













魅族運維進化史:從“遠古時代”到“鐵器時代”的艱難蛻變
魅族的互聯網業務起步較早,從 2011 年開始,到 2014 年才真正轉變為一家移動互聯網公司。隨著業務的增長,魅族的運維架構在不斷的變更優化,運維團隊面臨著越來越大的挑戰,服務器規模從 2000 年只有 5 臺的規模擴展到 2016 年超過了 6000 多臺。
下面主要從三個方面介紹魅族基礎架構的運維之路:
- 發展歷程;
- 運維體系實踐;
- 運維的未來展望。
魅族運維的艱難蛻變
這幾年,工程師圍繞質量、效率、流程、成本展開運維,并且發現工作中遇到的問題,慢慢由運維轉化成技術運營,需要優化工作流程,提高運維的技術能力。這其中包括填坑、標準化,自動化、流程化和數據化,以及對未來混合云運營的一個展望。
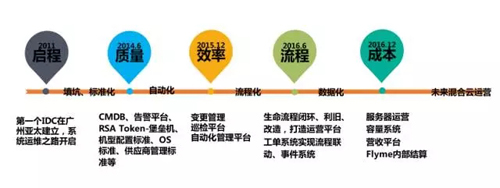
下面按照發展歷程中的各個時代進行說明:
遠古時代
2011 年,公司規模比較小,只有機柜 1 個,服務器 5 臺,業務線 2 條,主要存在的問題有:
- 機房穩定性差。服務器經常宕機,系統要重裝,這些需要人力支撐。
相應的解決方法:在穩定性方面,運維團隊有 IDC 的操作人員協助工程師做一些管理和操作,另外通過帶外的管理口對服務器做一些操作,對系統進行重裝。
- 監控造成的損失。服務器上線之后沒有及時地監控,出現故障之后不能及時解決,業務的穩定性得不到保障。
相應的解決方法:一些自動化的腳本,在自動監控方面早期部署了 Nagios Cacti,來監控系統穩定性,網絡以及業務穩定性。
- 架構單點。業務上線之后沒有部署高可用架構,對業務的穩定性有影響,比如官網、論壇等等。
- 相應的解決方法:在架構單點方面,主要靠人為來驅動,推動業務部署高可用架構,提高業務的可用性。
石器時代
魅族逐步向移動互聯網開始轉型,架構如下:
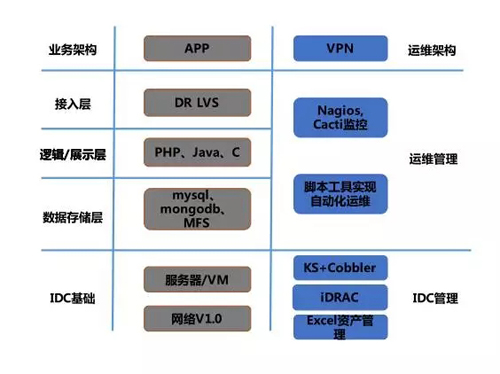
IDC 還是 1 個,機柜增長了 30 個,服務器和虛擬機的數量增長了 800 臺,業務線拓展到 100 個,人力方面,運維人員擴展到了 12 個,存在的主要問題有:
- 機房存在著很多 IBM 的包箱、EMC 的存儲,運維成本很高。在虛擬化方面,運維團隊使用的是 VMware vSphere 解決方案,它的管理和運維成本比較高。
如何解決這個問題呢?跟大多數的互聯網公司一樣,魅族逐步使用 X86 服務器來代替,提高業務的穩定性,節省了成本。
- 機房資源不足,擴容難,以及資源管理問題。因為業務發展比較快,相應的業務需求多且緊急,所以裝機和交付的速度完全跟不上業務的發展需要。
為了解決這個問題,運維團隊把主要業務分到多個機房部署,并且在各個機房部署冗余資源,除了滿足業務需求的同時還滿足一些計劃外的需求。另外,運維團隊在資源管理方面搭建了一個 CMDB,來統一管理線上的資產,使得資源管理效率獲得很大提升。
- 網絡不穩定,活動日或者發布日的流量突增。面對這個問題,解決辦法首先是在硬件上更換核心網絡設備,配置上有所提升,保證在流量較大的時候,設備的承載方面沒有問題。
