橫向?qū)Ρ?大開源語音識(shí)別工具包,CMU Sphinx最佳
目前開源世界里存在多種不同的語音識(shí)別工具包,它們?yōu)殚_發(fā)者構(gòu)建應(yīng)用提供了很大幫助。這些工具各有哪些優(yōu)劣?數(shù)據(jù)科學(xué)公司 Silicon Valley Data Science 為我們帶來了 5 種流行工具包的深度橫向?qū)Ρ取4饲埃麄冊鵀槲覀儙磉^流行深度學(xué)習(xí)框架的對比:《從 TensorFlow 到 Theano:橫向?qū)Ρ绕叽笊疃葘W(xué)習(xí)框架》。
作為深度學(xué)習(xí)研發(fā)團(tuán)隊(duì)的一員,我們對于循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和其他語音識(shí)別需要用到的方法都有所涉及。在幾年之前,業(yè)內(nèi)***的語音識(shí)別系統(tǒng)還是基于語音分析的方法,包含發(fā)音、聲學(xué)和語言模型。通常,這些方法包含 n-gram 語言模型,以及隱馬爾科夫模型(HMM)。在此,我們以這種模型作為基準(zhǔn),試圖對比目前流行的一些語音識(shí)別方法。迄今為止,我們很難看到有人對開源語音識(shí)別模型進(jìn)行過真正對比,希望本文可以拋磚引玉,為大家?guī)硪恍椭?/p>
本文回顧了使用傳統(tǒng) HMM&n-gram 語言模型的開源語音識(shí)別工具包。對于用戶而言,大多數(shù)人都會(huì)知道 Siri 或 Cortana 這樣的消費(fèi)產(chǎn)品。而對于研發(fā)工程師來說,更靈活、更具專注性的解決方案則更符合需求,很多公司都會(huì)研發(fā)自己的語音識(shí)別通路。以下是目前開源世界上出現(xiàn)的流行工具包,以及我們對它們的各項(xiàng)評價(jià)。
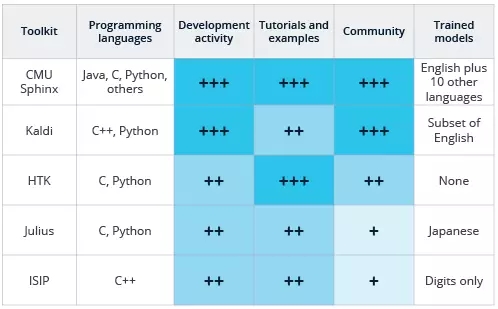
開源免費(fèi)語音識(shí)別工具包橫向?qū)Ρ?/p>
本次分析基于 svds 開發(fā)者的主觀經(jīng)驗(yàn)和開源社區(qū)的已有消息。上表列出了目前大部分流行的語音識(shí)別軟件(但略微超出開源的范疇)。2014 年 Gaida 等人的一篇論文評估了 CMU Sphinx、Kaldi 和 HTK。其中 HTK 嚴(yán)格意義上來說并不是開源的,因?yàn)槠浯a并不能重用或作為商業(yè)用途使用。
編程語言
因?yàn)橛脩羰褂谜Z言的情況各不相同,你可能會(huì)對特定的工具包有自己的偏好。以上工具除了 ISIP 以外都有 Python 的封裝,雖然在一些情況下,Python 封裝并不包括核心代碼的全部功能。CMU Sphinx 也包含了其他幾種編程語言,如 Java 和 C。
開發(fā)工作
在學(xué)術(shù)研究中,所有列出的項(xiàng)目都包含它們的來源。CMU Sphinix,顯而易見,從它的名字就能看出來是卡內(nèi)基梅隆大學(xué)的產(chǎn)物。它已經(jīng)以某些形式存在了 20 年了,現(xiàn)在它在 Github(C (https://github.com/cmusphinx/pocketsphinx) 版本和 Java (https://github.com/cmusphinx/sphinx4) 版本)和 SourceForge (https://sourceforge.net/projects/cmusphinx/) 上都開源了,而且兩個(gè)平臺(tái)上都有***活動(dòng)。Github 上的 Java 版本和 C 版本都只有一個(gè)貢獻(xiàn)者,但是這并不影響此項(xiàng)目的歷史真實(shí)性(在 SourceForge repo 上有 9 個(gè)管理人員還有很多開發(fā)者)。
