踩坑小結!喜馬拉雅 FM 測試環境的 Docker 化實踐
隨著容器技術的流行,作為線上應用 Docker 的鋪墊,喜馬拉雅 FM 從 2016 年開始推進測試環境的 Docker 化。本文重點介紹筆者在 Docker 化的過程中如何進行技術選型、環境搭建,和實踐中碰到的一些問題及其解決方案。
為什么要Docker化?
1.標準化
- 配置標準化,以部署 Tomcat 為例,實際物理環境中,通常一臺物理機部署多個 Tomcat,這就存在 Tomcat 的端口及目錄管理問題。理想狀態下:一個項目一個主機 Tomcat,Tomcat 永遠位于/ usr / local / tomcat(或其他你喜歡的位置)下,對外端口是 8080,debug 端口是 8000。
- 部署標準化,現在云平臺越來越流行,同時,也不會立即丟棄物理環境,因此必然存在著同時向云環境和物理環境部署的問題。這就需要一系列工具,能夠屏蔽物理環境和云環境的差異,Docker 在其中扮演重要角色。
2.API 化
通過API接口操作項目的部署(CPU、內存分配、機器分配、實例數管理等),而不是原來物理機環境的的手工命令行操作。
3.自動化
調度系統可以根據API進行一些策略性的反應,比如自動擴容縮容。
上述工作,原有的技術手段不是不可以做,可是太麻煩,可用性和擴展性都不夠好。
Docker 化的四個小目標
1.業務之間不互相干擾
- 一個項目/ war 一虛擬機/容器
- Ip-pert-task
2.容器之間、容器與物理機之間可以互通
3.容器編排:健康檢查、容器調度等
4.使用方式:通過 yaml / json 來描述任務,通過 API 部署
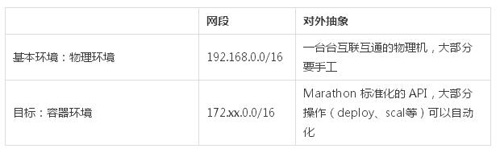
總結一下,基于 n 臺物理機搭建容器環境,整個工作的主線:
一個項目一個主機 ==>物理機資源不夠 ==>虛擬化 ==>輕量級虛擬化 ==> Docker ==>針對 Docker 容器帶來的網絡、存儲等問題 ==>集群編排 ==>對 CI / CD 的影響。
虛擬化網絡的兩種思路
Overlay
- 隧道,通常用到一個專門的解封包工具。
- 路由,每個物理機充當一個路由器,對外,將容器數據路由到目標機器上;對內,將收到的數據路由到目標容器中。
通常需要額外的維護物理機以及物理機上容器 IP(段)的映射關系。
Underlay
不準確的說,容器的網卡暴露在物理網絡中,直接收發,通常由外部設備(交換機)負責網絡的連通性。
經過對比,我們采用了 MacVLAN,主要是因為:
- 簡單
- 效率高
- 可將容器“當成”虛擬機用,容器之間互通就行,不需要支持復雜的網絡伸縮、隔離、安全等策略。
IP 分配問題
對于物理機、KVM 等虛擬機來說,它的生命周期很長,IP 一經分配便幾乎不變,因此通常由人工通過命令或 Web 界面手動分配。而對于 Docker 容器來說,尤其是測試環境,容器的創建和銷毀非常頻繁,這就涉及到頻繁的 IP 分配和釋放。因此,IP 分配必須是自動的,并且有一個 IP 資源池來管理 IP。
在 Docker 網絡中,CNM(Container Network Management)模塊通過 IPAM(IP address management)driver 管理 IP 地址的分配。我們基于 TalkingData/Shrike 改寫了自己的 IPAM 插件,fix 了在多實例部署模式(一個 Docker host 部署一個 IPAM,以防止單實例模式出現問題時,整個系統不可用的問題)下的重復存取問題。
Docker之外的編排工具
Docker 解決了單機的虛擬化,但當一個新部署任務到達,由集群中的哪一個 Docker 執行呢?因此,Docker 之外,需要一個編排工具,實現集群的資源管理和任務調度。

這些工具均采用 Master / Slave 架構,假設我們將物理機分為 Master 和 Slave,這些工具在 Slave 上運行一個 Agent(任務執行和數據上報),在 Master 上運行一個 Manager(任務分發和數據匯總)。從功能上說,任務分發和容器資源匯總,這些工具可以滿足要求。它們的根本區別就是:發展歷程的不同。
