













手把手教學:使用Elastic search和Kibana進行數據探索(Python語言)
探索性數據分析(EDA)幫助我們認識底層的數據基結構及其動力學,以此來最大限度發掘出數據的可能性。EDA是提取重要變量和檢測異常值的關鍵。盡管存在著很多種機器學習算法,但EDA仍被視為理解和推動業務的最關鍵算法之一。
其實有很多種方式都能夠執行實現EDA,例如Python的matplotlib、seaborn庫,R語言的ggplot2,而且網絡上有很多很好的資源,例如John W. Tukey的“探索性數據分析”, Roger D. Peng 的“用R進行探索性數據分析”等,不勝枚舉。
在本文中,我主要講解下如何使用Elastic search和Kibana實現EDA。
目錄:
1. Elastic search
2. Kibana
3. 創建數據表
- 數據索引
- 鏈接Kibana
- 可視化
4. 搜索欄
1. Elastic Search (ES)
Elastic Search是一個開放源碼,RESTful分布式和可擴展的搜索引擎。由于其簡單的設計和分布式特性,Elastic Search從大量級數據(PB)中進行簡單或復雜的查詢、提取結果都非常迅速。另外相較于傳統數據庫被模式、表所約束,Elastic Search工作起來也更加容易。
Elastic Search提供了一個具有HTTP Web界面和無模式JSON文檔的分布式、多租戶的全文搜索引擎。
ES安裝
安裝和初始化是相對簡單的,如下所示:
- 下載并解壓Elasticsearch包
- 改變目錄到Elasticsearch文件夾
- 運行bin/ Elasticsearch(或在Windows上運行bin \elasticsearch.bat)
Elasticsearch實例在默認配置的瀏覽器中進行本地運行http://localhost:9200。
2.Kibana
Kibana是一個基于Elasticsearch的開源數據挖掘和可視化工具,它可以幫助用戶更好地理解數據。它在Elasticsearch集群索引的內容之上提供可視化功能。
安裝
安裝和初始化的過程與Elasticsearch類似:
- 下載并解壓Kibana包
- 用編輯器打開config/ Kibana.yml,配置elasticsearch.url指向本地ElasticSearch實例所在位置
- 更改目錄到Kibana文件夾
- 運行bin/ Kibana(或在Windows上運行bin \ kibana.bat)
Kibana實例在默認配置的瀏覽器中進行本地運行http://localhost:5601.
將運行Kibana的終端保持打開狀態,可以保證實例不斷的運行。你也可以使用nohup模式在后臺運行實例。
3. 創建數據表
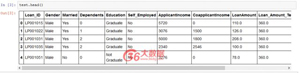
使用ES和Kibana創建儀表板主要有三個步驟。接下來我將會用貸款預測的實際問題的數據來示例如何創建一個儀表板。請注冊該問題,以便能夠下載數據。請檢查數據字典以獲得更多詳細信息。
注:在本文中,我將使用python讀取數據并將數據插入到Elasticsearch中,并通過Kibana進行可視化。
讀取數據
- import pandas as pd
- train_data_path = '../loan_prediction_data/train_u6lujuX_CVtuZ9i.csv'
- test_data_path = '../loan_prediction_data/test_Y3wMUE5_7gLdaTN.csv'
- train = pd.read_csv(train_data_path); print(train.shape)
- test = pd.read_csv(test_data_path); print(test.shape)
結果:
- (614, 13)
- (367, 12)

3.1 數據索引
Elasticsearch將數據索引到其內部數據格式,并將其存儲在類似于JSON對象的基本數據結構中。請找到下面的Python代碼,將數據插入到ES當中。
請如下所示安裝pyelasticsearch庫以便通過Python索引。
- pip install pyelasticsearch
- from time import time
- from pyelasticsearch import ElasticSearch
- CHUNKSIZE=100
- index_name_train = "loan_prediction_train"
- doc_type_train = "av-lp_train"
- index_name_test = "loan_prediction_test"
- doc_type_test = "av-lp_test"
- def index_data(data_path, chunksize, index_name, doc_type):
- f = open(data_path)
- csvfile = pd.read_csv(f, iterator=True, chunksize=chunksize)
- es = ElasticSearch('http://localhost:9200/')
- try :
- es.delete_index(index_name)
- except :
- pass
- es.create_index(index_name)
- for i,df in enumerate(csvfile):
- records=df.where(pd.notnull(df), None).T.to_dict()
- list_records=[records[it] for it in records]
- try :
- es.bulk_index(index_name, doc_type, list_records)
- except :
- print("error!, skiping chunk!")