Kaldi 從 2009 年的研討會(huì)起就有它的學(xué)術(shù)根基了,現(xiàn)在已經(jīng)在 GitHub (https://github.com/kaldi-asr/kaldi) 上開源,有 121 名貢獻(xiàn)者。HTK 始于 1989 年的劍橋大學(xué),已經(jīng)商用一段時(shí)間了,但是現(xiàn)在它的版權(quán)又回到了劍橋大學(xué)并且已經(jīng)不是開源軟件了。它的***版本更新于 2015 年 12 月,先前發(fā)布于 2009 年。Julius (http://julius.osdn.jp/en_index.php) 起源于 1997 年,***一個(gè)主要版本發(fā)布于 2016 年 9 月,有些活躍的 Github repo 包含三個(gè)貢獻(xiàn)者,現(xiàn)在已經(jīng)不大可能反應(yīng)真實(shí)情況了。ISIP 是***個(gè)***型的開源語音識(shí)別系統(tǒng),源于密西西比州立大學(xué)。它主要發(fā)展于 1996 到 1999 年間,***版本發(fā)布于 2011 年,但是這個(gè)項(xiàng)目在 Github 出現(xiàn)前就已經(jīng)不復(fù)存在了。
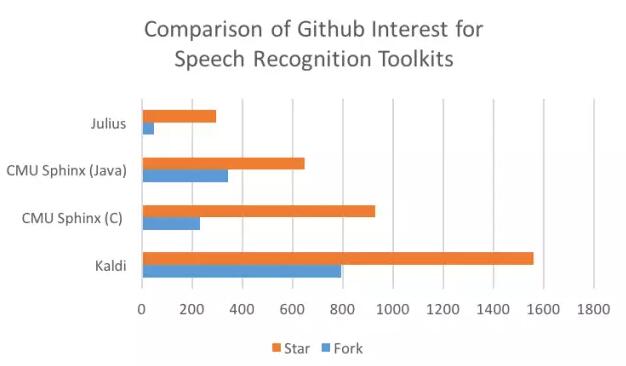
社區(qū)
這里我們關(guān)注一下郵件、討論群還有開發(fā)者團(tuán)體的情況。CMU Sphinx 在它的 repos 上有著在線交流論壇和積極的關(guān)注。然而,我們想知道復(fù)制 SourceForge 和 GitHub 的 repo 是否阻礙了更多的投稿。相比之下,Kaldi 不僅有著論壇和討論群,還有一個(gè)活躍的 GitHub repo。HTK 也有討論群但是沒有開放資源庫。Julius 網(wǎng)站上的用戶論壇壞掉了,但是在日本站里可能有更多的信息。ISIP 主要用于教育目的,而且郵件清單檔案現(xiàn)在已經(jīng)不再實(shí)用。
教程和例子
CMU Sphinx 的教程非常具有可讀性,易于學(xué)習(xí),Kaldi 的文檔也很全面,但似乎更難理解。不過 Kaldi 的內(nèi)容覆蓋了語音識(shí)別中的語音和深度學(xué)習(xí)方法。如果你缺乏語音識(shí)別的知識(shí),HTK 的教程文檔(注冊用戶可看)對這一領(lǐng)域有詳盡的描述。Julius 項(xiàng)目聚焦于日語,***的資料就是 Japanese2 (https://www.svds.com/open-source-toolkits-speech-recognition/#fn2),但是他們也主動(dòng)地譯成英文,并且也提供相關(guān)資料;這里列有一些運(yùn)行語音識(shí)別的實(shí)例(https://github.com/julius-speech/dictation-kit)。ISIP 也有一些資料,但是有些難以瀏覽。
訓(xùn)練模型
即使你使用這些開源工具的***理由是訓(xùn)練特定的識(shí)別模型,其他語音功能也會(huì)是它們吸引人的地方。CMU Sphinx 包含英語和很多其他即開即用的模型,在該項(xiàng)目 GitHub 的 redme 上,我們可以很容易地找到它們。而 Kaldi 對現(xiàn)有模型進(jìn)行解碼的指令深深地隱藏在文檔中,我們最終在 egs/voxforge 子目錄的 repo 下發(fā)現(xiàn)了一個(gè)英語 VoxForge 數(shù)據(jù)集訓(xùn)練后的模型,而識(shí)別功能在 online-data 子目錄下。其他三個(gè)軟件包沒有容易找到的功能,但它們至少都有適配 VoxForge 格式的簡單模型,后者是一個(gè)語音識(shí)別數(shù)據(jù)和訓(xùn)練模型的著名眾包網(wǎng)站。
原文:http://www.kdnuggets.com/2017/03/open-source-toolkits-speech-recognition.html
【本文是51CTO專欄機(jī)構(gòu)“機(jī)器之心”的原創(chuàng)譯文,微信公眾號“機(jī)器之心( id: almosthuman2014)”】


 分享到微信
分享到微信  分享到微博
分享到微博