許多SQL性能問題來自于“不必要的強制性工作”
在編寫高效 SQL 時,你可能遇到的最有影響的事情就是索引。但是,一個很重要的事實就是很多 SQL 客戶端要求數據庫做很多“不必要的強制性工作”。
跟我再重復一遍:
不必要的強制性工作
什么是“不必要的強制性工作”?這個意思包括兩個方面:
不必要的
假設你的客戶端應用程序需要這些信息:
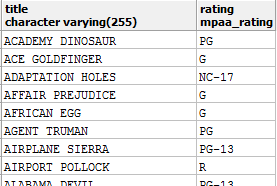
這沒什么特別的。我們運行著一個電影數據庫(例如 Sakila 數據庫),我們想要給用戶顯示每部電影的名稱和評分。
這是能產生上面結果的查詢:
- SELECT title, rating
- FROM film
然而,我們的應用程序(或者我們的 ORM(LCTT 譯注:對象關系映射(Object-Relational Mapping)))運行的查詢卻是:
- SELECT *
- FROM film
我們得到什么?猜一下。我們得到很多無用的信息:

甚至一些復雜的 JSON 數據全程在下列環節中加載:
- 從磁盤
- 加載到緩存
- 通過總線
- 進入客戶端內存
- 然后被丟棄
是的,我們丟棄了其中大部分的信息。檢索它所做的工作完全就是不必要的。對吧?沒錯。
強制性
這是最糟糕的部分。現今隨著優化器變得越來越聰明,這些工作對于數據庫來說都是強制執行的。數據庫沒有辦法知道客戶端應用程序實際上不需要其中 95% 的數據。這只是一個簡單的例子。想象一下如果我們連接更多的表...
你想想那會怎樣呢?數據庫還快嗎?讓我們來看看一些之前你可能沒有想到的地方:
內存消耗
當然,單次執行時間不會變化很大。可能是慢 1.5 倍,但我們可以忍受,是吧?為方便起見,有時候確實如此。但是如果你每次都為了方便而犧牲性能,這事情就大了。我們不說性能問題(單個查詢的速度),而是關注在吞吐量上時(系統響應時間),事情就變得困難而難以解決。你就會受阻于規模的擴大。
讓我們來看看執行計劃,這是 Oracle 的:
- --------------------------------------------------
- | Id | Operation | Name | Rows | Bytes |
- --------------------------------------------------
- | 0 | SELECT STATEMENT | | 1000 | 166K|
- | 1 | TABLE ACCESS FULL| FILM | 1000 | 166K|
- --------------------------------------------------
對比一下:
- --------------------------------------------------
- | Id | Operation | Name | Rows | Bytes |
- --------------------------------------------------
- | 0 | SELECT STATEMENT | | 1000 | 20000 |
- | 1 | TABLE ACCESS FULL| FILM | 1000 | 20000 |
- --------------------------------------------------
當執行 SELECT * 而不是 SELECT film, rating 的時候,我們在數據庫中使用了 8 倍之多的內存。這并不奇怪,對吧?我們早就知道了。在很多我們并不需要其中全部數據的查詢中我們都是這樣做的。我們為數據庫產生了不必要的強制性工作,其后果累加了起來,就是我們使用了多達 8 倍的內存(當然,數值可能有些不同)。
而現在,所有其它的步驟(比如,磁盤 I/O、總線傳輸、客戶端內存消耗)也受到相同的影響,我這里就跳過了。另外,我還想看看...
