日均處理數億推薦請求,平均耗時30毫秒,58同城推薦系統是怎么做到的?
58 同城作為中國最大的分類信息網站,向用戶提供找房子、找工作、二手車和黃頁等多種生活信息。在這樣的場景下,推薦系統能夠幫助用戶發現對自己有價值的信息,提升用戶體驗,本文將介紹 58 同城智能推薦系統的技術演進和實踐。
58 同城智能推薦系統大約誕生于 2014 年(C++實現),該套系統先后經歷了招聘、房產、二手車、黃頁和二手物品等產品線的推薦業務迭代,但該系統耦合性高,難以適應推薦策略的快速迭代。
58 同城 APP 猜你喜歡推薦和推送項目在 2016 年快速迭代,產出了一套基于微服務架構的推薦系統(Java 實現),該系統穩定、高性能且耦合性低,支持推薦策略的快速迭代,大大提高了推薦業務的迭代效率。
此后,我們對舊的推薦系統進行了重構,將所有業務接入至新的推薦系統,最終成功打造了統一的 58 同城智能推薦系統。
下面我們將對 58 同城智能推薦系統展開進行介紹,首先會概覽整體架構,然后從算法、系統和數據三方面做詳細介紹。
推薦系統的整體架構
首先看一下 58 同城推薦系統整體架構,一共分數據層、策略層和應用層三層,基于 58 平臺產生的各類業務數據和用戶積累的豐富的行為數據,我們采用各類策略對數據進行挖掘分析,最終將結果應用于各類推薦場景。
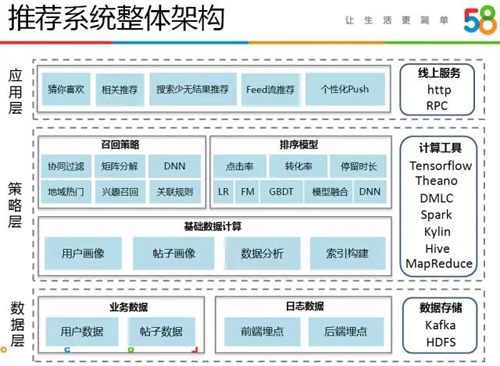
數據層
主要包括業務數據和用戶行為日志數據。業務數據主要包含用戶數據和帖子數據,用戶數據即 58 平臺上注冊用戶的基礎數據,這里包括 C 端用戶和企業用戶的信息,帖子數據即用戶在 58 平臺上發布的帖子的基礎屬性數據。
這里的帖子是指用戶發布的房源、車源、職位、黃頁等信息,為方便表達,后文將這些信息統稱為帖子。
用戶行為日志數據來源于在前端和后臺的埋點,例如用戶在 APP 上的篩選、點擊、收藏、打電話、微聊等各類操作日志。
這些數據都存在兩種存儲方式,一種是批量存儲在 HDFS 上以用作離線分析,一種是實時流向 Kafka 以用作實時計算。
策略層
基于離線和實時數據,首先會開展各類基礎數據計算,例如用戶畫像、帖子畫像和各類數據分析。
在這些基礎數據之上便是推薦系統中最重要的兩個環節:召回和排序。
召回環節包括多種召回源的計算,例如熱門召回、用戶興趣召回、關聯規則、協同過濾、矩陣分解和 DNN 等。
我們采用機器學習模型來做推薦排序,先后迭代了 LR、FM、GBDT、融合模型以及 DNN,基于這些基礎機器學習模型,我們開展了點擊率、轉化率和停留時長多指標的排序。
這一層的數據處理使用了多種計算工具,例如使用 MapReduce 和 Hive 做離線計算,使用 Kylin 做多維數據分析,使用 Spark、DMLC 做大規模分布式機器學習模型訓練,使用 theano 和 tensorflow 做深度模型訓練。
應用層
我們通過對外提供 rpc 和 http 接口來實現推薦業務的接入。58 同城的推薦應用大多是向用戶展示一個推薦結果列表,屬于 topN 推薦模式,這里介紹下 58 同城的幾個重要的推薦產品:
猜你喜歡:58 同城最重要的推薦產品,推薦場景包括 APP 首頁和不同品類的大類頁,目標是讓用戶打開 APP 或進入大類頁時可以快速找到他們想要的帖子信息,這主要根據用戶的個人偏好進行推薦。
