一張思維導圖縱觀MySQL數據安全體系
簡介
和團隊內部的同事一起溝通,討論了MySQL數據庫系統數據安全性問題,主要針對MySQL丟數據 、主從不一致的場景 ,還有業務層面使用不得當導致主備庫數據結構不一樣的情況,本文是基于以上的討論和總結做的思維導圖。
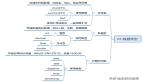
思維導圖
內容展示
OS
- BBU:數據庫服務器要配置BBU,BBU在電源供應出現問題的時候,為RAID控制器緩存提供電源。當電源斷電時,BBU電力可以使控制器內緩存中的數據可以保存一定時間(根據BBU的型號而決定)。用戶只需要在BBU電力耗盡之前恢復正常供電,緩存中的數據即可被完整的寫回RAID中,避免斷電導致數據丟失
- 防止OS異常斷電導致數據無法正常落盤
- 磁盤禁用cache,MySQL的 O_DIRECT 方式可以跳過pagecache寫數據
單機
(1)redo log
innodb_flush_log_at_timeout
< 5.6.6: 每隔一秒將redo log buffer中的數據刷新到磁盤
>= 5.6.6:每隔innodb_flush_log_at_timeout秒將數據刷新到磁盤中去
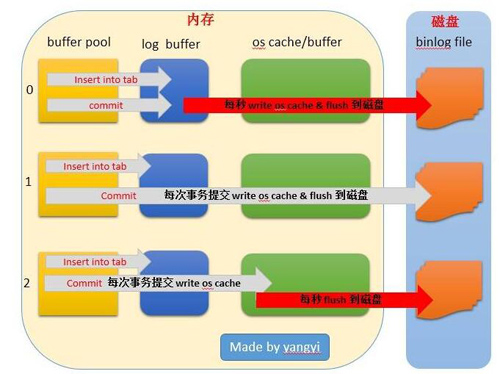
(2)binlog
sync_binlog =1
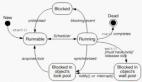
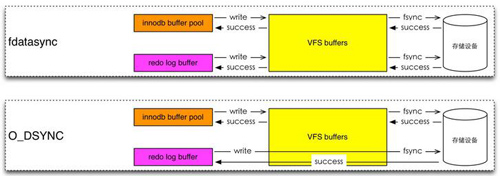
(3)innodb buffer data
不同的flush mathod刷數據的圖形展示。圖片來自hatemysql.com。
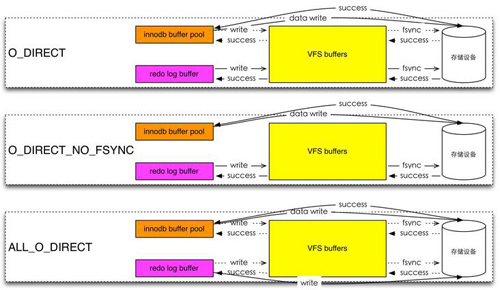
(4)InnoDB 落盤
MySQL數據落盤的路徑,圖片來自李春hatemysql.com。

主從不一致
- 主庫insert之后再回滾 ,主備庫自增主鍵不一致
- 使用replace into操作,導致主備庫自增主鍵不一致
- set session sql_log_bin=0
業務架構
常見的雙寫
“丟”數據的場景
(1)slave_skip_counter 不合理
- slave_skip_counter =1
- slave_skip_counter >1
(2)DB Crash,OS正常
- innodb_flush_log_at_trx_commit=0
事務提交時,不刷新緩存,系統刷新的頻率是1s,故會丟失1s的數據。
- innodb_flush_log_at_trx_commit=1
事務提交時,會刷新到磁盤,保證事務落盤,故不丟數據。
- innodb_flush_log_at_trx_commit=2
事務提交時,刷新到os cache,系統沒有crash,數據無丟失。
(3)DB正常,OS Crash
帶有 BBU
- innodb_flush_log_at_trx_commit=0
事務提交時,不刷新緩存,系統刷新的頻率是1s,故會丟失1s的數據。
- innodb_flush_log_at_trx_commit=1
事務提交時,會刷新到磁盤,保證事務落盤,故不丟數據。
- innodb_flush_log_at_trx_commit=2
事務提交時,刷新到os cache,系統沒有crash,數據無丟失。
(4)slave非實時寫redo和binlog丟失數據
在slave機器上會存在三個文件來保證事件的正確重放:relay log、 relay log info、 master info。
(5)異步模式
事務T1寫入binlog buffer;
dumper線程通知slave有新的事務T1;
binlog buffer進行checkpoint;
slave因為網絡不穩定,一直沒有收到t1;master掛掉,slave提升為新的master,t1丟失。
(6)semi sysnc
after_commit
比如主庫操作update t1 set val=1 where id=10將val從5修改為1 。
- 會話session1在主庫提交update t1 set val=1 where id=10 ;commit;
- 主庫根據二階段提交將數據持久化到innodb和提交日志binlog;
- 同步日志到slave ,并等待slave 返回ack信息,等待的實際時間以 rpl_semi_sync_master_timeout 為準,超過該設置時間則超時,主庫返回給客戶端成功寫入信息。
