打臉淘寶,顛覆電商!這家時尚公司用算法引領新零售
原創【51CTO.com原創稿件】我分享的主題是數據驅動的決策輔助跟產品智能化的兩大部分內容,主要涉及我在數據科學中探索的心得體會和數據驅動的創業公司 Stitch Fix 的商業模式、業務流程、參考特征及推薦算法。
數據科學中探索的心得和體會
數據科學可從被 Google 收購的大數據競賽平臺 Kaggle 說起,Kaggle 是規模很大的數據科學家社區,創立于 2010 年,專注于數據科學、機器學習競賽的舉辦。
在 C 端,它很快吸引了大量數據科學家、機器學習開發者的參與。在 B 端,Kaggle 的模式也對接了大批優秀企業,為現實中的各類商業難題探尋算法和解決方案。
而它基于社區提供的招聘服務以及名為 Kaggle Kernels 的代碼分享工具也是社區運營的關鍵競爭力。
大家經常會說 Kaggle 是玩數據的平臺,ML 的開發者們展示功力、揚名立萬的江湖。如果是學習數據科學剛入行,想要找工作,可先在 Kaggle 上參加幾次競賽。
如下圖,是 Kaggle 的兩個習題:
- 回歸分析預測房價。
- 分類問題。
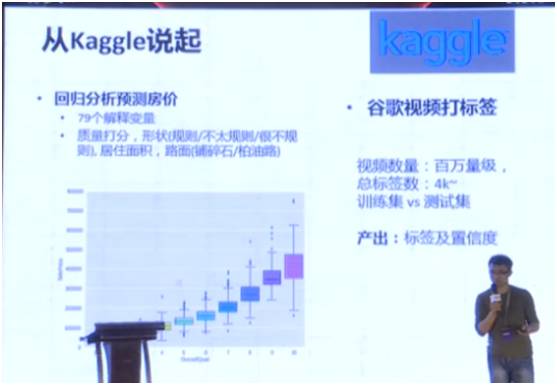
回歸分析預測房價。這是預測美國中西部一個只有十萬人左右的大學城。數據給出 79 個解釋變量,如質量打分、形狀(規則/不太規則/很不規則)、居住面積、路面(鋪碎石/柏油路)等,通過這些分析解釋變量,就可以預測房價。
如圖,Y 軸是銷售價格,X 軸是從 1-10 的質量打分,可以看出,當質量打分增加,售價也同時以遞增的速度增加。
分類問題。這個是對谷歌的視頻打標簽,使用 Youtube-8M 作為訓練數據,視頻是百萬量級,每個視頻對應 3-5 標簽,總共標簽數是 4000 左右。
從給定的訓練集中抽象出一些模型來,移動到測試集。問題產出是針對每一個視頻,可以預測一列標簽,可以根據置信度對標簽進行排序。
在 Kaggle 數據競賽中,數據都是預處理好的,基本變成行和列的表格狀數據。所以可以省掉很多原始數據預處理的過程。
如下圖,是基本的數據科學流程:
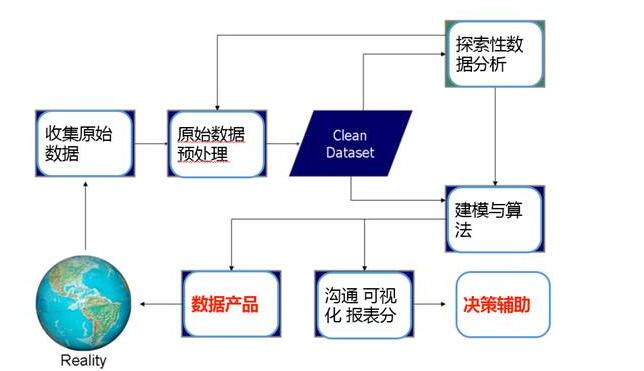
開始要先搜集原始數據(CRM、歷史交易等),還有網站分析或對用戶 APP 行為進行埋點,根據這些埋點追蹤用戶的行為。
之后,對原始數據進行預處理,也叫數據清洗,因為原始數據會有很多冗余、重復信息、變量缺失以及錯誤。基于清洗過的數據集,可以做一些探索性分析和機器學習。
數據科學的用途與數據產品
在數據科學的探索與分析方面,尿片和啤酒是很經典的案例。很多分析師會對商品信息進行歸類以及監督商品的相關度。
一般情況,大多數的商品相關度都很低,約在 0.1 左右,啤酒跟尿片的相關度是 0.3 左右。針對這個奇怪的現象,分析師們做了分析,發現很多父親晚上去超市給嬰兒買尿片的同時也會買啤酒來自己喝。
這樣一來,超市排放商品時可以把相關度比較高的商品放在一起,方便顧客挑選。所以對數據科學來講,通過數據分析、建模可以得到一些可以讓人信服的信息,便于做決策輔助。