詳情頁相關推薦:用戶進入帖子詳情頁,會向用戶推薦與當前帖子相關的帖子。該場景下用戶意圖較明顯,會采用以當前帖子信息為主、用戶偏好信息為輔的方式進行推薦。
搜索少無結果推薦:用戶會通過品類列表頁上的篩選項或搜索框進入品類列表頁獲取信息,若當前篩選項或搜索條件搜索出的結果較少或者沒有結果,便會觸發推薦邏輯進行信息推薦。
此時會結合當前搜索條件的擴展以及用戶偏好信息進行推薦。
個性化推送(Push):在用戶打開 APP 前,將用戶感興趣的信息推送給他們,促使用戶點擊,提高用戶活躍度。這里包含推送通知的生成和推送落地頁上帖子列表的生成兩個推薦邏輯。
值得一提的是推送是強制性的推薦,會對用戶形成騷擾,因此如何降低用戶騷擾并給用戶推薦真正感興趣的信息尤為重要。
Feed 流推薦:我們的推薦產品在某些推薦場景下是以 Feed 流的形式展現的,例如 APP 消息中心的今日推薦場景、推送落地頁場景。
用戶可以在這些頁面中不斷下拉刷新消費信息,類似時下火熱的各大資訊 Feed 流推薦。
推薦系統是一個復雜的工程,涉及算法策略、工程架構和效果數據評估三方面的技術,后文將分別從這三方面介紹 58 同城推薦系統。
推薦系統的算法
推薦涉及了前端頁面到后臺算法策略間的各個流程,我們將推薦流程抽象成如下圖所示的召回、排序、規則和展示四個主要環節:
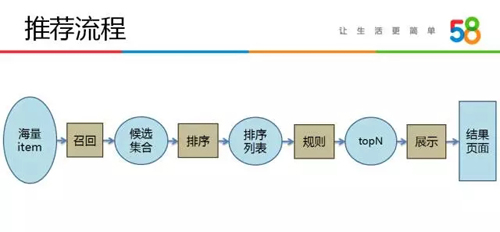
- 召回環節,使用各種算法邏輯從海量的帖子中篩選出用戶感興趣的帖子候選集合,一般集合大小是幾十到上百。
- 排序環節,對候選集合中的帖子進行打分排序,這里一般會使用機器學習排序模型,排序環節會生成一個排序列表。
- 規則環節,我們可能對排序列表采取一定的規則策略,最終生成一個包含 N 條結果的列表。
- 例如在規則環節,我們可能會采取不同的去重策略,如文本去重、圖片去重、混合去重等,可能會采取不同的列表打散策略,可能會迭代產品經理提出的各種規則邏輯。
- 由于推薦系統的最終評價是看統計效果,因此各種人為的規則都會影響最終結果,我們抽象出規則環節后便可以對任何邏輯做線上 ABTest,最終評價相關邏輯是否合理。
- 展示環節,生成 N 條推薦結果列表后,不同的前端展示方式也會影響最終的推薦效果。
例如不同的 UI 設計,采用大圖模式還是小圖模式,頁面上展示哪些字段都會影響用戶在推薦列表頁上的點擊,因此在推薦產品迭代過程中不同的展示樣式迭代也很重要。
在上述的四個環節中,召回和排序是推薦系統最重要的兩個環節。規則和展示樣式一般變化周期較長,而召回和排序有很大的挖掘空間,會被不斷的迭代,我們的推薦算法工作也主要是圍繞召回和排序進行。
下圖是我們推薦算法的整體框架,主要包括基礎數據的計算以及上層的召回策略和排序模型的迭代。
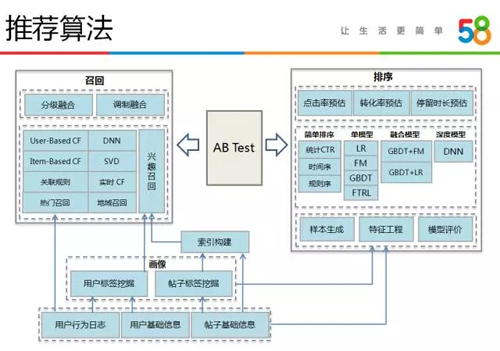
基礎數據計算主要包括用戶標簽和帖子標簽的挖掘,這部分工作由用戶畫像、搜索和推薦多個團隊共同完成,最終各團隊共享數據。
基于用戶注冊時填寫的基礎屬性信息和用戶行為日志,可以挖掘出用戶人口屬性和興趣偏好信息,如用戶的年齡、性別、學歷、收入等基礎屬性,用戶感興趣的地域商圈、二手房均價、廳室、裝修程度等偏好信息。
