以運行循環(huán)或相互連接的網(wǎng)絡和其他網(wǎng)絡。
一種Graphcore加速的方法是保持網(wǎng)絡模型盡可能接近硅,避免對外部存儲器的往返訪問。盡可能的避免數(shù)據(jù)運動是加快機器學習的一種常用方法,但Graphcore以這種方式到達另一個層次。
波計算是深度學習專用硬件的另一種啟用方式。像Graphcore一樣,公司認為GPU的發(fā)展和它自身固有的局限性有很大關系,波計算的計劃是建立"數(shù)據(jù)流的設備,"機架式系統(tǒng)使用定制芯片,可以提供2.9petaops計算("petaops"是定點運算,不是"千萬億次的"浮點運算)。這樣的運算速度超出了谷歌TPU提供的92teraops的訂單。
在需要獨立基準,也不清楚每Petaop的價格是否有競爭力的情況下,波計算能保證價格的穩(wěn)定,也讓它的潛在用戶可以放心。谷歌TensorFlow的支持是***個產(chǎn)品框架支持,CNTK、亞馬遜的MXNeT和其他公司緊隨其后。
brodmann17:小模型,高速度
鑒于Graphcore和波計算的硬件要優(yōu)于TPU,其他第三方的目的是展示框架和更好的運算法則,可以帶來更有力的機械學習。有些用于定位缺乏訪問處理區(qū)域,例如智能手機。
谷歌已經(jīng)針對TensorFlow在移動設備上的應用作出升級,一個名為Brodmann17的工具試圖在智能手機級硬盤上占用5%的資源(包括計算、存儲和數(shù)據(jù))。
該公司的做法是由***執(zhí)行官和創(chuàng)始人AdiPinhas提出的,用現(xiàn)有的標準神經(jīng)網(wǎng)絡模塊創(chuàng)建一個更小的模型。Pinhas說,相比其他流行的深度學習架構,小的模型數(shù)量少于訓練數(shù)據(jù)的10%。但在相同的時間里需要一些培訓。最終的目的是對速度的精確權衡,更快的預測時間,功耗更低,占用的內(nèi)存少。
現(xiàn)階段別指望看到什么開放源代碼的產(chǎn)品出現(xiàn),brodmann17的商業(yè)模式是提供云計算的API和本地計算的SDK。Pinhas說,"我們希望擴大我們未來的產(chǎn)品,所以商業(yè)化可能只是***步。
擦出新火花
今年早些時候,InfoWorld撰稿人JamesKobielus預言深度學習框架之間的戰(zhàn)火漸起。雅虎已經(jīng)把TensorFlow引向Spark,但是Spark的主要供應商Databricks現(xiàn)在向Spark提供自己的開源軟件包來整合深度學習框架。
正如該項目的名稱--深度學習管道,探討深度學習整合并且以Spark自己的角度來看待ML管道技術。Spark工作流可以像TensorFlow和Keras一樣被稱為圖書館。這些框架模型可以像Spark在其他方面一樣,進行規(guī)模化訓練。并且通過Spark自己的方式來處理數(shù)據(jù)和深度學習模型。許多數(shù)據(jù)管理員已經(jīng)熟悉了Spark并且開始使用它。
全民深度學習?
Databricks曾經(jīng)在自己的新聞稿里提到"民主化的人工智能和數(shù)據(jù)科學"。這樣的論調(diào)意味著什么呢?微軟認為他們的CNTK2.0可以成為一項有力的舉措,使AI技術無處不在的面向所有人。深度學習固有的復雜性并不是唯一要克服的障礙。深度學習的整個工作流程仍然是一個點對點的工作流程。這里有需要填補的空白,所有平臺、框架和云背后的商業(yè)機構都在競相填補端到端的解決方案。關于深度學習技術,下一步的關鍵將不僅僅是找到一個真正的深層學習框架。而是找到一個統(tǒng)一的工作流程。這樣一來,不管是誰在開發(fā)運行項目,其深度學習框架都可以有據(jù)可循的進行開發(fā)和研究。
作者:SerdarYegulalp
原文鏈接:
http://www.infoworld.com/article/3199950/artificial-intelligence/deep-learnings-next-steps-custom-hardware-better-frameworks-easier-on-ramps.html
劉妮娜譯
【51CTO譯稿,合作站點轉(zhuǎn)載請注明原文譯者和出處為51CTO.com】