面向圖像分析應用的海量樣本過濾方案
在圖像分析應用中,海量圖片樣本的有效自動化過濾是一項重要的基礎工作。本文介紹一種基于多重算法過濾的處理方案,能夠自動提取有效圖像樣本,極大減少人工標注的工作量。
背景及問題描述
深度學習技術在計算機視覺領域取得了巨大的成功,其標志性事件之一就是計算機算法在Imagenet競賽中的目標識別準確率已經超過了人類。在學術圈的創新成果爆發式涌現的同時,各大企業也利用深度學習技術,推出了眾多圖像分析相關的人工智能相關產品及應用系統。這些成果所采用的技術路線,很多都是利用海量的已標注樣本數據,在深度神經網絡上訓練相應的識別或檢測模型。就企業算法應用而言,往往需要根據實際的應用場景,構建自己的訓練樣本集,以提升算法的有效性。在深度學習大行其道的今天,能夠獲得大量高質量標注樣本,更是搭建高效應用算法系統的重要前提。一方面,深度學習與傳統算法相比,其突出特征之一就是提供的訓練樣本越多,算法的精準性越高;另一方面,盡管無監督的深度學習算法在學術領域也獲得了相當大的進步,但就目前而言,有監督的深度學習算法仍然是主流,對于企業級應用更是如此。
其中對于圖像識別類的算法應用,通常需要獲得不同類別對象的足量樣本圖像。其樣本來源,可以有四種基本途徑:
- 實地拍攝相關物品,此類方法效率比較低,適用于類別較少,每類需要大量高質量樣本的情況,比如目標檢測;
- 識別對象如果是商品,可以利用其商品主圖,但商品主圖經過圖像處理,且較為單一,與實際場景不符;
- 在不同網站通過文本搜索或匹配獲取相關的網絡圖像,此類方法可以獲得大量的圖像樣本;
- 通過圖像生成的方式來獲得樣本圖像,比如近年來發展很快的生成對抗網絡(GAN),此類方法的前景非常看好,但目前來說在大量不同類別上的效果還有待提升。

圖1 不同渠道獲取的商品圖像樣本示例: a 擺拍,b 主圖,c 網絡圖像
目前而言,第三種獲取網絡圖像的方式是常規采用的樣本收集方案。
網絡來源的圖像樣本,其存在的一個主要問題是噪聲圖像非常嚴重,如果采用主題詞搜索得到待選圖像集合,里面的不相關圖像占據了很大的比例,且來源較為隨機;如果采用電商網站曬單圖作為待選圖像集合,里面同樣包含著發票、外包裝、聊天紀錄等大量無關圖像以及頂視圖或近視圖等不合規圖像。因此必須要對得到的圖像集進行過濾,篩查出其中的噪聲圖像。這種過濾如果用人工進行篩選則過于低效,很難滿足實際要求,應該用算法自動篩選為主、人工校驗為輔的方式來實現。本文下面針對這一問題,介紹一種實用的基于多重處理的圖像樣本過濾方法。
思路及技術步驟
通過網絡直接得到的圖像樣本集合,一般有以下幾個特點。
- 噪聲圖像可分為:重復圖像和極相似圖像、常見噪聲圖像、無規律的雜亂噪聲圖像,各自均占有一定比例;
- 目標樣本圖像也占有一定比例,且相對于噪聲圖像而言,其類內相似度較高。
參照以上的問題特點,可以針對性得到一些解決的思路:
- 對于多且雜的噪聲數據,采取多重處理的方式來逐步篩除。噪聲數據類型比較多變,采用單一的方法很難全部加以篩除。根據其特點加以多輪的粗篩和精篩,逐批的處理不同類型的噪聲數據,可以降低每個環節的技術風險,保證每個環節的有效性。
- 由于目標在樣本空間中分布較為集中,如果對待選樣本集進行無監督聚類,目標樣本會集中在較為緊湊的聚類上。相比于噪聲圖像的無序雜亂而言,目標樣本自身的類內差距還是比較小的,通過對大量實際數據的觀察可以印證這一點。
- 對于某一樣本,分類器返回的類別置信度可以作為樣本與該類別相關度的度量。普通聚類算法不易量化樣本點與所屬聚類的相關度,無法做更為精細的樣本篩選。相比之下利用分類器得到的類別置信度,可以作為相關度的合適度量,用來精細挑選剩余的噪聲樣本。