帖子標簽挖掘包括提取帖子的固定屬性、挖掘衍生屬性以及計算動態屬性。固定屬性直接從帖子數據庫提取即可,如分類、地域、標題、正文、圖片、房源價格、廳室、小區等。
我們還會基于貼子信息是否完備、價格是否合理、圖片質量好壞、發帖人質量等多個維度來計算帖子質量分。
基于用戶行為日志數據可以計算帖子的 PV、UV、點擊率、轉化率、停留時長等動態屬性。這些數據最終會在召回環節和排序環節使用,例如基于用戶標簽和帖子標簽可以進行興趣召回,將用戶標簽和帖子標簽作為特征迭代機器學習模型。
召回主要負責生成推薦的候選集,我們采用多種召回源融合的方式來完成該過程。我們先后迭代了如下各類召回策略:
- 熱門召回。基于曝光和點擊日志,我們會計算不同粒度的熱門數據。以二手車業務線為例,從粗粒度到細粒度的數據包括:城市下的熱門商圈、商圈下的熱門車系和品牌、特定車系和品牌下的熱門車源等。
每一個車源的熱度,我們通過最近一段時間內帖子的 PV、UV、CTR 等指標來衡量,這里的 CTR 會通過貝葉斯和 COEC 做平滑處理。熱門召回策略會在冷啟動時被大量采用。
- 地域召回。58 同城是向用戶提供本地生活服務類信息,用戶的每次訪問都會帶上地域信息,如選擇的城市、定位的地點等。我們主要結合地域信息和熱門數據做召回,如附近最新或最熱帖子召回、城市熱門帖子召回等。
- 興趣召回。基于帖子基礎屬性字段和帖子標簽信息,我們構建了一套帖子檢索系統,通過該系統能夠以標簽或屬性字段檢索出最新發布的帖子。在用戶畫像中,我們計算了每個用戶的興趣標簽。
因此基于用戶興趣標簽便能在檢索系統中檢索出一批帖子,這可以作為一種召回源。
此外,在帖子詳情頁相關推薦場景中,我們也可以利用當前帖子的屬性和標簽信息去檢索系統中檢索出相關帖子作為召回數據源。這兩種檢索召回就是我們常說的基于內容的推薦。
- 關聯規則。這里并非直接采用傳統 Apriori、FP-growth 關聯規則算法,而是參考關聯規則思想,將最近一段時間中每個用戶點擊所有物品當做一次事務,由此計算兩兩物品之間的支持度,并在支持度中融入時間衰減因子。
最終可以得到每個物品的 topK 個關聯性強的物品。這種召回方式類似協同過濾中的 item 相似度矩陣計算,我們主要將其應用在詳情頁相關推薦中。
- 協同過濾。我們使用 Spark 實現了基于 User 和基于 Item 的批量協同過濾計算,由于數據量大,批量計算會較消耗時間,我們又實現了基于 Item 的實時協同過濾算法。
通常情況下,我們會直接將用戶的推薦結果列表作為一種召回源,而在詳情頁相關推薦場景,我們還會使用協同過濾計算出的 Item 相似度矩陣,將帖子最相似的 topK 個帖子也作為一種召回源。
- 矩陣分解。我們引入了 SVD 算法,將用戶對帖子的點擊、收藏、分享、微聊和電話等行為操作看作用戶對帖子進行不同檔次的評分,從而構建評分矩陣數據集來做推薦。
- DNN召回。Google 在 YouTube 視頻推薦上使用了 DNN 來做召回,我們也正在進行相關嘗試,通過 DNN 來學習用戶向量和帖子向量,并計算用戶最相近的 topK 個帖子做為召回源。
上述不同的召回算法都產生出了一部分推薦候選數據,我們需要將不同的召回數據融合起來以提高候選集的多樣性和覆蓋率。
這里我們主要使用兩種召回融合策略:
- 分級融合。設置一個候選集目標數量值,然后按照效果好壞的次序選擇候選物品,直至滿足候選集大小。