另外,在帶寬上做冗余,這樣在網絡流量突增的情況下,業務也不會因此造成影響。同時,網絡架構也變成了 2.0 架構,即多機房,在網絡層面使用虛擬化,大二層架構。1.0 架構是單機房,網絡層面沒有做虛擬化,使用的是 HSRP。
- DB 服務器的 IO 問題導致的業務壓力。早期 DB 使用的是 SAS 磁盤,讀寫頻繁的時候,就會帶來一些 IO 問題。
針對這一問題,運維工程師對 ssd 磁盤或者 pciessd 進行測試,根據業務的特性為不同的業務配備 ssd 或者 pciessd 來滿足業務的 IO 需求。
批量操作和監控不完善,以及監控的覆蓋率問題。因為業務發展快,資源使用包括服務器的規模增多,給一些批量的操作帶來很大的人力成本。這時,工程師通過部署 Ansible 來做一些批量的操作。
而且監控會聯動 CMDB,定時對線上運營中的機器做一個巡檢,巡檢到未加監控的機器就會定時給相關人員發郵件,通知他們來解決監控覆蓋率低的問題。
- 安全性低,主要體現在早期所有的業務員都可以登錄線上所有機器,沒有權限限制或者管理。另外一個是來自外網的攻擊。
針對這個情況,工程師結合帳戶管理平臺 CMDB 對用戶做一些權限的劃分。比如某個賬號在 CMDB 上只能訪問哪幾個業務,只能登陸這幾個業務的機器。而且還有一個操作的審計,后面還可以跟蹤。
青銅時代
伴隨著上述問題的解決,魅族進入了青銅時代:兩地三中心。具體是機柜擴展到 150 個,服務器擴展到 4000 臺,業務線也發展到 200 多條。在人力方面,系統有 35 個業務人員來支撐。主要問題包括:
- 標準化率低,維護成本越來越高。針對這一點,運維團隊對標準化進行了梳理,包括軟件標準化、系統標準化和硬件標準化等。
- 在系統標準化方面,工程師開發了巡檢平臺,主要從系統常規、系統安全、系統內核等幾個維度定時進行巡檢,對出現問題的機器進行整改,確保線上標準化覆蓋率 100%。
- 業務架構單點的問題。因為業務發展比較迅速,架構單點的情況比較嚴重。解決方案是人工推動,先梳理現有的單點架構業務,然后去部署高可用架構。
- 此時,運維團隊在架構上做冗余,部署兩地三中心,當單個機房出現故障的時候,業務的可用性可以得到保障。這時架構進入 3.0 架構,使用三網分離,DCI 增加了專線,流量優先專線,專線出問題后再轉到 VPN。
- 供應商單一。這個供應商就是服務器供應商,還有網絡設備供應商,因為供應商單一會帶來成本和定制化方面的問題。
- 所以,運維團隊先建立了一套自己的運維設置標準,然后引入多個廠商來檢測它的兼容性、穩定性,以及業務系統也是聯系多個廠商,來建立標準。
- 與此同時,也會制定 SLA 標準、定制化標準,如后續有新的采購需求,都需要按照此標準執行。
- 配置管理準確性低。服務器從上線到下線,它的狀態改變在流程管理中沒有很好的解決方案,導致現有的梳理不準確。
- 針對這個情況,運維團隊首先建立了一整套的服務器生命周期管理流程,從服務器的引入、生產、運營、下線等來確保 CMDB 數據準確性,并且會結合一個工單平臺,該工單平臺會跟 CMDB 進行對接。
