













偽共享和緩存行
在計算機系統中,內存是以緩存行為單位存儲的,一個緩存行存儲字節的數量為2的倍數,在不同的機器上,緩存行大小為32字節到256字節不等,通常來說為64字節。偽共享指的是在多個線程同時讀寫同一個緩存行的不同變量的時候,盡管這些變量之間沒有任何關系,但是在多個線程之間仍然需要同步,從而導致性能下降的情況。在對稱多處理器結構的系統中,偽共享是影響性能的主要因素之一,由于很難通過走查代碼的方式定位偽共享的問題,因此,大家把偽共享稱為“性能殺手”。
為了通過增加線程數來達到計算能力的水平擴展,我們必須確保多個線程不能同時對一個變量或者緩存行進行讀寫。我們可以通過代碼走查的方式,定位多個線程讀寫一個變量的情況,但是,要想知道多個線程讀寫同一個緩存行的情況,我們必須先了解系統內存的組織形式,如下圖所示。
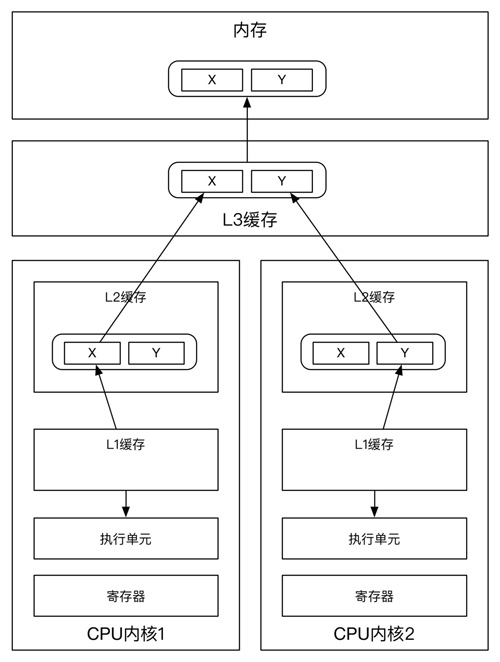
系統的緩存結構
從上圖看到,線程1在CPU核心1上讀寫變量X,同時線程2在CPU核心2上讀寫變量Y,不幸的是變量X和變量Y在同一個緩存行上,每一個線程為了對緩存行進行讀寫,都要競爭并獲得緩存行的讀寫權限,如果線程2在CPU核心2上獲得了對緩存行進行讀寫的權限,那么線程1必須刷新它的緩存后才能在核心1上獲得讀寫權限,這導致這個緩存行在不同的線程間多次通過L3緩存來交換最新的拷貝數據,這極大的影響了多核心CPU的性能。如果這些CPU核心在不同的插槽上,性能會變得更糟。
現在,我們學習JVM對象的內存模型。所有的Java對象都有8字節的對象頭,前四個字節用來保存對象的哈希碼和鎖的狀態,前3個字節用來存儲哈希碼,最后一個字節用來存儲鎖狀態,一旦對象上鎖,這4個字節都會被拿出對象外,并用指針進行鏈接。剩下4個字節用來存儲對象所屬類的引用。對于數組來講,還有一個保存數組大小的變量,為4字節。每一個對象的大小都會對齊到8字節的倍數,不夠8字節部分需要填充。為了保證效率,Java編譯器在編譯Java對象的時候,通過字段類型對Java對象的字段進行排序,如下表所示
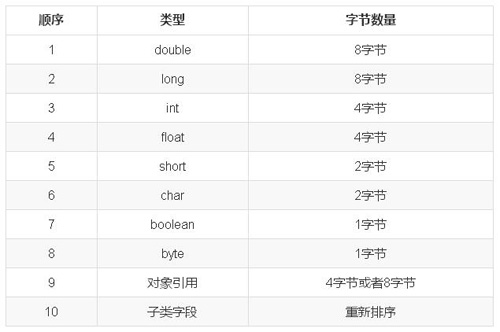
因此,我們可以在任何字段之間通過填充長整型的變量把熱點變量隔離在不同的緩存行中,通過減少偽同步,在多核心CPU中能夠極大的提高效率。
下面,我們通過一個測試用例來證明我們的理論分析的正確性,參考下面的代碼段。
- package com.robert.concurrency.cacheline;
- /**
- *
- * @author:李艷鵬
- * @since:Jun 11, 2017 1:01:29 AM
- * @version: 1.0
- */
- public final class FalseSharingDemo {
- // 測試用的線程數
- private final static int NUM_THREADS = 4;
- // 測試的次數
- private final static int NUM_TEST_TIMES = 10;
- // 無填充、無緩存行對齊的對象類
- static class PlainHotVariable {
- public volatile long value = 0L;
- }
- // 有填充、有緩存行對齊的對象類
- static final class AlignHotVariable extends PlainHotVariable {
- public long p1, p2, p3, p4, p5, p6;
- }
- static final class CompetitorThread extends Thread {
- private final static long ITERATIONS = 500L * 1000L * 1000L;
- private PlainHotVariable plainHotVariable;
- public CompetitorThread(final PlainHotVariable plainHotVariable) {
- this.plainHotVariable = plainHotVariable;
- }
- @Override
- public void run() {
- // 一個線程對一個變量進行大量的存取操作
- for (int i = 0; i < ITERATIONS; i++) {
- plainHotVariable.value = i;
- }
- }
- }