假設召回算法效果好壞的順序是 A、B、C、D,則優先從 A 中取數據,不足候選集目標數量時則從 B 中取數據,依次類推。
我們的系統支持分級融合策略的配置化,不同召回算法的先后順序可以靈活配置。
這里的效果好壞順序是根據離線評價和線上評價來決定的,例如離線我們會比較不同召回算法的召回率和準確率,線上我們會比較最終點擊或轉化數據中不同召回算法的覆蓋率。
- 調制融合。按照不同的比例分別從不同召回算法中取數據,然后疊加產生最終總的候選集。
我們的系統也支持調制融合策略的配置化,選擇哪些召回算法、每種召回算法的選擇比例均可以靈活配置。這里的比例主要根據最終線上點擊或轉化數據中不同召回算法的覆蓋率來設置。
召回環節,新召回源的添加或者新融合策略的上線,例如開發了一種新召回算法、需要修改調制融合策略中的配比等,我們都會做線上 ABTest,最終通過比較不同策略的效果來指導我們的迭代。
值得一提的是,召回環節我們還會有一些過濾規則,例如過濾低質量帖子、在某些特定場景下對召回算法產生的結果加一些條件限制等。
排序環節,我們主要采用 Pointwise 方法,為每個帖子打分并進行排序,通過使用機器學習模型預估帖子的點擊率、轉化率和停留時長等多指標來做排序。
早期,我們主要優化點擊率,目前我們不僅關注點擊率外,還會注重轉化率的提高。在 58 同城的產品場景中,轉化主要指用戶在帖子詳情頁上的微聊、打電話操作。
排序離線流程主要包括樣本生成和選擇、特征抽取、模型訓練和評價:
- 首先對埋點日志中的曝光、點擊、轉化和停留時長等數據做抽取解析,如基于曝光序列號關聯各類操作、解析埋點參數(例如日志中記錄的實時特征)、解析上下文特征等,并同時打上 label,生成模型樣本。
- 然后對樣本進行過濾,例如過濾惡意用戶樣本、過濾無效曝光樣本等。然后對樣本做特征抽取,生成帶特征的樣本,我們主要從用戶、帖子、發帖人和上下文四個維度做特征工程。
- 之后,按照一定正負樣本比例做采樣,最終進行模型訓練和評估,離線評估指標主要參考 AUC,離線效果有提升后會進行 ABTest 上線,逐步迭代。
我們先后迭代上線了如下排序策略:
- 規則序。早期未上線機器學習模型時,對候選集中的帖子會直接使用刷新時間、統計 CTR 或者一些產品規則來做排序。
- 單機器學習模型。我們最早實踐的是 LR 模型,它是線性模型,簡單高效、可解釋性好,但對特征工程要求較高,需要我們自己做特征組合來增強模型的非線性表達能力,早期我們使用 LibLinear 來訓練模型,后來遷移到了 Spark 上。
之后我們引入了 XGBoost 樹模型,它非線性表達能力強、高效穩定,是目前開源社區里最火熱的模型之一,最初我們采用單機版本訓練,后期將 XGBoost 部署在我們的 yarn 集群上,使用分布式版本進行訓練。
同時,我們應用了 FM 模型,相比于 LR 模型它引進了特征組合,能夠解決大規模稀疏數據下的特征組合問題,我們主要使用分布式 FM (DiFacto,FM on Yarn)來進行模型訓練。
上述這些模型都是批量更新,通常是一天更新一次,為了快速捕捉用戶行為的變化,我們還引入 Online Learning 模型,主要嘗試應用 FTRL 方式去更新 LR 模型,在某些場景下獲得了穩定的效果提升。