- 比如啟動開發的時候,工程師會發起 CMDB 的業務數,還有所在部門、產品線,最后當整個工單走完時,CMDB 會自動去更改,狀態也會由待運營狀態改變為運營中,整個過程全部是全自動的,不需要人工參與。
- 業務的突增造成機房規模的突增。因為魅族正式步入互聯網時代,業務發展迅猛,此時面對業務的資源需求,不能及時交付。
- 解決方案是由原來的 cobbler 升級至裝機平臺,轉化為無人職守安裝,裝機平臺和 CMDB 對接,并在各個機房保持一定的資源冗余率,以滿足業務計劃外的資源需求。后期,工程師使用容量管理對業務機器的資源使用情況進行審核。
- 故障多樣性。在供應商多的情況下,由于每個廠商的配件可能不一樣,故障后的日志收集方案不一樣,導致故障發生時需要定義各個廠商的日志收集方式、維修人員授權等等操作,造成太多的溝通成本,這在效率維度也是一個痛點。
- 針對這個問題,工程師統一了各廠商的日志收集方式,在業務高可用方面,部署高可用架構;當發生故障的時候,無需和業務進行溝通,直接關機進行硬件的維修操作。接著,工程師按月對故障進行分析,并建立知識庫,后續對出現的這一類故障可以快速進行處理。
鐵器時代
鐵器時代從 2016 年 1 月份到現在,魅族的業務仍呈增長趨勢。現在的規模,IDC 有多個,機柜大約 200 個,服務器數量超過了 6000 臺,業務線大約 200 個,平臺業務人員增長到 43 個。這個時代,問題還是有很多:
- 對于監控和告警的數據,一直沒有量化數據。當然也不可能達到可視化的一個效果,比如月度短信告警數量統計時,無法在平臺維度直接統計數據和展示數據,進而折算短信成本。
針對這個情況,運維團隊做了統一的告警平臺,并與基礎監控和業務監控結合。各個平臺告警數據統一從告警平臺進行收斂、匹配策略后,在發送給相應的用戶,這樣告警數據對比各個平臺單獨的告警數據就會減少很多,一方面減少了告警風暴,另一方面告警數據可以在平臺進行展示和統計,提高了工作效率。
- 機型套餐多,業務需求個性化。根據線上的業務特性,比如說高 IO 類、一線、在線存儲類、熱點類,工程師對線上的業務做一個分析,最后讓機型跟業務的特性做整合。
另外,工程師還會對 CMDB 占比較小的業務做整合,比如說 A 業務 100 臺,B 業務只有 2 臺,對于這種占比小的 B 業務,可以根據業務網做一個業務特性,劃定為某一個業務的特性,然后跟不同的機型進行整合。
- 業務成本高,ROI無法量化,比如某個業務投入的人力成本和開發成本遠遠大于它的產出成本這樣的情況。
針對這個問題,工程師的處理方式分為兩個維度:一是使用容量系統對資源進行使用率的考核,對于資源使用率較低的機器,推動業務進行業務混布,或者業務遷移至配置較低的機器上面。二是建立營收體系,搭建營收平臺,統計各個業務的運營成本和營收成本。
- 工作流程化。前面提到建立了服務器生命周期管理的一整套流程,但是運維團隊沒有一個很好的平臺管理進行任務進度查看,很多事情還是靠郵件溝通,這帶來的人力成本很高。
所以,建立了工單平臺,它完全遵循服務器生命周期的那一套流程,用于記錄各個工單的流程、處理情況、處理人、耗時等等,同時也方便后續的工單跟蹤情況。
