數(shù)據(jù)庫壓縮技術探索
作為數(shù)據(jù)庫,在系統(tǒng)資源(CPU、內存、SSD、磁盤等)一定的前提下,我們希望:
- 存儲的數(shù)據(jù)更多:采用壓縮,這個世界上有各種各樣的壓縮算法;
- 訪問的速度更快:更快的壓縮(寫)/解壓(讀)算法、更大的緩存。
幾乎所有壓縮算法都嚴重依賴上下文:
- 位置相鄰的數(shù)據(jù),一般情況下相關性更高,內在冗余度更大;
- 上下文越大,壓縮率的上限越大(有極限值)。
塊壓縮
傳統(tǒng)數(shù)據(jù)庫中的塊壓縮技術
對于普通的以數(shù)據(jù)塊/文件為單位的壓縮,傳統(tǒng)的(流式)數(shù)據(jù)壓縮算法工作得不錯,時間長了,大家也都習慣了這種數(shù)據(jù)壓縮的模式。基于這種模式的數(shù)據(jù)壓縮算法層出不窮,不斷有新的算法實現(xiàn)。包括使用最廣泛的gzip、bzip2、Google的Snappy、新秀Zstd等。
- gzip幾乎在在所有平臺上都有支持,并且也已經(jīng)成為一個行業(yè)標準,壓縮率、壓縮速度、解壓速度都比較均衡;
- bzip2是基于BWT變換的一種壓縮,本質是上對輸入分塊,每個塊單獨壓縮,優(yōu)點是壓縮率很高,但壓縮和解壓速度都比較慢;
- Snappy是Google出品,優(yōu)點是壓縮和解壓都很快,缺點是壓縮率比較低,適用于對壓縮率要求不高的實時壓縮場景;
- LZ4是Snappy一個強有力的競爭對手,速度比Snappy更快,特別是解壓速度;
- Zstd是一個壓縮新秀,壓縮率比LZ4和Snappy都高不少,壓縮和解壓速度略低;相比gzip,壓縮率不相上下,但壓縮/解壓速度要高很多。
對于數(shù)據(jù)庫,在計算機世界的太古代,為I/O優(yōu)化的Btree一直是不可撼動的,為磁盤優(yōu)化的Btree block/page size比較大,正好讓傳統(tǒng)數(shù)據(jù)壓縮算法能得到較大的上下文,于是,基于block/page的壓縮也就自然而然地應用到了各種數(shù)據(jù)庫中。在這個蠻荒時代,內存的性能、容量與磁盤的性能、容量涇渭分明,各種應用對性能的需求也比較小,大家都相安無事。
現(xiàn)在,我們有了SSD、PCIe SSD、3D XPoint等,內存也越來越大,塊壓縮的缺點也日益突出:
- 塊選小了,壓縮率不夠;塊選大了,性能沒法忍;
- 更致命的是,塊壓縮節(jié)省的只是更大更便宜的磁盤、SSD;
- 更貴更小的內存不但沒有節(jié)省,反而更浪費了(雙緩存問題)。
于是,對于很多實時性要求較高的應用,只能關閉壓縮。
塊壓縮的原理
使用通用壓縮技術(Snappy、LZ4、zip、bzip2、Zstd等),按塊/頁(block/page)進行壓縮(塊尺寸通常是4KB~32KB,以壓縮率著稱的TokuDB塊尺寸是2MB~4MB),這個塊是邏輯塊,而不是內存分頁、塊設備概念中的那種物理塊。
啟用壓縮時,隨之而來的是訪問速度下降,這是因為:
- 寫入時,很多條記錄被打包在一起壓縮成一個個的塊,增大塊尺寸,壓縮算法可以獲得更大的上下文,從而提高壓縮率;相反地,減小塊尺寸,會降低壓縮率。
- 讀取時,即便是讀取很短的數(shù)據(jù),也需要先把整個塊解壓,再去讀取解壓后的數(shù)據(jù)。這樣,塊尺寸越大,同一個塊內包含的記錄數(shù)目越多。為讀取一條數(shù)據(jù),所做的不必要解壓就也就越多,性能也就越差。相反地,塊尺寸越小,性能也就越好。