- 融合模型。類似 Facebook、Kaggle 的做法,我們實踐了 GBDT+LR 和 GBDT+FM 的模型融合方案。
首先利用 XGBoost 對原始特征做處理生成高階特征,然后輸入到 LR 和 FM 模型中,目前我們的點擊率預估模型中效果最佳的是 GBDT+LR 融合模型,轉化率預估模型中效果最佳的是 GBDT+FM 融合模型。
此外,我們還會嘗試將某個單指標(如點擊率)下多個模型的預測結果進行融合(如相加或相乘等),也會將多個指標(點擊率、轉化率和停留時長)的模型進行融合(如相乘)以觀察效果。
- 深度模型。深度學習正逐漸被各大公司應用于推薦系統中,我們也正在進行嘗試。目前,我們已將 FNN(Factorisation machine supported neuralnetwork)模型應用在我們的推薦排序中。
相比單機器學習模型,FNN 有較穩定的效果提升,但比融合模型效果要稍差,目前我們正在進行深度模型的調優,并在嘗試引入Wide&Deep等其他深度模型。
基于上述基礎機器學習工具,目前我們主要會迭代點擊率、轉化率和停留時長預估模型,線上會 ABTest 上線單指標模型、多指標融合模型,以提高推薦效果。
推薦系統的后臺架構
對于推薦系統來說,一套支撐算法策略高效迭代的推薦后臺系統至關重要,我們基于微服務架構設計了推薦后臺系統,它擴展性好、性能高。
系統架構如下圖所示,系統分為數據層、邏輯層和接入層,數據層提供各類基礎數據的讀取,邏輯層實現召回和排序策略并支持不同策略的 ABTest,接入層對外提供了通用的訪問接口。
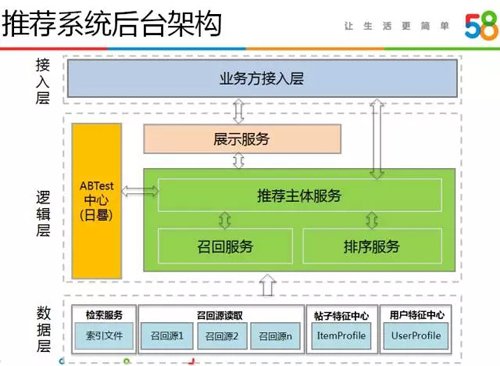
數據層提供推薦邏輯所需要的各類數據,這些數據存儲在 WRedis、文件、WTable 等多種設備上,我們將所有數據的讀取都封裝成 RPC 服務,屏蔽了底層的存儲細節。
這里包括檢索服務、召回源讀取服務、帖子特征中心和用戶特征中心:
- 檢索服務。我們搭建了一套搜索引擎用做召回檢索,支持基于各類搜索條件去檢索數據,例如可以檢索出價格在 200 萬至 300 萬之間的回龍觀兩室的房源、檢索出中關村附近的最新房源。
該服務主要應用于這幾類場景:在猜你喜歡推薦場景中基于用戶標簽去檢索帖子、在相關推薦場景中基于當前帖子屬性去檢索相關帖子、冷啟動時基于地域信息召回附近的帖子等。
- 召回源讀取服務。提供各類召回源數據的讀取,這些召回源數據通過離線或實時計算的到,包括熱門數據、協同過濾數據、關聯規則數據、矩陣分解結果等。該服務設計得較靈活,支持任意召回源的增加。
- 帖子特征中心。提供帖子所有屬性字段的讀取,在召回、排序和推薦主體邏輯中會使用到這些帖子屬性,一般情況我們會在召回環節讀取出所有帖子屬性,然后應用于排序和規則邏輯中。
召回得到的候選集大小一般是幾十到幾百,為了支持高性能的批量讀取,我們選擇使用 WRedis 集群存儲帖子屬性,并通過多線程并發讀取、緩存、JVM 調優等多項技術保證服務性能。
目前,該服務每天承接數億級請求,平均每次讀取 150 條數據,耗時保證在 2ms 之內。
- 用戶特征中心。UserProfile 數據包括用戶離線/實時興趣標簽、人口屬性等,該數據會在召回環節使用,例如使用用戶興趣標簽去檢索帖子作為一種召回源,也會在排序環節使用,例如將用戶標簽作為機器學習排序模型的特征。