而且工單平臺和 CMDB 對接,申請者提交需求的時候,會拉取 CMDB 業務樹和部門進行填寫,當工單完結的時候,會自動掛載業務以及修改服務器運營狀態,還有對此業務的運維人員可以進行自動填寫的功能,大大提高了工作效率。
- 資源利用率,就是使用容量平臺來監控各個產品線的資源使用情況,然后對資源使用率較低的業務進行混布或者遷移方案。
- 預案管理。運維團隊部署兩地三中心,在多個數據中心部署業務,當單個數據中心出現故障的時候,可以快速切換到別的 IDC 服務器,確保服務正常的運行。另外也會對專線進行定時切換演練,以測試專線切換后是否有問題發生。
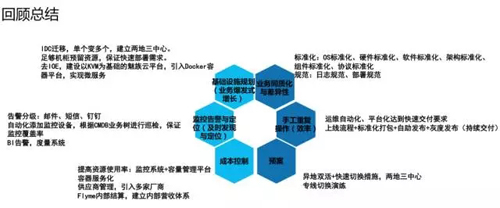
上面講述了從 2011 年到現在,整個歷程中出現的問題,運維團隊是如何解決的。還需要詳細說明兩點,一個是業務的增長從 5 臺到 6000 臺,速度很快,這很考驗基礎設施的建設。
另外一個是很考驗交付效率能力,網絡架構從 1.0 升級到 3.0,用裝機平臺解決工單系統,跟CMDB聯動,降低我們的操作頻率。
在成本控制方面,對于一個有海量互聯網業務的公司來說,微優化可以節省很多成本,運維團隊主要從三個方面進行成本控制:
- 資源使用率;
- 供應商方面;
- 內部營收。
魅族運維體系實踐
魅族的運維體系跟大部分的互聯網公司一樣,采用多級分層模式,所有業務和 DB 都部署了高可用架構,技術平臺跟業務平臺也有很多的系統,比如發布平臺、監控平臺等等。
在自動化過程中,運維團隊根據遇到的情況定義優先級,進行任務分解,先做最容易的,能提高效率的點,再做整合,通過各個子系統的整合,形成適合自己的自動化運維框架。下面挑選幾個比較主要的系統談一下:
監控系統
監控系統采用 server-proxy-client 架構,Client 端的 Agent 會定時主動上報數據至 proxy 中做臨時緩存,proxy 會定時將臨時緩存的數據上報給 server 端存儲在數據庫,進而將數據展示在 Zabbix 界面。
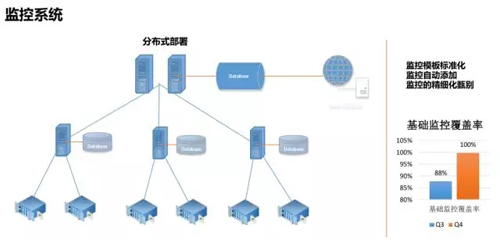
對監控模板標準化,針對不同的業務定義不同的模板,然后在 Zabbix 平臺定義告警匹配的動作,每個業務的運維/開發人員接收自己負責業務的告警。
監控覆蓋率方面會先發郵件給相應的人員去處理問題,以保證覆蓋率由早期比較低的一個百分比到達一個百分百的狀態,后續也會每天巡檢,讓覆蓋率一直維持在百分之百的狀態。
統一告警平臺
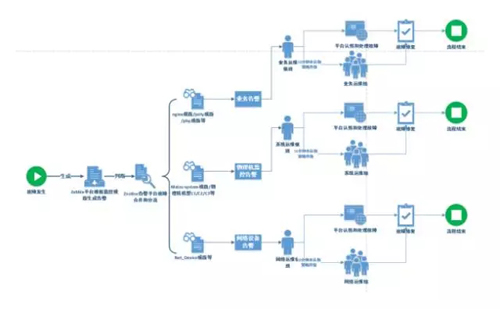
之前,所有的告警信息都從 Zabbix 平臺發出,服務器出現故障后,短信和郵件告警就會很多,如果不處理,則會一直告警,出現短信轟炸。針對此情況,運維團隊開發了告警平臺。
它的工作機制是:在統一告警平臺中,將服務的匹配策略和故障合并,當告警信息從 Zabbix 生成后,通過預先設定的腳本發送給告警平臺,在觸發策略,最后故障合并后,在觸發告警升級策略,即告警首先通知接收人,如 10 分鐘沒處理,則升級給團隊處理。