- pass
- index_data(train_data_path, CHUNKSIZE, index_name_train, doc_type_train) # Indexing train data
- index_data(test_data_path, CHUNKSIZE, index_name_test, doc_type_test) # Indexing test data
- DELETE /loan_prediction_train [status:404 request:0.010s]
- DELETE /loan_prediction_test [status:404 request:0.009s]
3.2 鏈接Kibana
- 在瀏覽器上訪問 http://localhost:5601
- 去管理模塊中選取索引模式,點擊添加。
- 如果你的索引數據中包含時間戳,則選復選框。否則,取消選中該框。
- 將之前用于數據索引到ElasticSearch中的索引輸入。 (例如:loan_prediction_train)。
- 點擊新建。
對loan_prediction_test重復上述4個步驟。 現在kibana已經與訓練數據鏈接,并測試數據是否已經存在于elastic search中。
3.3可視化
- 單擊 可視化>創建可視化>選擇可視化類型>選擇索引(訓練或測試)>構建
例一
選擇垂直條形圖,并選擇繪制Loan_status分布的訓練索引。
將y軸作為計數,x軸代表貸款狀態
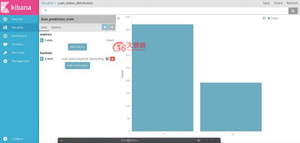
- 保存可視化
- 添加儀表板>選擇索引>添加只保存的可視化。
Voila!! Dashboard 生成啦!
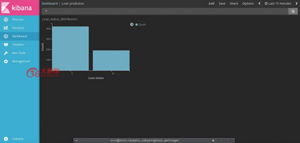
例二
- 單擊可視化>創建可視化>選擇可視化類型>選擇索引(訓練或測試)>構建
- 選擇垂直條形圖,并選擇訓練索引繪制已婚分布。
- 選擇y軸為計數,x軸為已婚
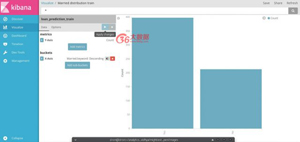
- 保存可視化。
- 重復上述步驟進行索引測試。
- 打開已創建的儀表板添加這些可視化
例三
類似的性別分布。這一次我們將使用餅圖。
- 單擊可視化>創建可視化>選擇可視化類型>選擇索引(訓練或測試)>構建
- 選擇餅圖并選擇列車索引繪制已婚分布。
- 按“已分隔”列選擇切片大小作為計數和分割片段
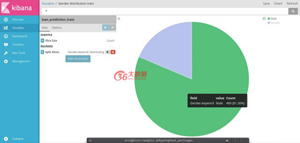
- 保存可視化。
- 重復上述步驟進行索引測試。
- 打開已創建的儀表板添加這些可視化
最后,創建所有可視化的儀表板將如下所示!
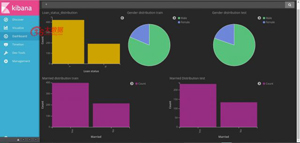
是不是很漂亮!
剩下將由你來探索更多的elasticsearch和Kibana了,并創建多種多樣的可視化效果。
4.搜索欄
搜索欄允許用戶通過字符串來搜索來數據,這便有助于我們理解數據中的更改,并在一個特定屬性中進行更改,這對于可視化來說是不容易的。
舉例
- 轉到發現>添加Loan_Status和Credit_History
- 使用搜索欄僅選擇Credit_History為0.(Credit_History:0)
- 現在可以查看Loan_Status列中的更改記錄。
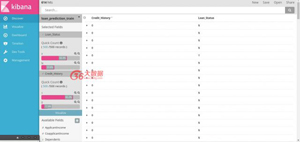
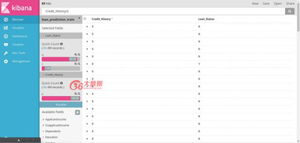
觀點:大多數信用記錄為0的客戶沒有收到貸款(貸款狀態為N = 92.1%)
以上為全文。
