邏輯層實現了詳細的推薦策略,包括推薦主體服務、召回服務、排序服務和 ABTest 實驗中心。
這些服務由不同的開發人員維護,保證了推薦策略的高效迭代,例如召回和排序是我們經常迭代的環節,由不同的算法人員來完成,召回服務和排序服務的分離降低了耦合,提高了迭代效率。
- 推薦主體服務。接收推薦請求,解析推薦場景參數,調用用戶特征中心獲取用戶信息,請求 ABTest 實驗中心獲取對應場景的 ABTest 實驗參數,如召回策略號、排序算法號、規則號和展示號。
然后將推薦場景參數、ABTest 實驗參數等發送至召回服務獲得候選集列表,之后再調用排序服務對候選集進行排序,最終對排序列表做相關規則處理,將結果列表封裝返回。
- 召回服務。接收場景參數和召回策略號參數,調用檢索服務和召回源讀取服務讀取各類召回數據,并進行分級融合或調制融合。
我們實現了召回策略的配置化,一個召回號對應一種召回策略,策略采用哪種融合方式、每種融合方式下包含哪些召回源、不同召回源的數量均通過配置來完成。
我們將召回配置進行 Web 化,算法或產品人員只需在 Web 頁面上配置即可生效策略。此外,召回層還包括一些過濾規則,例如過濾低質量信息、過濾用戶歷史瀏覽記錄、過濾產品指定的符合某些特定條件的數據等。
- 排序服務。接收場景參數、用戶信息、候選集列表和排序算法號等參數,調用機器學習排序模塊,對候選集列表做排序。
我們設計了一套通用的特征提取框架,保證機器學習離線模型訓練和線上排序共用相同的特征提取代碼,并靈活支持不同模型之間的特征共享。
在排序服務中上線一種模型成本很低,只需要提供模型文件和特征配置文件即可,后續我們將會對排序配置進行 Web化,簡化上線流程。
目前,我們的排序服務中運行了基于 LR、XGBoost、FM、XGBoost+LR、XGBoost+FM、DNN 的幾十個排序模型。
- ABTest 實驗中心。我們設計了一套靈活通用的 ABTest 實驗平臺(內部稱作“日晷”)來支持推薦系統的策略迭代,它包括流量控制、實時效果數據統計和可視化等功能,支持用戶在 Web 頁面上配置實驗和流量,并能展示實時效果數據。
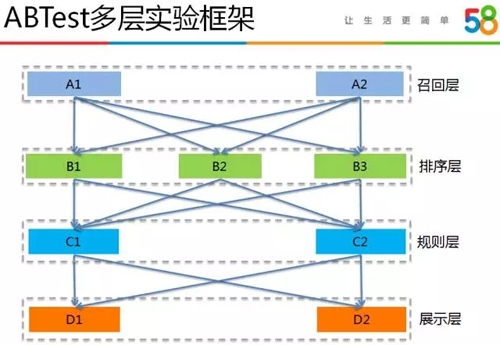
這套實驗平臺不僅可以應用于推薦系統,還可以用于任何其他需要做 ABTest 實驗的業務系統中,它支持多層 ABTest 實驗,能充分利用每份流量去完成業務迭代。
例如我們的推薦系統 ABTest 實驗就包含召回、排序、規則和展示四層,不同層之間實現了流量的重新打散,保證了不同層之間實驗的正交性。
當請求到達我們的推薦系統時,推薦主體服務便請求“日晷”以獲得該請求對應的召回號、排序號、規則號和展示號等實驗參數。
之后該請求便會被這些實驗參數打上標記,貫穿于后續的推薦流程,決定每層中將走哪部分邏輯,最終這些實驗參數會記錄到后臺和客戶端埋點日志中,用于最終的實驗效果統計。
接入層直接和客戶端交互,從客戶端接收請求并調用推薦主體服務獲得推薦帖子 ID 列表,然后查詢出帖子詳細屬性返回給客戶端做展示。
在大部分推薦場景中,接入層由業務方維護,可能是 PHP 或 Java 實現的 http 接口;也有少部分場景的接入層是我們自主維護,我們采用 58 自研的 MVC 框架 WF 實現了相關 http 接口。