一旦啟用壓縮,為了緩解以上問題,傳統(tǒng)數(shù)據(jù)庫一般都需要比較大的專用緩存,用來緩存解壓后的數(shù)據(jù),這樣可以大幅提高熱數(shù)據(jù)的訪問性能,但又引起了雙緩存的空間占用問題:一是操作系統(tǒng)緩存中的壓縮數(shù)據(jù);二是專用緩存(例如RocksDB中的DBCache)中解壓后的數(shù)據(jù)。還有一個同樣很嚴重的問題:專用緩存終歸是緩存,當緩存未***時,仍需要解壓整個塊,這就是慢Query問題的一個主要來源(慢Query的另一個主要來源是在操作系統(tǒng)緩存未***時)。
這些都導致現(xiàn)有傳統(tǒng)數(shù)據(jù)庫在訪問速度和空間占用上是一個此消彼長、無法徹底解決的問題,只能采取一些折衷。
RocksDB 的塊壓縮
以RocksDB為例,RocksDB中的BlockBasedTable就是一個塊壓縮的SSTable,使用塊壓縮,索引只定位到塊,塊的尺寸在dboption里設定,一個塊中包含多條(key,value)數(shù)據(jù),例如M條,這樣索引的尺寸就減小到了1/M:
- M越大,索引的尺寸越小;
- M越大,Block的尺寸越大,壓縮算法(gzip、Snappy等)可以獲得的上下文也越大,壓縮率也就越高。
創(chuàng)建BlockBasedTable時,Key Value被逐條填入buffer,當buffer尺寸達到預定大小(塊尺寸,當然,一般buffer尺寸不會精確地剛好等于預設的塊尺寸),就將buffer壓縮并寫入BlockBasedTable文件,并記錄文件偏移和buffer中的***個Key(創(chuàng)建index要用),如果單條數(shù)據(jù)太大,比預設的塊尺寸還大,這條數(shù)據(jù)就單獨占一個塊(單條數(shù)據(jù)不管多大也不會分割成多個塊)。所有Key Value寫完以后,根據(jù)之前記錄的每個塊的起始Key和文件偏移,創(chuàng)建一個索引。所以在BlockBasedTable文件中,數(shù)據(jù)在前,索引在后,文件末尾包含元信息(作用相當于常用的FileHeader,只是位置在文件末尾,所以叫footer)。
搜索時,先使用searchkey找到searchkey所在的block,然后到DB Cache中搜索這個塊,找到后就進一步在塊中搜索searchkey,如果找不到,就從磁盤/SSD讀取這個塊,解壓后放入DB Cache。RocksDB中的DB Cache有多種實現(xiàn),常用的包括LRU Cache,另外還有Clock Cache、Counting Cache(用來統(tǒng)計Cache***率等),還有其他一些特殊的Cache。
一般情況下,操作系統(tǒng)會有文件緩存,所以同一份數(shù)據(jù)可能既在DB Cache中(解壓后的數(shù)據(jù)),又在操作系統(tǒng)Cache中(壓縮的數(shù)據(jù))。這樣會造成內存浪費,所以RocksDB提供了一個折衷:在dboption中設置DIRECT_IO選項,繞過操作系統(tǒng)Cache,這樣就只有DB Cache,可以節(jié)省一部分內存,但在一定程度上會降低性能。
傳統(tǒng)非主流壓縮:FM-Index
FM-Index的全名是Full Text Matching Index,屬于Succinct Data Structure家族,對數(shù)據(jù)有一定的壓縮能力,并且可以直接在壓縮的數(shù)據(jù)上執(zhí)行搜索和訪問。
FM-Index的功能非常豐富,歷史也已經(jīng)相當悠久,不算是一種新技術,在一些特殊場景下也已經(jīng)得到了廣泛應用,但是因為各種原因,一直不溫不火。最近幾年,F(xiàn)M-Index開始有些活躍,首先是GitHub上有個大牛實現(xiàn)了全套Succinct算法,其中包括FM-Index,其次Berkeley的Succinct項目也使用了FM-Index。