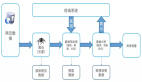
圖2 技術方案概要圖
根據以上的解決思路,設計出一個多重過濾的技術方案,其具體流程可分為如下幾個步驟(參見圖2):
- 圖像去重:去除重復圖像及極相似圖像;
- 常見噪聲圖像過濾:過濾掉人臉、包裝、發票等無關的常見類型噪聲圖像;
- 基于聚類的樣本挑選:在深度特征空間上進行聚類,選取合適的聚類作為目標樣本,并將其他聚類作為噪聲圖像去除;
- 基于分類的樣本篩選:利用分類器返回的置信度來評估樣本與相應類別的相關度,進一步篩選樣本。
詳細介紹
圖像去重及常見噪聲圖像過濾
待選樣本集里含有較多的重復圖像或極相似圖像,可以通過不同的方式去重:提取圖像的直方圖特征向量,利用特征向量之間的相似性進行去重;或者構建一個哈希表,提取圖像的簡單顏色和紋理特征,對特征量化后利用哈希表進行查詢,能夠查詢到的就是重復或極相似圖像,查詢不到的加入表中。前一種方法對于微小差異表現更好,后一種方法的計算性能優勢明顯。
待選樣本集里往往會含有一些常見的噪聲圖像模式,比如人臉、紙箱外包裝、發票、聊天紀錄圖、商品或店鋪Logo圖等,占有相當高的比例。對于這些常見噪聲圖像,先提取其HOG特征,并用提前訓練好的SVM分類器對其進行分類。為了保證精度,對于不同類的噪聲圖像,分別訓練1vN的SVM分類器,只要圖像判別為其中任一類噪聲圖像,即將其篩出。
以上兩步,只利用了圖像的簡單特征,只能夠去除樣本集里的重復圖像和常見噪聲圖像,對于更復雜的噪聲圖像模式,需要利用更有效的圖像特征,并對于復雜類別采用無監督聚類來挖掘。
基于聚類的樣本挑選
要利用圖像本身的豐富信息對其進行聚類,首先需要提取更為豐富的圖像特征。因此可利用深度網絡模型來提取圖像特征,得到的特征融合了常見的圖像基本特征,并包含了更為高階的圖像語義信息,具有更強的表現能力。這里借助在Imagenet數據集上訓練得到的網絡模型,并利用已有的樣本集進行fine-tune,這樣模型對于特定品類的表達能力得到增強。這里對于一個圖像樣本,通過深度網絡得到的特征是1024維向量,進一步通過PCA降維成256維的特征向量。這樣圖像樣本集就構成了一個特征數據空間。
接下來,在降維后的特征數據空間,利用一種基于密度的聚類算法進行聚類。該算法最突出的特點采用了一種新穎的聚類中心選擇方法,其準則可描述為:
- 聚類中心附近的點密度很大,且其密度大于其任何鄰居點的密度;
- 聚類中心和點密度比它更大的數據點,它們的距離是比較大的。
選擇了合適的聚類中心之后,再將各數據點分類到離其最近的聚類上,并根據各點距離相應聚類中心的遠近,把它們劃分成核心數據點和邊緣數據點。
該聚類算法思路簡單,效率較高,并且對于不同的場景具有較好的魯棒性。
在所得的聚類結果中,進一步選出密度較大且半徑較為緊湊的聚類,其中的樣本作為待選的目標樣本數據,而其他聚類對應的樣本則作為噪聲樣本予以篩除。
基于分類的樣本篩選
以上聚類所得的目標樣本中,可能還含有少數的不相關樣本,需要進一步的篩選。這里利用分類器的置信度評估樣本的類別相關度,其中與所屬類別不相關或弱相關的樣本可以進一步去除。
具體方法是從目標樣本中隨機可放回的選取若干樣本,并打上新的類別標簽,作為新的訓練樣本,對一個已有的卷積神經網絡模型進行fine-tune,這個卷積神經網絡模型與前面提取特征的網絡模型必須有一定差異(模型結構和訓練數據都不同)。利用這個新的模型,對目標樣本進行識別,得到其類別置信度。如果某個樣本在所屬類別上置信度很低,則將該樣本作為不相關樣本予以篩除。
經過以上篩選之后,最終得到的目標樣本經過人工簡單校驗,就可以作為高質量樣本集用于訓練和測試。
應用效果