我們采用 58 自研的 RPC 框架 SCF 實現了上述微服務架構的推薦系統,采用 58 自研的監控系統 WMonitor 實現了推薦系統的立體監控,整個技術棧是 Java。
我們采用多線程、異步、緩存、JVM 調優、降級、限流等措施保證了推薦系統的穩定和高可用,目前我們的推薦系統日均處理數億的推薦請求,平均耗時約 30 毫秒。
推薦系統的數據
這里的數據主要指推薦埋點數據和推薦效果數據:
- 埋點數據是推薦系統的基石,模型訓練和效果數據統計都基于埋點數據,需保證埋點數據的正確無誤。
- 效果數據是對推薦系統的評價,指引推薦策略的迭代,構建完備的效果數據體系至關重要。
我們的推薦埋點日志數據包括曝光日志、點擊日志、轉化日志和頁面停留時長日志等,這些日志數據都需要客戶端通過埋點來產生。
這里簡單解釋一下這些操作的含義:
- 客戶端請求一次推薦接口得到推薦結果列表叫做一次曝光。
- 用戶點擊推薦結果列表上的某條帖子進入帖子詳情頁叫做一次點擊。
- 用戶在帖子詳情頁上進行微聊、打電話、收藏等操作叫做轉化。
- 用戶在帖子詳情頁上的閱讀時間叫做頁面停留時長。這里的曝光、點擊和轉化是一個漏斗,操作數量是逐漸遞減的趨勢。
由于 58 同城上用戶對帖子的訪問可能來源于推薦、搜索和運營活動頁等場景,為了標識出推薦產生的點擊/轉化/停留時長,我們需要在埋點中加入推薦相關的參數。
我們將埋點參數設計成一個固定格式的字符串,它包含了曝光唯一序列號、推薦位標識、召回號、排序號、規則號、展示號、帖子 ID 列表、帖子 ID 等字段,這些字段將會作用于機器學習模型訓練樣本生成和推薦效果統計中。
埋點參數主要分為列表參數和單貼參數兩類:
- 推薦接口返回一個帖子列表,會對應返回一個列表參數,包含了曝光序列號、推薦位標識、召回號、排序號、規則號、展示號、帖子 ID 列表等字段。
- 返回的帖子列表中,每個帖子會對應返回一個單貼參數,包含曝光序列號、推薦位標識、召回號、排序號、規則號、展示號、帖子ID等字段。
客戶端得到推薦接口返回的埋點參數后,會將列表參數埋入到曝光日志中,將單貼參數埋入到點擊日志、轉化日志和停留時長日志當中,注意這里埋點時需要推薦列表頁向帖子詳情頁傳遞單貼參數,一般需要通過修改跳轉協議來實現。
最終埋點日志中有了這些參數后,我們便可基于曝光唯一序列號將曝光、點擊、轉化、時長數據 Join 起來,產生模型訓練樣本以及漏斗效果數據。
值得一提的是,我們采取透傳的方式在推薦后臺、接入層、客戶端間傳遞埋點參數字符串,所有埋點參數由推薦系統后臺生成,接入層和客戶端均不做任何處理。
埋點參數僅由我們推薦一方負責,這樣能夠避免多方改動埋點參數,從而減少埋點錯誤的可能性,由于是透傳處理,也便于今后埋點參數的擴展。
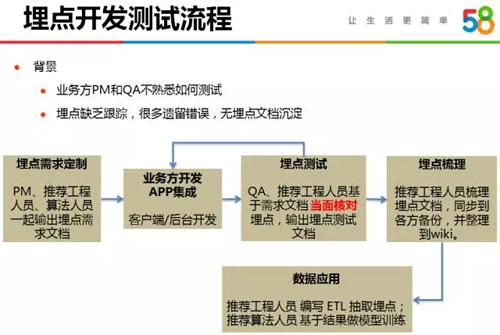
埋點數據是推薦系統的基石,不能有遺漏或者錯誤,這就要求我們嚴格把控開發測試流程,尤其是 APP 上的埋點,若發版之后發現有錯誤,便要等到下一次發版時解決。
客戶端開發和測試同事不清楚埋點參數的含義但熟練掌握測試環境部署及擁有 Android 和 IOS 測試機,而推薦后臺同事清楚埋點參數含義但對測試環境較生疏并缺乏測試機。
因此我們總結出了測試同事負責環境部署、推薦后臺同事負責檢驗埋點參數的測試流程,詳細流程如下圖所示。