另外就是生成分析型和智能化數據產品:
- 分析類數據產品。如現在了解當前北京實時交通狀況,可以找一些網上數據源,針對這些數據源做一些數據可視化和交互式分析。這樣數據產品可以呈現數據和定時更新數據內容,這就是一個分析型數據產品。
- 智能化數據產品。如基于機器學習實現的搜索引擎,廣告推薦系統等可定義為智能化數據產品。
數據科學家分類
數據科學家可劃分為 Analytics 和 Machine Learning 兩類,但是也有很多人兼顧兩個角色,相互轉換。
Analytics 更多時候是問題導向,如購物平臺上用戶在工作時間和下班后消費習慣的差異。最初可以針對總體綜合信息進行分析,然后在結果的基礎上做更細化的分析。可把用戶按照城市、地理位置、用戶使用的客戶端來分類細化。
這里整個過程是交互式的,就是不斷提出新問題,通過分析解決問題,然后再提出新的問題,最終目的是做決策輔助。
Machine Learning 主要是指標驅動,如提高廣告平臺上用戶的轉化率。轉化率就是從用戶點擊廣告到生成轉化或用戶訪問網站和下載 APP。
通過應用新模型或對現有系統當前參數進行改良來提升指標,最終目的是生成智能化的產品,當然中間還要考慮規模化和自動化。
Stitch Fix 的商業和業務模式
Stitch Fix 的商業模式
Stitch Fix 的商業模式和 Netflix 早期的商業模式很相似,在約 2004、2005 年的時候,Netflix 的商業模式主要是用戶可以在網上建一個自己想看的電影隊列,建成這樣一個隊列以后,Netflix會把電影寄到用戶的家里。
Stitch Fix 采用直郵的模式,只不過它是電商+直郵+推薦。現在,Stitch Fix 是一個在線個性化服裝推薦的公司。用戶注冊后,系統會推薦一些衣服寄到家里,用戶可以根據自己的興趣偏好決定要不要購買這些衣服。
Stitch Fix 主要解決用戶的以下購物痛點:
- 在我們生活中大部分人都非常忙碌,沒有時間上街購物。
- 有些用戶可能想發掘新的穿著偏好或是一些穿搭的體會。
- 很多追隨時尚潮流的人,想試用一下不同的場景等。
Stitch Fix 的業務模式
如下圖,從用戶方面看 Stitch Fix 的業務流程:
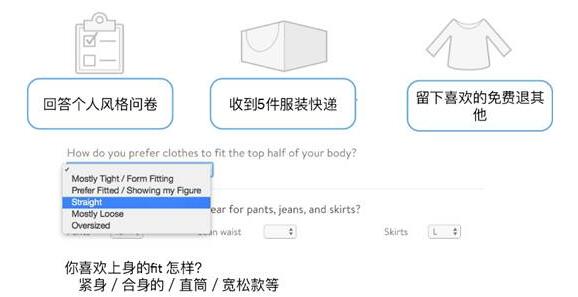
從用戶的角度看,用戶需要填寫個人風格問卷。問卷涉及購買衣服時會考慮到的常規問題,如顏色、價格、尺寸等等。
Stitch Fix 會搜集用戶個人風格問卷,結合算法和造型師的建議進行推薦。之后,用戶會收到五件不同的衣服,可在方便的地方試穿及與其他衣服進行搭配,喜歡留下來,不喜歡退回。
Stitch Fix 在做推薦衣服或人和貨匹配時,采用的是人機協同方式,不是純粹靠機器算法,也不是純粹靠人工,優勢互補實現 1 +1 > 2 的效果。
如下圖,是人機協同推薦衣服:

通過算法:
- 可對大量庫存 SUK 篩選和排序,這點人工是比較難實現的,當庫存量到峰值時會高達幾十萬甚至上百萬,從中進行人為篩選很耗時。
- 可基于試穿模式從大規模數據中找到每個人適合的 Pattern。