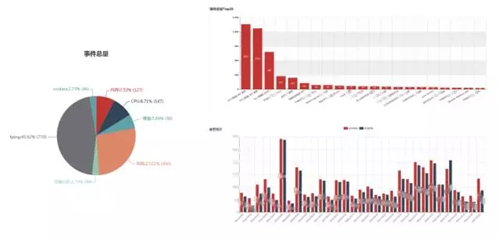
運維團隊通過統一告警平臺降低了運營成本。從上圖可以看到,左邊是應用級,應用級包括 CPU、內存等,右邊根據業務排序,哪個業務按月、按天,這塊后續需要優化。下面是一個月的尾天,哪天的告警比較多,可以根據這天的情況估計一下,保障后面的故障不會發生。
工單平臺
工單平臺包括服務器所有流程,和自定義功能,可以減少跟開發同事的溝通成本,開發只需要運維人員提需求,不同的需求使用不同的節點,直接查看工單的處理狀態。
比如說 OP 審核節點,以及開發審核節點,最后整個工單流程完成之后,所有的產品實現自動化。生命周期管理自動化,工單流程的可視化、可追蹤。
巡檢平臺
早期,運維團隊出現過內核參數設置未生效的問題,iptables 處于打開狀態,導致宿主機在大流量和高并發量的情況下網卡容易丟包,影響多個業務的穩定性。
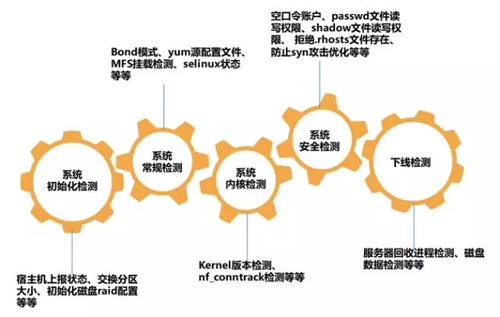
工程師意識到在 OS 層,做定制化和標準化,通過巡檢系統發現非標準機器,定時整改。系統巡檢主要包括系統初始化檢測、系統常規檢測、系統內核檢測、系統安全檢測和下線檢測。巡檢平臺可以按季、按月生成一個巡檢標準率,建立標準體系,提升工作效率。
更安全的堡壘機
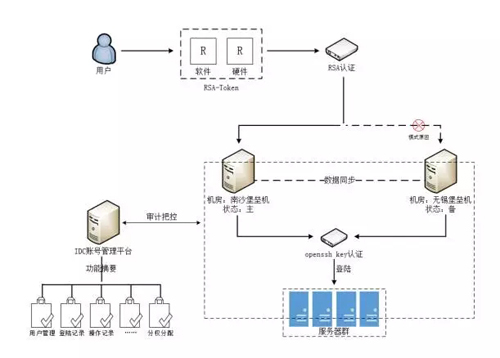
如上圖的堡壘機架構是在不同機房部署主備堡壘機,兩臺堡壘機之間的數據是同步的,用戶可以申請軟件或者硬件的 Token,然后通過 RSA 認證登錄到堡壘機。
此時 IDC 賬戶管理平臺會對登錄用戶進行審計把控,包括用戶管理、登錄記錄、分配權限、操作記錄等等,最后登錄到服務器上。這樣可以有效提高線上系統的安全。
流程管理
運維團隊建立了整套的服務器生命周期管理,從產品,服務器的引入,到生產、運營、下線,分為幾類:資源交付類、資源調動類還有一個生命周期末端流程。
結合工單平臺,它已經正式線上運行了,這一套流程建立之后,OP 跟開發之間的溝通成本,節約的時間已經大約是之前的 2 倍多了。
容量系統
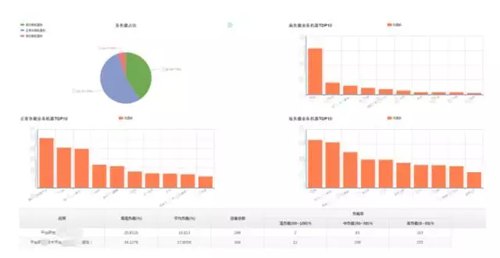
所有數據都來自于監控系統,比如 CPU、內存、IO 能力,工程師通過容量系統調取數據作一些分析,對使用率比較低的功能做一些整改,從上面可以看到閱讀或者按天的資源使用率情況。
另外,工程師也會做業務成本的考核,算是一個附加功能,主要是做了一個內部營收平臺,對內的各個業務通過一些核算來關注每一個業務的運營成本和產出。這樣每個部門的成本關注度也相應提升了五倍。
魅族運維未來展望
魅族希望內外兼修,打造精益化運營,通過運維自動化、監控自動化、安全管理、流程管理來提高服務質量。同時,工程師也會協同開發平臺,大數據平臺,為業務提供更優的服務。
本文來自魅族云平臺系統架構師梁鵬在聽云應用性能管理大講堂—《魅族基礎架構運維之路》分享總結,原文有刪減。
梁鵬
魅族云平臺系統架構師梁鵬
來自魅族云平臺,主要負責魅族系統運維、平臺建設和自動化的工作。


