此外,58 同城上的 APP 開發比較復雜,不同產品線各自開發自己的 APP 業務模塊,APP 平臺方開發主模塊,每次發版前都有一個集成階段,合并所有業務方提交的代碼,產生最終的 APP 包,集成階段很可能會發生業務方埋點未生效的情況。
因此,我們的埋點測試包括業務方內部測試和集成測試兩個階段,以保證埋點萬無一失。
我們的推薦效果數據是一個多維數據集,我們主要關注推薦位上的點擊、轉化、停留時長等指標。
日常工作中我們需要從不同業務線、不同客戶端、不同推薦位、不同推薦算法等多個維度去分析這些指標數據。
例如
我們會觀察房產和車在相同推薦位上的數據對比、猜你喜歡場景上不同召回或排序算法的數據對比、二手房詳情頁在 Android 和 iPhone 上數據對比等。
各種數據分析對比能幫助我們優化推薦策略,甚至能發現某些業務線功能邏輯上的隱藏 Bug。
在我們推薦項目攻堅階段,我們通過分析比較二手房詳情頁在 Android 和 iPhone 兩端的推薦效果,發現了 iPhone 上詳情頁瀏覽回退的 Bug,最終反饋給業務方并解決了該問題,該 Bug 的解決使得我們在二手房詳情頁推薦位上的推薦點擊量提高了數十萬。
我們從離線和實時兩方面構建推薦效果數據,數據統計流程如下圖所示:
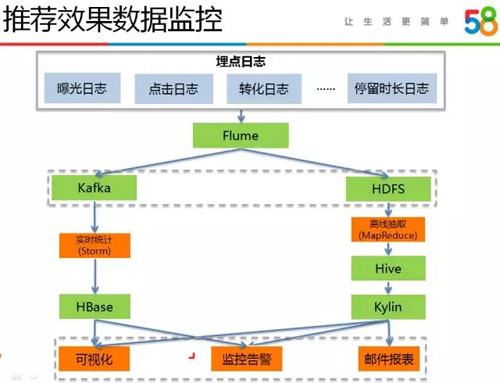
早期,離線效果數據統計是通過 MapReduce + Hive + MySQL 來實現的。
我們首先會編寫 MapReduce 程序對原始埋點日志進行抽取生成 Hive 表,然后會編寫大量的 Hive SQL 來統計各類指標數據,并將結果數據寫入 MySQL 數據表,最終做可視化展示和郵件報表。
由于我們比較的維度和指標多,Hive SQL 語句的編寫消耗了我們不少人力。在數據平臺部門部署了 Kylin 多維分析系統后,我們將效果數據統計工作遷移到了 Kylin 上。
我們只需要設計好 Hive 源數據表,并設置好維度和度量,Kylin 便能根據維度和度量來自動預計算結果數據,這省去了我們編寫 Hive SQL的工作,大大提高了效率。
實時效果數據,我們采用 Storm + HBase 來計算,實時效果數據主要用于異常埋點監控、新上線推薦算法效果快速反饋、模型異常監控等。
我們實現了一個包含較少維度的多維數據統計,今后我們將嘗試引入 Druid 等實時多維分析系統來完善推薦實時效果數據的建設。
總結
本文介紹了 58 同城智能推薦系統在算法、工程和數據三方面的技術演進。我們在最近一年加快了推薦業務的迭代速度,接入了房產、車等業務線在 APP、PC、M 三端共計近百個推薦位。
我們的推薦點擊占比指標(推薦位上產生的點擊量在總體點擊量中的占比)相比一年之前提高了 2~3 倍,達到了 20%~30%,每天能夠產生數千萬的推薦點擊量,為業務線帶來了流量提升。
任何推薦系統的發展必會經歷推薦位擴充和推薦算法深入優化兩個階段,流量指標可以通過擴充推薦位來快速提高,當推薦位穩定之后,就需要依賴更加深入的算法優化來繼續提高指標,而此時的效果提升也會相對緩慢。
目前,我們的流量指標已相對穩定,我們會更進一層去關注轉化指標,提高用戶進入帖子之后與發帖人進行微聊或電話溝通的可能性,幫助用戶找到真正有用的信息。