- 從一個 Docker / 容器化調度工具, 擴展成一個分布式集群管理工具
- 從一個分布式資源管理工具,增加支持 Docker 的 Feature
到目前為止,根據喜馬拉雅FM測試環境的實踐,發現有以下特點:
- 對編排的需求很弱,基本都是單個微服務項目的部署。微服務項目的協同、服務發現等由公司的服務治理框架負責。
- 基礎服務,比如 MySQL、Hadoop 等暫不上 Docker 環境。
- 需要查詢編排工具的 API 接口,同時有一個良好的 Web 界面,對編排工具的數據匯總、資源管理能力有一定要求。
因此我們決定使用 Marathon + Mesos 方案。在后面實踐的過程中,因為網絡和編排工具的選擇,IP 變化的問題帶來很大的困擾,我們甚至專門開發了幾個小工具,參見下文。
image 的組織
Docker 的厲害之處,不在于發明了一系列新技術,而在于整合了一系列老技術,廣為人知的阿里、騰訊等大廠在 Cgroups、Namespace 等基礎上搞了一套自己的容器工具。對于阿里,使用 Docker 初衷是 Docker 鏡像化,也就是其帶來的應用環境標準化,而不是容器化。
Docker鏡像的實踐主要涉及到以下三個問題:
1.搭建私有 imagerepository
2.對 layer 進行組織
3.鏡像的分發較慢
- 預分發,但這不解決根本,只適用部分場景
- 對 layer 進行壓縮,京東目前采用該方案
4.鏡像化帶來容器重啟
因為鏡像是一體的,哪怕只有一點更改,鏡像的發布都必須銷毀之前的容器,然后按照新鏡像創建新容器。耗時是一方面,對以下場景也很不友好:
- 只是更新一個文件,項目、容器均需要重啟
- 因為加載緩存等原因,項目、容器啟動比較耗時
對于具體的場景,可以有具體的辦法規避。對于通用的解決方案,阿里通過改寫 Docker,對鏡像支持 HotFix 標識,deploy 這類鏡像,不再創建新容器,而是更新容器。
我們要對鏡像的 layer 進行組織,以***化的復用 layer。
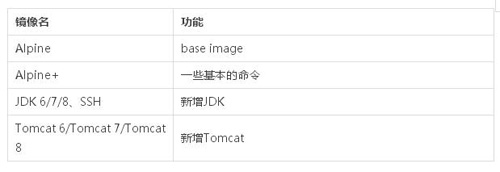
因為只是在測試環境使用,鏡像較慢的矛盾還不是太突出。這里有一個技術之外的問題。阿里對于 docker image feature 的改造,實現了如下優化:
- 可以減少容器的重啟次數,進而減少 IP 的分配和釋放。
- 影響到容器的編排策略,即 deploy 新的任務不再是選擇一個機器運行容器,而是找到原來的容器應用變更。
- 對 Docker 的各種特性的認識,一則認為天經地義,二則逆來順受。出現問題,要么想辦法規避,要么在外圍造個輪子去解決(還是規避)。
CI
Jenkins 如何跟 Marathon 結合,現成的方案很多。關鍵是提供幾套不同的模板,方便不同業務的使用。
容器變化帶來四大問題
使用 Docker 后,容器在物理機之間自由漂移,物理機的角色弱化成了:單純的提供計算資源。但帶來的問題是,影響了許多系統的正常運行。
1.IP 變化
許多系統的正常運行依賴 IP,但 IP 不穩定帶來一系列的問題。而解決IP的變化問題主要有以下方案:
- 新增組件屏蔽 IP 變化
- 提供 DNS 服務(有緩存和多實例問題)
- 不要改變 IP
既然重啟后,IP 會改變,就減少容器重啟
服務與 IP 綁定(這個方案非常不優雅)
對于 Web 服務,IP的變化導致要經常更改 Nginx 配置,為此,我們專門改寫了一個 Nginx 插件來解決這個問題。
對于 RPC 服務,技術團隊有獨立開發的服務治理系統,實現服務注冊和發現。但該系統有審核機制,對于跨語言調用,因為rpc客戶端不通用,仍有很多不便。
2.文件存儲
有許多項目會將業務數據存儲在文件中,這就意味著項目 deploy 進而容器重啟之后,要能找到并訪問這些文件。在 Docker 環境下主要有以下兩種方案:
- Dockervolumn + cluster fs
- Dockervolume plugin
我們當下主要采用***種,將 cluster fs mount 到每臺 Docker host 的特定目錄(例如 / data),打通 container / data ==> docker host / data == cluster fs / data,任意容器即可共享訪問 /data 目錄下的數據。
3.日志采集與查看
為了日志持久化存儲,技術將容器的日志目錄映射到了物理機上。but,一個項目的日志分散在多個物理機中。
原有的日志采集報警系統,負責日志采集、匯總、報警。因此容器化后,并不會有什么影響。但該系統只采集錯誤日志,導致開發人員要查看日志以調試程序時,比較麻煩。
最初,提供了一個 Web Console 來訪問容器,操作步驟為:login ==> findcontainer ==> input console ==> op。
但依然過于繁瑣,并且 Web Console 的性能也不理想。而直接為每個容器配置 ssh server,又會對 safe shutdown 等產生不良影響。因此:
- 登陸測試環境,90%是為了查看日志。
- 和開發約定項目的日志目錄,并將其映射到物理機下。
- 間接配置 SSH。每個物理機啟動一個固定 IP 的 SSHContainer,并映射日志目錄。
- 使用 Go 語言實現了一個 essh 工具,essh-imarathon_app_name 即可訪問對應的 SSH Container 實例并查看日志。
當然,日志的問題,也可以通過 elk 解決。
其他問題
1.Base image 的影響
- 時區、Tomcat PermGensize、編碼等參數值的修正。
- base image 為了盡可能精簡,使用了 alpine。它的一些文件缺失,導致一些Java代碼無法執行。比如,當去掉 / etc / hosts 中 ip 和容器主機名的映射后,加上 /etc/sysconfig/network 的缺失,導致 Java 代碼 InetAddress.getLocalHost()執行失敗。
2.Safeshutdown,部分服務退出時要保存狀態數據
3.支持 sshd,以方便大家查看日志文件
使用 supervisord(管理 SSH 和 Tomcat),需要通過 supervisord 傳導 。SIGTERM 信號給 Tomcat,以確保 Tomcat 可以 safeshutdown。該方法經常發生 supervisord 讓 Tomcat 退出,但自己不退出的情況。
每臺機器啟動跟一個專門的容器,映射一些必要的 volume,以供大家查看日志等文件。
4.Marathon 多機房主備問題
5.容器的漂移對日志采集、分析系統的影響
6.對容器提供 DNS 服務,以使其可以正確解析外部服務的 hostname
7.如何更好的推廣與應用的問題
todo
1.日志采集,簡化日志搜索
2.一個集中式的 DC
當下,項目部署的各個階段分散在不同的組件中。呈現出來的使用方式,不是面向用戶的。
- Jenkins 負責代碼的編譯和 Marathonjob 的觸發
- Marathon 負責任務調度、銷毀和回滾等
- Portainer 負責容器數據的界面化以及 WebConsole
這樣帶來的問題是:
對于運維人員來說,一些操作不能固化下來,比如回滾等,手工操作易出錯。
對于用戶來說,容易想當然的通過 portainer 進行增刪改容器的操作,進而引起系統的不一致。
因為是現成系統,很難加入技術自己的邏輯,這使得配置上經常出現一些語義沖突的情況。
李乾坤
喜馬拉雅 FM Java 開發工程師
李乾坤,喜馬拉雅 FM Java 開發工程師。2014 年開始接觸 Docker,2015 年東南大學碩士畢業,隨即加入喜馬拉雅 FM,從事后臺開發,2016 年參與測試環境 Docker 化,目前負責平臺支持業務的維護與開發。