- public static long runOneTest(PlainHotVariable[] plainHotVariables) throws Exception {
- // 開啟多個線程進行測試
- CompetitorThread[] competitorThreads = new CompetitorThread[plainHotVariables.length];
- for (int i = 0; i < plainHotVariables.length; i++) {
- competitorThreads[i] = new CompetitorThread(plainHotVariables[i]);
- }
- final long start = System.nanoTime();
- for (Thread t : competitorThreads) {
- t.start();
- }
- for (Thread t : competitorThreads) {
- t.join();
- }
- // 統計每次測試使用的時間
- return System.nanoTime() - start;
- }
- public static boolean runOneCompare(int theadNum) throws Exception {
- PlainHotVariable[] plainHotVariables = new PlainHotVariable[theadNum];
- for (int i = 0; i < theadNum; i++) {
- plainHotVariables[i] = new PlainHotVariable();
- }
- // 進行無填充、無緩存行對齊的測試
- long t1 = runOneTest(plainHotVariables);
- AlignHotVariable[] alignHotVariable = new AlignHotVariable[theadNum];
- for (int i = 0; i < NUM_THREADS; i++) {
- alignHotVariable[i] = new AlignHotVariable();
- }
- // 進行有填充、有緩存行對齊的測試
- long t2 = runOneTest(alignHotVariable);
- System.out.println("Plain: " + t1);
- System.out.println("Align: " + t2);
- // 返回對比結果
- return t1 > t2;
- }
- public static void runOneSuit(int threadsNum, int testNum) throws Exception {
- int expectedCount = 0;
- for (int i = 0; i < testNum; i++) {
- if (runOneCompare(threadsNum))
- expectedCount++;
- }
- // 計算有填充、有緩存行對齊的測試場景下響應時間更短的情況的概率
- System.out.println("Radio (Plain < Align) : " + expectedCount * 100D / testNum + "%");
- }
- public static void main(String[] args) throws Exception {
- runOneSuit(NUM_THREADS, NUM_TEST_TIMES);
- }
- }
在上面的代碼示例中,我們做了10次測試,每次對不填充的變量和填充的變量進行大量讀寫所花費的時間對比來判斷偽同步對性能的影響。在每次對比中,我們首先創建了具有4個普通對象的數組,每個對象里包含一個長整形的變量,由于長整形占用8個字節,對象頭占用8個字節,每個對象占用16個字節,4個對象占用64個字節,因此,他們很有可能在同一個緩存行內。
- ...
- // 無填充、無緩存行對齊的對象類
- static class PlainHotVariable {
- public volatile long value = 0L;
- }
- ...
- PlainHotVariable[] plainHotVariables = new PlainHotVariable[theadNum];
- for (int i = 0; i < theadNum; i++) {
- plainHotVariables[i] = new PlainHotVariable();
- }
- ...