索引使用
如今大部分數據庫都有涵蓋索引(LCTT 譯注:covering index,包括了你查詢所需列、甚至更多列的索引,可以直接從索引中獲取所有需要的數據,而無需訪問物理表)的概念。涵蓋索引并不是特殊的索引。但對于一個特定的查詢,它可以“意外地”或人為地轉變為一個“特殊索引”。
看看這個查詢:
- SELECT *
- FROM actor
- WHERE last_name LIKE 'A%'
執行計劃中沒有什么特別之處。它只是個簡單的查詢。索引范圍掃描、表訪問,就結束了:
- -------------------------------------------------------------------
- | Id | Operation | Name | Rows |
- -------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 8 |
- | 1 | TABLE ACCESS BY INDEX ROWID| ACTOR | 8 |
- |* 2 | INDEX RANGE SCAN | IDX_ACTOR_LAST_NAME | 8 |
- -------------------------------------------------------------------
這是個好計劃嗎?如果我們只是想要這些,那么它就不是:
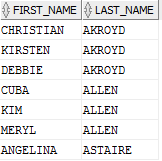
當然,我們浪費了內存之類的。再來看看這個查詢:
- SELECT first_name, last_name
- FROM actor
- WHERE last_name LIKE 'A%'
它的計劃是:
- ----------------------------------------------------
- | Id | Operation | Name | Rows |
- ----------------------------------------------------
- | 0 | SELECT STATEMENT | | 8 |
- |* 1 | INDEX RANGE SCAN| IDX_ACTOR_NAMES | 8 |
- ----------------------------------------------------
現在我們可以完全消除表訪問,因為有一個索引涵蓋了我們查詢需要的所有東西……一個涵蓋索引。這很重要嗎?當然!這種方法可以將你的某些查詢加速一個數量級(如果在某個更改后你的索引不再涵蓋,可能會降低一個數量級)。
你不能總是從涵蓋索引中獲利。索引也有它們自己的成本,你不應該添加太多索引,例如像這種情況就是不明智的。讓我們來做個測試:
- SET SERVEROUTPUT ON
- DECLARE
- v_ts TIMESTAMP;
- v_repeat CONSTANT NUMBER := 100000;
- BEGIN
- v_ts := SYSTIMESTAMP;
- FOR i IN 1..v_repeat LOOP
- FOR rec IN (
- -- Worst query: Memory overhead AND table access
- SELECT *
- FROM actor
- WHERE last_name LIKE 'A%'
- ) LOOP
- NULL;
- END LOOP;
- END LOOP;
- dbms_output.put_line('Statement 1 : ' || (SYSTIMESTAMP - v_ts));
- v_ts := SYSTIMESTAMP;
- FOR i IN 1..v_repeat LOOP
- FOR rec IN (
- -- Better query: Still table access
- SELECT /*+INDEX(actor(last_name))*/
- first_name, last_name
- FROM actor
- WHERE last_name LIKE 'A%'
- ) LOOP
- NULL;
- END LOOP;
- END LOOP;
- dbms_output.put_line('Statement 2 : ' || (SYSTIMESTAMP - v_ts));
- v_ts := SYSTIMESTAMP;
- FOR i IN 1..v_repeat LOOP
- FOR rec IN (
- -- Best query: Covering index
- SELECT /*+INDEX(actor(last_name, first_name))*/
- first_name, last_name
- FROM actor
- WHERE last_name LIKE 'A%'
- ) LOOP
- NULL;
- END LOOP;
- END LOOP;
- dbms_output.put_line('Statement 3 : ' || (SYSTIMESTAMP - v_ts));
- END;
- /
結果是:
- Statement 1 : +000000000 00:00:02.479000000
- Statement 2 : +000000000 00:00:02.261000000
- Statement 3 : +000000000 00:00:01.857000000
注意,表 actor 只有 4 列,因此語句 1 和 2 的差別并不是太令人印象深刻,但仍然很重要。還要注意我使用了 Oracle 的提示來強制優化器為查詢選擇一個或其它索引。在這種情況下語句 3 明顯勝利。這是一個好很多的查詢,也是一個十分簡單的查詢。