- 接收到來自slave的ack信息,返回成功給OK客戶端。
分析:
- 第四步之前,master還未收到slave的ack信息,此時由于事務已經提交,除了session1,其他會話是可以看到 val=1。
- 主庫服務器down或者主庫實例crash,此時發生HA切換。
- 主庫未接收到slave的ack信息,slave接收到日志并落盤,應用binlog更新。t1.val=1,此時業務切換到slave上能獲取到一致的數據。
- 如果在slave還未接收到binlog并且主庫掛了,因為主庫已經提交,此時主庫t1.val是1而從庫t1.val是5,主備不一致。
after_sync
比如主庫操作update t1 set val=1 where id=10將val從5修改為1。
- 會話session1在主庫提交 :update t1 set val=1 where id=10;commit;
- 主庫將事務寫入binlog。
- 將binlog同步給slave,不提交。
- 等待slave返回ack信息,等待的實際時間以rpl_semi_sync_master_timeout為準,如果超時master改為異步模式。
- 接收到來自slave的ack信息,主庫進行提交并且返回成功給OK客戶端。
分析:
- 如果在第3步等待slave ack的過程中,主庫發生crash(此時t1.val=5),HA 切換到slave,應用查詢slave 。如果slave接收到binlog并發送ack給master,則t1.val=1。
- 如果slave響應主庫,但是主庫crash ,此時因為主庫還沒提交t1.val=1, slave t1.val=5,但是主庫啟動恢復之后t1.val會變成5,主備還是一致的。
- 如果slave未接收到事務和響應主庫,此時t1.val=5,無論哪種狀態,對于所有客戶端數據庫都是一致,事務都沒有丟失。
知識點:兩階段提交
***階段是先prepare、再同步寫redo log,第二階段同步寫binlog、再commit,如果在寫入commit標志時崩潰,則恢復時,會重新對commit標志進行寫入。
HA切換
(6)主從
binlog_format
ROW(最安全)
MIXED(不推薦)
STATEMENT(不推薦)
sync_binlog
=0:由os系統的刷新機制來控制,刷新數據到磁盤的頻率
=1:每次commit刷新到磁盤
>1:每N次提交刷新到磁盤
innodb_support_xa
版本要打開,保證binlog提交的順序,否則亂序的binlog在恢復或者slave應用的時候會有問題,及以后廢棄,始終支持兩階段提交。
crash safe
crash-safe就是將relay-info.log的信息保存在InnoDB的事務表中,這時執行relay log中的事務和寫relay info在一個事務中,就能得到原子性保證。從而避免已執行的binlog位點和寫入relay log info的位點信息不一致的情況發生。
IO thread
master-info-repository=TABLE
sync_master_info=N:每N個event刷新一次表
SQL thread
relay-log-info-repository=TABLE
sync_relay_info=N:每N個event刷新一次表
relay-log-recovery
當slave從庫宕機后,假如relay-log損壞了,導致一部分中繼日志沒有處理,則自動放棄所有未執行的relay-log,并且重新從master上獲取日志,這樣就保證了relay-log的完整性。
relay_log_info_repository = TABLE
relay_log_recovery = 1
http://mysqlserverteam.com/relay-log-recovery-when-sql-threads-position-is-unavailable/
semi_sync
- after commit:master把每一個事務寫到二進制日志并保存到磁盤上,并且提交(commit)事務,再把事務發送給從庫,開始等待slave的應答。響應后master返回結果給客戶端,客戶端才可繼續。
- after sync:master把每一個事務寫到二進制日志并保存磁盤上,并且把事務發送給從庫,開始等待slave的應答。確認slave響應后,再提交(commit)事務到存儲引擎,并返回結果給客戶端,客戶端才可繼續。
GTID
相比位點復制,能減少不一致的概率