注意,這里value必須是volatile修飾的變量,這樣其他的線程才能看到它的變化。
接下來,我們創建了具有4個填充對象的數組,每個對象里包含一個長整形的變量,后面填充6個長整形的變量,由于長整形占用8個字節,對象頭占用8個字節,每個對象占用64個字節,4個對象占用4個64字節大小的空間,因此,他們每個對象正好與64字節對齊,會有效的消除偽競爭。
- ...
- // 有填充、有緩存行對齊的對象類
- static final class AlignHotVariable extends PlainHotVariable {
- public long p1, p2, p3, p4, p5, p6;
- }
- ...
- AlignHotVariable[] alignHotVariable = new AlignHotVariable[theadNum];
- for (int i = 0; i < NUM_THREADS; i++) {
- alignHotVariable[i] = new AlignHotVariable();
- }
- ...
對于上面創建的對象數組,我們開啟4個線程,每個線程對數組中的其中一個變量進行大量的存取操作,然后,對比測試結果如下。
1線程:
- Plain: 3880440094
- Align: 3603752245
- Plain: 3639901291
- Align: 3633625092
- Plain: 3623244143
- Align: 3840919263
- Plain: 3601311736
- Align: 3695416688
- Plain: 3837399466
- Align: 3629233967
- Plain: 3672411584
- Align: 3622377013
- Plain: 3678894140
- Align: 3614962801
- Plain: 3685449655
- Align: 3578069018
- Plain: 3650083667
- Align: 4108272016
- Plain: 3643323254
- Align: 3840311867
- Radio (Plain > Align) : 60.0%
2線程
- Plain: 17403262079
- Align: 3946343388
- Plain: 3868304700
- Align: 3650775431
- Plain: 12111598939
- Align: 4224862180
- Plain: 4805070043
- Align: 4130750299
- Plain: 15889926613
- Align: 3901238050
- Plain: 12059354004
- Align: 3771834390
- Plain: 16744207113
- Align: 4433367085
- Plain: 4090413088
- Align: 3834753740
- Plain: 11791092554
- Align: 3952127226
- Plain: 12125857773
- Align: 4140062817
- Radio (Plain > Align) : 100.0%
4線程:
- Plain: 12714212746
- Align: 7462938088
- Plain: 12865714317
- Align: 6962498317
- Plain: 18767257391
- Align: 7632201194
- Plain: 12730329600
- Align: 6955849781
- Plain: 12246997913
- Align: 7457147789
- Plain: 17341965313
- Align: 7333927073
- Plain: 19363865296
- Align: 7323193058
- Plain: 12201435415
- Align: 7279922233
- Plain: 12810166367
- Align: 7613635297
- Plain: 19235104612
- Align: 7398148996
- Radio (Plain > Align) : 100.0%
從上面的測試結果中可以看到,使用填充的數組進行測試,花費的時間普遍小于使用不填充的數組進行測試的情況,并且隨著線程數的增加,使用不填充的數組的場景性能隨之下降,可伸縮性也變得越來越弱,見下圖所示。
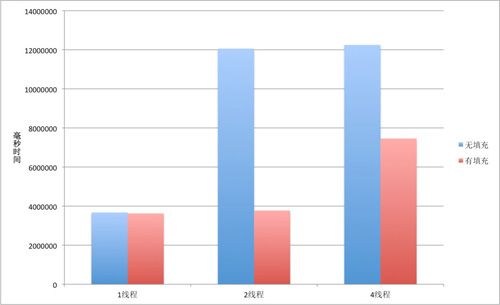
無填充和有填充對比圖標
盡管我們并不精確的知道系統如何分配我們的對象,但是,我們的測試結果驗證了我們的理論分析的正確性。
實際上,著名的無鎖隊列Disruptor通過解決偽競爭的問題來提高效率,它通過在RingBuffer的游標和BatchEventProcessor的序列變量后填充變量,使之與64字節大小的緩存行對齊來解決偽競爭的問題。
上面我們看到緩存行的機制在多線程環境下會產生偽同步,現在,我們學習另外一個由于緩存行影響性能的示例,代碼如下所示。
- package com.robert.concurrency.cacheline;
- /**
- *
- * @author:李艷鵬
- * @since:Jun 11, 2017 1:01:29 AM
- * @version: 1.0
- */