FM-Index屬于Offline算法(一次性壓縮所有數(shù)據(jù),壓縮好之后不可修改),一般基于BWT變換(BWT變換基于后綴數(shù)組),壓縮好的FM-Index支持以下兩個最主要的操作:
- data = extract(offset, length)
- {offset} = search(string) ,返回多個匹配string的位置/偏移(offset)
FM-Index還支持更多其他操作,感興趣的朋友可以進一步調研。
但是,在筆者看來,F(xiàn)M-Index有幾個致命的缺點:
- 實現(xiàn)太復雜(這一點可以被少數(shù)大牛們克服,不提也罷);
- 壓縮率不高(比流式壓縮例如gzip差太多);
- 搜索(search)和訪問(extract)速度都很慢(在2016年最快的CPU i7-6700K上,單線程吞吐率不超過7MB/sec);
- 壓縮過程又慢又耗內存(Berkeley的Succinct壓縮過程內存消耗是源數(shù)據(jù)的50倍以上);
- 數(shù)據(jù)模型是Flat Text,不是數(shù)據(jù)庫的KeyValue模型。
可以用一種簡單的方式把Flat Model轉化成KeyValue Model:挑選一個在Key和Value中都不會出現(xiàn)的字符“#”(如果無法找出這樣的字符,需要進行轉義編碼),每個Key前后都插入該字符,Key之后緊鄰的就是Value。如此,search(#key#)返回了#key#出現(xiàn)的位置,我們就能很容易地拿到Value了。
Berkeley的Succinc項目在FM-Index的Flat Text模型上實現(xiàn)了更豐富的行列(Row-Column)模型,付出了巨大的努力,達到了一定的效果,但離實用還相差太遠。
感興趣的朋友可以仔細調研下FM-Index,以驗證筆者的總結與判斷。
Terark的可檢索壓縮(Searchable Compression)
Terark公司提出了“可檢索壓縮(Searchable Compression)”的概念,其核心也是直接在壓縮的數(shù)據(jù)上執(zhí)行搜索(search)和訪問(extract),但數(shù)據(jù)模型本身就是KeyValue模型,根據(jù)其測試報告,速度要比FM-Index快得多(兩個數(shù)量級),具體闡述:
- 摒棄傳統(tǒng)數(shù)據(jù)庫的塊壓縮技術,采用全局壓縮;
- 對Key和Value使用不同的全局壓縮技術;
- 對Key使用有搜索功能的全局壓縮技術COIndex(對應FM-Index的search);
- 對Value使用可定點訪問的全局壓縮技術PA-Zip(對應FM-Index的extract)。
對Key的壓縮:CO-Index
我們需要對Key進行索引,才能有效地進行搜索,并訪問需要的數(shù)據(jù)。
普通的索引技術,索引的尺寸相對于索引中原始Key的尺寸要大很多,有些索引使用前綴壓縮,能在一定程度上緩解索引的膨脹,但仍然無法解決索引占用內存過大的問題。
我們提出了CO-Index(Compressed Ordered Index)的概念,并且通過一種叫做Nested Succinct Trie的數(shù)據(jù)結構實踐了這一概念。
較之傳統(tǒng)實現(xiàn)索引的數(shù)據(jù)結構,Nested Succinct Trie的空間占用小十幾倍甚至幾十倍。而在保持該壓縮率的同時,還支持豐富的搜索功能:
- 精確搜索;
- 范圍搜索;
- 順序遍歷;
- 前綴搜索;
- 正則表達式搜索(不是逐條遍歷)。
與FM-Index相比,CO-Index也有其優(yōu)勢(假定FM-Index中所有的數(shù)據(jù)都是Key)。

表1 FM-Index對比CO-Index
CO-Index的原理
實際上我們實現(xiàn)了很多種CO-Index,其中Nested Succinct Trie是適用性最廣的一種,在這里對其原理做一個簡單介紹:
Succinct Data Structure介紹
Succinct Data Structure是一種能夠在接近于信息論下限的空間內來表達對象的技術,通常使用位圖來表示,用位圖上的rank和select來定位。
雖然能夠極大降低內存占用量,但實現(xiàn)起來較為復雜,并且性能低很多(時間復雜度的常數(shù)項很大)。目前開源的有SDSL-Lite,我們則使用自己實現(xiàn)的Rank-Select,性能也高于開源實現(xiàn)。
以二叉樹為例
傳統(tǒng)的表現(xiàn)形式是一個結點中包含兩個指針:struct Node { Node *left, *right; };
每個結點占用 2ptr,如果我們對傳統(tǒng)方法進行優(yōu)化,結點指針用最小的bits數(shù)來表達,N個結點就需要2*[log2(N)]個bits。
- 對比傳統(tǒng)基本版和傳統(tǒng)優(yōu)化版,假設共有216個結點(包括null結點),傳統(tǒng)優(yōu)化版需要2 bytes,傳統(tǒng)基本版需要4/8 bytes。
- 對比傳統(tǒng)優(yōu)化版和Succinct,假設共有10億(~230)個結點。
- 傳統(tǒng)優(yōu)化版每個指針占用[log2(230)]=30bits,總內存占用:($\frac{2*30}{8}$)*230≈ 7.5GB。
- 使用Succinct,占用:($\frac{2.5}{8}$)*230≈ 312.5MB(每個結點2.5 bits,其中0.5bits是 rank-select 索引占用的空間)。
Succinct Tree
Succinct Tree有很多種表達方式,這里列出常見的兩種:
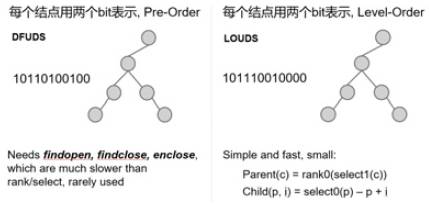
圖1 Succinct Tree表達方式示例
Succinct Trie = Succinct Tree + Trie Label
Trie可以用來實現(xiàn)Index,圖2這個Succinct Trie用的是LOUDS表達方式,其中保存了hat、is、it、a、四個Key。
Patricia Trie加嵌套
僅使用Succinct技術,壓縮率遠遠不夠,所以又應用了路徑壓縮和嵌套。這樣一來,壓縮率就上了一個新臺階。
把上面這些技術綜合到一起,就是我們的Nest Succinct Trie。
對Value的壓縮: PA-Zip
我們研發(fā)了一種叫做PA-Zip (Point Accessible Zip)的壓縮技術:每條數(shù)據(jù)關聯(lián)一個ID,數(shù)據(jù)壓縮好之后,就可以用相應的ID訪問那條數(shù)據(jù)。這里,ID就是那個Point,所以叫做Point Accessible Zip。
PA-Zip對整個數(shù)據(jù)庫中的所有Value(KeyValue數(shù)據(jù)庫中所有Value的集合)進行全局壓縮,而不是按block/page進行壓縮。這是針對數(shù)據(jù)庫的需求(KeyValue 模型),專門設計的一個壓縮算法,用來解決傳統(tǒng)數(shù)據(jù)庫壓縮的問題:
壓縮率更高,沒有雙緩存的問題,只要把壓縮后的數(shù)據(jù)裝進內存,不需要專用緩存,可以按ID直接讀取單條數(shù)據(jù),如果把這種讀取單條數(shù)據(jù)看作是一種解壓,那么:
- 按ID順序解壓時,解壓速度(Throughput)一般在500MB每秒(單線程),***達到約7GB/s,適合離線分析性需求,傳統(tǒng)數(shù)據(jù)庫壓縮也能做到這一點;
- 按ID隨機解壓時,解壓速度一般在300MB每秒(單線程),***達到約3GB/s,適合在線服務需求,這一點完勝傳統(tǒng)數(shù)據(jù)庫壓縮:按隨機解壓300MB/s算,如果每條記錄平均長度1K,相當于QPS = 30萬;如果每條記錄平均長度300個字節(jié),相當于QPS = 100萬;
- 預熱(warmup),在某些特殊場景下,數(shù)據(jù)庫可能需要預熱。因為去掉了專用緩存,TerarkDB的預熱相對簡單高效,只要把mmap的內存預熱一下(避免Page Fault即可),數(shù)據(jù)庫加載成功后就是預熱好的,這個預熱的Throughput就是SSD連續(xù)讀的IO性能(較新的SSD讀性能超過3GB/s)。
與FM-Index相比,PA-Zip解決的是FM-Index的extract操作,但性能和壓縮率都要好得多:
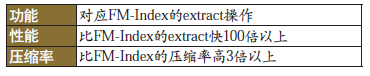
表2 FM-Index對比PA-Zip
結合Key與Value
Key以全局壓縮的形式保存在CO-Index中,Value以全局壓縮的形式保存在 PA-Zip中。搜索一個Key,會得到一個內部ID,根據(jù)這個ID,去PA-Zip中定點訪問該ID對應的Value,整個過程中只觸碰需要的數(shù)據(jù),不需要觸碰其他數(shù)據(jù)。
如此無需專用緩存(例如RocksDB中的DBCache),僅使用mmap,***配合文件系統(tǒng)緩存,整個DB只有mmap的文件系統(tǒng)緩存這一層緩存,再加上超高的壓縮率,大幅降低了內存用量,并且極大簡化了系統(tǒng)的復雜性,最終完成數(shù)據(jù)庫性能的大幅提升,從而同時實現(xiàn)了超高的壓縮率和超高的隨機讀性能。
從更高的哲學層面看,我們的存儲引擎很像是用構造法推導出來的,因為CO-Index和PA-Zip緊密配合,***匹配KeyValue模型,功能上“剛好夠用”,性能上壓榨硬件極限,壓縮率逼近信息論的下限。相比其他方案:
- 傳統(tǒng)塊壓縮是從通用的流式壓縮衍生而來,流式壓縮的功能非常有限,只有壓縮和解壓兩個操作,對太小的數(shù)據(jù)塊沒有壓縮效果,也無法壓縮數(shù)據(jù)塊之間的冗余。把它用到數(shù)據(jù)庫上,需要大量的工程努力,就像給汽車裝上飛機機翼,然后要讓它飛起來。
- 相比FM-Index,情況則相反,F(xiàn)M-Index的功能非常豐富,它就必然要為此付出一些代價——壓縮率和性能。而在KeyValue模型中,我們只需要它那些豐富功能的一個非常小的子集(還要經(jīng)過適配和轉化),其他更多的功能毫無用武之地,卻仍然要付出那些代價,就像我們花了很高的代價造了一架飛機,卻把它按在地上,只用輪子跑,當汽車用。
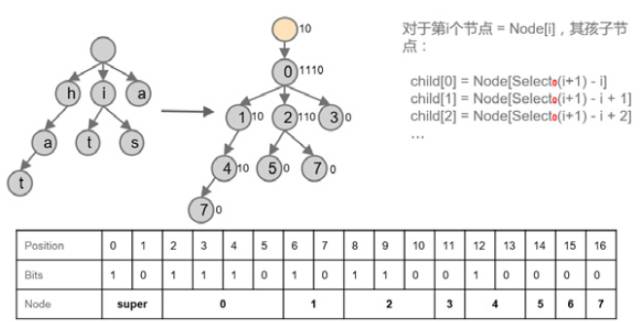
圖2 用LOUDS方式表達的Succinct Tree
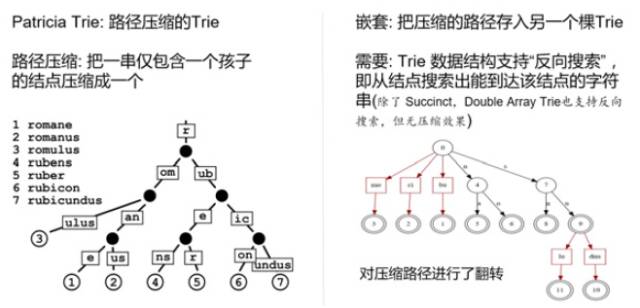
圖3 路徑壓縮與嵌套
附錄
壓縮率&性能測試比較
數(shù)據(jù)集:Amazon movie data