當我們寫 SELECT * 語句時,我們為數據庫帶來了不必要的強制性工作,這是無法優化的。它不會使用涵蓋索引,因為比起它所使用的 LAST_NAME 索引,涵蓋索引開銷更多一點,不管怎樣,它都要訪問表以獲取無用的 LAST_UPDATE 列。
使用 SELECT * 會變得更糟。考慮一下……
SQL 轉換
優化器工作的很好,因為它們轉換了你的 SQL 查詢(看我最近在 Voxxed Days Zurich 關于這方面的演講)。例如,其中有一個稱為“表連接消除”的轉換,它真的很強大。看看這個輔助視圖,我們寫了這個視圖是因為我們非常討厭總是連接所有這些表:
- CREATE VIEW v_customer AS
- SELECT
- c.first_name, c.last_name,
- a.address, ci.city, co.country
- FROM customer c
- JOIN address a USING (address_id)
- JOIN city ci USING (city_id)
- JOIN country co USING (country_id)
這個視圖僅僅是把 CUSTOMER 和他們不同的 ADDRESS 部分所有“對一”關系連接起來。謝天謝地,它很工整。
現在,使用這個視圖一段時間之后,想象我們非常習慣這個視圖,我們都忘了所有它底層的表。然后,我們運行了這個查詢:
- SELECT *
- FROM v_customer
我們得到了一個相當令人印象深刻的計劃:
- ----------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost |
- ----------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 599 | 47920 | 14 |
- |* 1 | HASH JOIN | | 599 | 47920 | 14 |
- | 2 | TABLE ACCESS FULL | COUNTRY | 109 | 1526 | 2 |
- |* 3 | HASH JOIN | | 599 | 39534 | 11 |
- | 4 | TABLE ACCESS FULL | CITY | 600 | 10800 | 3 |
- |* 5 | HASH JOIN | | 599 | 28752 | 8 |
- | 6 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
- | 7 | TABLE ACCESS FULL| ADDRESS | 603 | 17487 | 3 |
- ----------------------------------------------------------------
當然是這樣。我們運行了所有這些表連接以及全表掃描,因為這就是我們讓數據庫去做的:獲取所有的數據。
現在,再一次想一下,對于一個特定場景,我們真正想要的是:
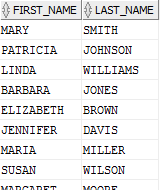
是啊,對吧?現在你應該知道我的意圖了。但想像一下,我們確實從前面的錯誤中學到了東西,現在我們實際上運行下面一個比較好的查詢:
- SELECT first_name, last_name
- FROM v_customer
再來看看結果!
- ------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost |
- ------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 599 | 16173 | 4 |
- | 1 | NESTED LOOPS | | 599 | 16173 | 4 |
- | 2 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
- |* 3 | INDEX UNIQUE SCAN| SYS_C007120 | 1 | 8 | 0 |
- ------------------------------------------------------------------
這是執行計劃一個極大的進步。我們的表連接被消除了,因為優化器可以證明它們是不必要的,因此一旦它可以證明這點(而且你不會因使用 select * 而使其成為強制性工作),它就可以移除這些工作并不執行它。為什么會發生這種情況?
每個 CUSTOMER.ADDRESS_ID 外鍵保證了有且只有一個 ADDRESS.ADDRESS_ID 主鍵值,因此可以保證 JOIN 操作是對一連接,它不會產生或者刪除行。如果我們甚至不選擇行或查詢行,當然我們就不需要真正地去加載行。可以證實地移除 JOIN 并不會改變查詢的結果。
數據庫總是會做這些事情。你可以在大部分數據庫上嘗試它:
- -- Oracle
- SELECT CASE WHEN EXISTS (
- SELECT 1 / 0 FROM dual
- ) THEN 1 ELSE 0 END
- FROM dual
- -- 更合理的 SQL 語句,例如 PostgreSQL
- SELECT EXISTS (SELECT 1 / 0)
在這種情況下,當你運行這個查詢時你可能預料到會拋出算術異常:
- SELECT 1 / 0 FROM dual
產生了:
- ORA-01476: divisor is equal to zero
但它并沒有發生。優化器(甚至解析器)可以證明 EXISTS (SELECT ..) 謂詞內的任何 SELECT 列表達式不會改變查詢的結果,因此也就沒有必要計算它的值。呵!