- public final class CacheLineDemo {
- // 緩存行的大小為64個字節,即為8個長整形
- private final static int CACHE_LINE_LONG_NUM = 8;
- // 用于測試的緩存行的數量
- private final static int LINE_NUM = 1024 * 1024;
- // 一次測試的次數
- private final static int NUM_TEST_TIMES = 10;
- // 構造能夠填充LINE_NUM個緩存行的數組
- private static final long[] values = new long[CACHE_LINE_LONG_NUM * LINE_NUM];
- public static long runOneTestWithAlign() {
- final long start = System.nanoTime();
- // 進行順序讀取測試,期待在存取每個緩存行的第一個長整形變量的時候系統自動緩存整個緩存行,本行的后續存取都會命中緩存
- for (int i = 0; i < CACHE_LINE_LONG_NUM * LINE_NUM; i++)
- values[i] = i;
- return System.nanoTime() - start;
- }
- public static long runOneTestWithoutAlign() {
- final long start = System.nanoTime();
- // 按照緩存行的步長進行跳躍讀取測試,期待每次讀取一行中的一個元素,每次讀取都不會命中緩存
- for (int i = 0; i < CACHE_LINE_LONG_NUM; i++)
- for (int j = 0; j < LINE_NUM; j++)
- values[j * CACHE_LINE_LONG_NUM + i] = i * j;
- return System.nanoTime() - start;
- }
- public static boolean runOneCompare() {
- long t1 = runOneTestWithAlign();
- long t2 = runOneTestWithoutAlign();
- System.out.println("Sequential: " + t1);
- System.out.println(" Leap: " + t2);
- return t1 < t2;
- }
- public static void runOneSuit(int testNum) throws Exception {
- int expectedCount = 0;
- for (int i = 0; i < testNum; i++) {
- if (runOneCompare())
- expectedCount++;
- }
- // 計算順序訪問數組的測試場景下,響應時間更短的情況的概率
- System.out.println("Radio (Sequential < Leap): " + expectedCount * 100D / testNum + "%");
- }
- public static void main(String[] args) throws Exception {
- runOneSuit(NUM_TEST_TIMES);
- }
- }
在上面的示例中,我們創建了1024 1024 8個長整形數組,首先,我們順序訪問每一個長整形,按照前面我們對緩存行的分析,每8個長整形占用一個緩存行,那么也就是我們存取8個長整形才需要去L3緩存交換一次數據,大大的提高了緩存的使用效率。然后,我們換了一種方式進行測試,每次跳躍性的訪問數組,一次以一行為步長跳躍,我們期待每次訪問一個元素操作系統需要從L3緩存取數據,結果如下所示:
- Sequential: 11092440
- Leap: 66234827
- Sequential: 9961470
- Leap: 62903705
- Sequential: 7785285
- Leap: 64447613
- Sequential: 7981995
- Leap: 73487063
- Sequential: 8779595
- Leap: 74127379
- Sequential: 10012716
- Leap: 67089382
- Sequential: 8437842
- Leap: 79442009
- Sequential: 13377366
- Leap: 80074056
- Sequential: 11428147
- Leap: 81245364
- Sequential: 9514993
- Leap: 69569712
- Radio (Sequential < Leap): 100.0%
我們從上面的結果中分析得到,順序訪問的速度每次都高于跳躍訪問的速度,驗證了我們前面對緩存行的理論分析。
這里我們看到,我們需要對JVM的實現機制以及操作系統內核有所了解,才能找到系統性能的瓶頸,最終提高系統的性能,進一步提高系統的用戶友好性。
點擊《偽共享和緩存行》閱讀原文。
【本文為51CTO專欄作者“李艷鵬”的原創稿件,轉載可通過作者簡書號(李艷鵬)或51CTO專欄獲取聯系】


