Amazon movie data (~8 million reviews),數(shù)據(jù)集的總大小約為9GB, 記錄數(shù)大約為800萬條,平均每條數(shù)據(jù)長度大約1K。
Benchmark代碼開源:參見Github倉庫(https://github.com/Terark/terarkdb-benchmark/tree/master/doc/movies)。
- 壓縮率(見圖4)
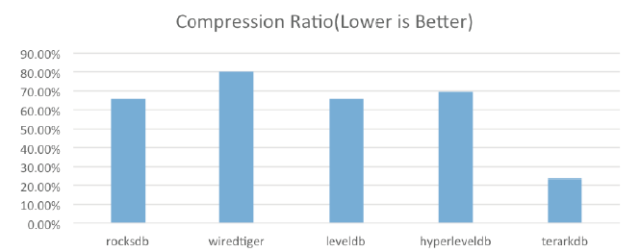
圖4 壓縮率對比
- 隨機讀(見圖5)
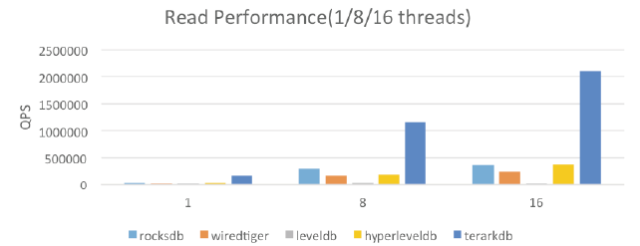
圖5 隨機讀性能對比
這是在內存足夠的情況下,各個存儲引擎的性能。
- 延遲曲線(見圖6)
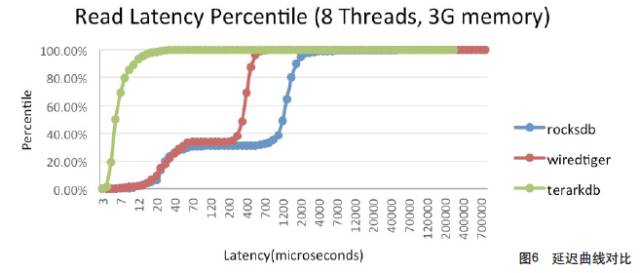
圖6 延遲曲線對比
數(shù)據(jù)集:Wikipedia英文版
Wikipedia英文版的所有文本數(shù)據(jù),109G,壓縮到23G。
數(shù)據(jù)集:TPC-H
在TPC-H的lineitem數(shù)據(jù)上,使用TerarkDB和原版RocksDB(BlockBasedTable)進行對比測試:
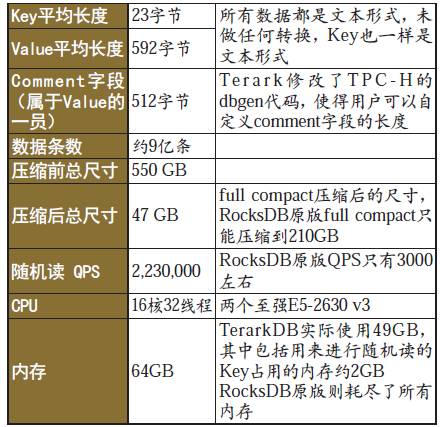
表3 TerarkDB與原版RocksDB對比測試
API 接口
TerarkDB = Terark SSTable + RocksDB
RocksDB最初是Facebook對Google的LevelDB的一個fork,編程接口上兼容LevelDB,并增加了很多改進。
RocksDB對我們有用的地方在于其SSTable可以plugin,所以我們實現(xiàn)了一個RocksDB的SSTable,將我們的技術優(yōu)勢通過RocksDB發(fā)揮出來。
雖然RocksDB提供了一個相對完整的KeyValueDB框架,但要完全適配我們特有的技術,仍有一些欠缺,所以需要對RocksDB本身也做一些修改。將來可能有一天我們會將自己的修改提交到RocksDB官方版。
Github鏈接:TerarkDB(https://github.com/Terark/terarkdb),TerarkDB包括兩部分:
- terark-zip-rocksdb(https://github.com/terark/terark-zip-rocksdb),(Terark SSTable forrocksdb)
- Terark fork rocksdb(https://github.com/Terark/rocksdb),(必須使用這個修改版的rocksdb)
為了更好的兼容性,TerarkDB對RocksDB的API沒有做任何修改,為了進一步方便用戶使用TerarkDB,我們甚至提供了一種方式:程序無需重新編譯,只需要替換 librocksdb.so并設置幾個環(huán)境變量,就能體驗TerarkDB。
如果用戶需要更精細的控制,可以使用C++ API詳細配置TerarkDB的各種選項。
目前大家可以免費試用,可以做性能評測,但是不能用于production,因為試用版會隨機刪掉0.1%的數(shù)據(jù)。
Terark命令行工具集
我們提供了一組命令行工具,這些工具可以將輸入數(shù)據(jù)壓縮成不同的形式,壓縮后的文件可以使用Terark API或(該工具集中的)其他命令行工具解壓或定點訪問。
詳情參見Terark wiki中文版(https://github.com/Terark/terark-wiki-zh_cn)。