同時……
大部分 ORM 最不幸問題就是事實上他們很隨意就寫出了 SELECT * 查詢。事實上,例如 HQL / JPQL,就設置默認使用它。你甚至可以完全拋棄 SELECT 從句,因為畢竟你想要獲取所有實體,正如聲明的那樣,對吧?
例如:
FROM v_customer
例如 Vlad Mihalcea(一個 Hibernate 專家和 Hibernate 開發倡導者)建議你每次確定不想要在獲取后進行任何更改時再使用查詢。ORM 使解決對象圖持久化問題變得簡單。注意:持久化。真正修改對象圖并持久化修改的想法是固有的。
但如果你不想那樣做,為什么要抓取實體呢?為什么不寫一個查詢?讓我們清楚一點:從性能角度,針對你正在解決的用例寫一個查詢總是會勝過其它選項。你可以不會在意,因為你的數據集很小,沒關系。可以。但最終,你需要擴展并重新設計你的應用程序以便在強制實體圖遍歷之上支持查詢語言,就會變得很困難。你也需要做其它事情。
計算出現次數
資源浪費最嚴重的情況是在只是想要檢驗存在性時運行 COUNT(*) 查詢。例如:
這個用戶有沒有訂單?
我們會運行:
- SELECT count(*)
- FROM orders
- WHERE user_id = :user_id
很簡單。如果 COUNT = 0:沒有訂單。否則:是的,有訂單。
性能可能不會很差,因為我們可能有一個 ORDERS.USER_ID 列上的索引。但是和下面的這個相比你認為上面的性能是怎樣呢:
- -- Oracle
- SELECT CASE WHEN EXISTS (
- SELECT *
- FROM orders
- WHERE user_id = :user_id
- ) THEN 1 ELSE 0 END
- FROM dual
- -- 更合理的 SQL 語句,例如 PostgreSQL
- SELECT EXISTS (
- SELECT *
- FROM orders
- WHERE user_id = :user_id
- )
它不需要火箭科學家來確定,一旦它找到一個,實際存在謂詞就可以馬上停止尋找額外的行。因此,如果答案是“沒有訂單”,速度將會是差不多。但如果結果是“是的,有訂單”,那么結果在我們不計算具體次數的情況下就會大幅加快。
因為我們不在乎具體的次數。我們告訴數據庫去計算它(不必要的),而數據庫也不知道我們會丟棄所有大于 1 的結果(強制性)。
當然,如果你在 JPA 支持的集合上調用 list.size() 做同樣的事情,情況會變得更糟!
近期我有關于該情況的博客以及在不同數據庫上的測試。去看看吧。
總結
這篇文章的立場很“明顯”。別讓數據庫做不必要的強制性工作。
它不必要,因為對于你給定的需求,你知道一些特定的工作不需要完成。但是,你告訴數據庫去做。
它強制性,因為數據庫無法證明它是不必要的。這些信息只包含在客戶端中,對于服務器來說無法訪問。因此,數據庫需要去做。
這篇文章大部分在介紹 SELECT *,因為這是一個很簡單的目標。但是這并不僅限于數據庫。這關系到客戶端要求服務器完成不必要的強制性工作的任何分布式算法。你的 AngularJS 應用程序平均有多少個 N+1 問題,UI 在服務結果 A 上循環,多次調用服務 B,而不是把所有對 B 的調用打包為一個調用?這是一個復發的模式。
解決方法總是相同。你給執行你命令的實體越多信息,(理論上)它能更快執行這樣的命令。每次都寫一個好的查詢。你的整個系統都會為此感謝你的。
如果你喜歡這篇文章...
再看看近期我在 Voxxed Days Zurich 的演講,其中我展示了一些在數據處理算法上為什么 SQL 總是會勝過 Java 的雙曲線例子。
(題圖:Pixabay, CC0)