通過對于從網絡獲取的上萬類別的近500萬樣本圖像進行處理,并由人工校驗算法的篩選結果。最終所得的目標樣本,總體的類別相關度達到95%,其中對于較為熱門的類別,樣本相關度可以達到99%以上,總效率超過人工篩選百倍以上。圖3左邊是篩選得到的目標樣本,右邊是篩除掉的噪聲圖像。
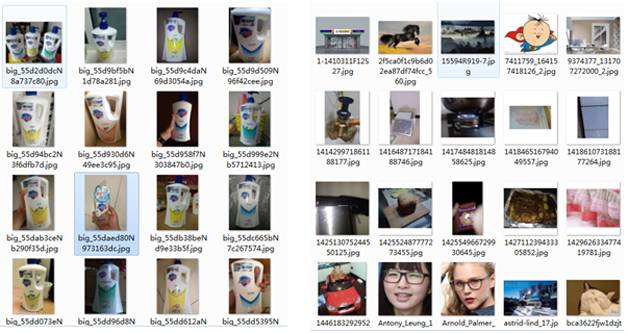
圖3 樣本圖像篩選結果示例
蘇寧“智能視覺圖譜”是一個綜合性的圖像、視頻相關算法平臺,其宗旨是為公司內外的相關業務場景提供應用算法服務。目前所提供的算法接口包括商品識別、人臉特征分析及人臉驗證、Logo檢測、敏感圖分析、廣告敏感詞分析、圖像摳圖等,分別涉及商品內容識別、人臉識別、目標檢測、敏感圖識別、OCR算法、圖像分割及摳圖等算法領域,平臺所支持的算法服務還在進一步增加中,已有算法的效果與性能也在不斷優化,以滿足各種實際應用場景的需要。其中較多與識別相關的算法服務,都需要利用足量樣本數據訓練高精度的分類器。上文所述技術方案已廣泛應用于當中商品圖像識別、敏感圖識別、Logo識別等應用算法的樣本篩選工作,極大的提升了開發效率,節省了人力成本,并為高效算法模型的訓練提供了可靠的數據保障。以商品圖像識別類算法為例,利用以上樣本收集和過濾方式獲得***別的真實圖像樣本,以ResNet模型為架構,訓練出高準確率的商品識別模型,并在此基礎上搭建了面向全品類商品的圖像檢索系統,并廣泛應用于商品種類識別、基于外形的商品推薦、商品圖像檢索、基于外形相似度的商品匹配等實際業務場景。
總結
在企業級深度學習圖像應用中,海量高質量圖像樣本的獲取,是取得優異算法性能的重要前提。工程實踐中,在圖像樣本嚴重不足的情況下,僅僅對樣本進行數據增強,都可以在測試集上獲得幾個百分點的效果提升,如果能夠增加豐富真實的樣本數據,對于相應類別的識別率提升更是立竿見影,而且泛化性能很好,可以經受住各種實際場景的考驗。因此樣本工程(圖像樣本的獲取和挑選)是絕對不能忽視的重要工作,而且需要長期進行下去。不過,“爬圖容易挑圖難”,即使積累了海量樣本數據,卻因為缺乏有效的處理手段和標注人力而望洋興嘆,這也是經常遇到的一種數據困境。
本文主要介紹了我們在這個問題上的一種實踐方案,其結果說明,采用多重過濾的方式,充分利用初級特征、深度特征等特征表達方式和無監督聚類、深度分類器等分類方法,就可以從紛繁蕪雜的網絡圖像中,有效抽取高質量的目標樣本。另外,我們也看到深度學習領域在不斷取得新的研究成果,其中無監督式的深度學習更符合人類的認知習慣,且對樣本質量沒有如此苛刻的要求,該領域理論和技術的飛速發展對企業深度學習應用將意味著更為光明的未來。
主要參考文獻:
1. Clustering by fast search and find of density peaks, Science, 2014, 344(6191):1492-6, Alex Rodriguez and Alessandro Laio,.
2. Extracting Visual Knowledge from the Internet, Y Yao,J Zhang,XS Hua,F Shen,Z Tang.
3. Going deeper with convolutions[J]. arXiv preprint arXiv:1409.4842, 2014, Szegedy C, Liu W, Jia Y, et al.
4. Deep Residual Learning for Image Recognition,Computer Vision and Pattern Recognition , 2015 :770-778,K He, X Zhang, S Ren, J Sun.