- 可發現某一類顏色衣服可能在某一個年齡段用戶銷售的特別好。
- 可對系統進行降噪操作,因為不同的造型師挑選會有差異。
如下圖,是人和算法協同工作:

構建人和算法協同系統,讓兩者優勢互補,真正實現1+1>2。人可以處理系統中非結構化數據,如文本數據、照片等。
也可以和用戶進行感情溝通,如造型師和用戶之間,多做情感溝通,大家會更加信任。還可以有更多的創造性,這樣算法就可免于被邊緣的情況。
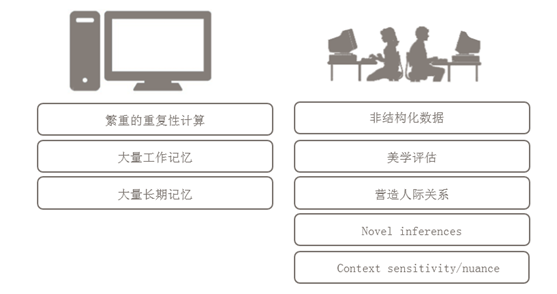
如上圖,左邊是計算機,右邊是人,計算機可處理比較繁重的重復性計算,另外計算機的短期記憶與長期記憶都是人所不能媲美的。
人能很好處理非數據化結構、對照片進行美化及建立更好的人機關系。還可以處理敏感度,例如,這樣一句話:把話筒放在地上,上面還有一本書。其中“上面”大家都知道是地上,但是這樣的場景讓機器學習的話是很難的。
Stitch Fix 的數據團隊概況與職責
如下圖,是 Stitch Fix 的數據團隊概況:

Stitch Fix 團隊約 80 人左右,主要分為客戶、推薦、庫存和數據平臺四個小團隊。數據平臺團隊的大數據架構和自動化分析流程,支撐其他三個團隊,這三個團隊和事業部一一對應。
客戶團隊主要是做精準營銷、需求預測、用戶畫像、客服分析。需求預測方面主要考慮用戶穩定增長,需求的季節性以及訂閱式用戶。
推薦團隊主要做人貨匹配、用戶造型師匹配、Human Computation 和造型師行為分析。
當用戶發出請求,會把造型師匹配給用戶,Human Computation主要是在虛擬環境下,研究造型師的行為,如一些歷史購買或退回的數據,基于這些數據抽樣,構造虛擬環境提供給造型師挑選衣服。
在已知購買和退回的情況下,控制展示造型師的信息。同時研究不同展示的情況下對造型師的成功率產生的影響。造型師行為分析則通過日志,對造型師的實際揀選行為進行分析。
庫存團隊主要做庫存預測、基于算法清倉和打標簽。
庫存隨時性很大,有倉庫庫存商品,還有從庫存寄到用戶家,在用戶家里停留,以及用戶不買的產品退回來的商品,所以要對庫存進行預測。還有對商品打標簽,有了標簽數據就可以做更好的匹配。
Stitch Fix的智能化物流
智能化物流—倉庫分配
Stitch Fix 采用的是單一倉庫發貨,單一包裹的方式。
如下圖,是選倉發貨:
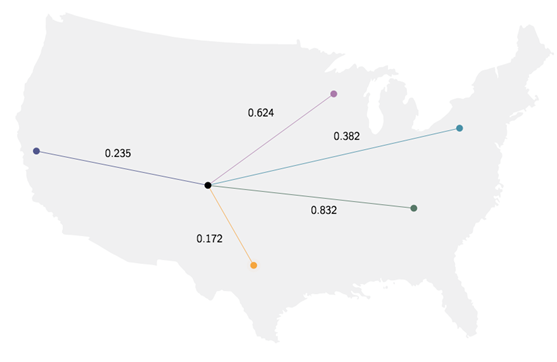
Stitch Fix 有五個倉庫,當用戶發來請求,首先進行倉庫的選擇。在選倉的同時考慮運費、投遞時間、庫存匹配等。倉庫不斷有商品出售,因此庫存會不斷消耗,不同庫存和用戶維度在實時變化。
智能化物流—造型師匹配
如下圖,是用戶造型師匹配表:
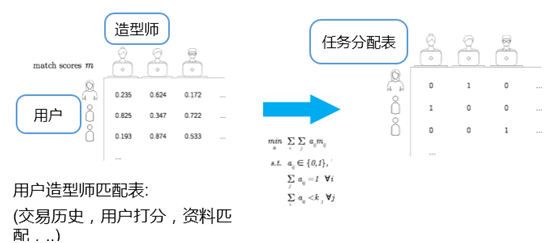
基于交易歷史、用戶對造型師打分和兩者資料的匹配情況。它會考慮到用戶跟造型師的屬性,如用戶是媽媽,會盡可能推薦一位也是媽媽的造型師。
智能化物流—人貨匹配
如下圖,是基于用戶和過去產品交易的特征建模:
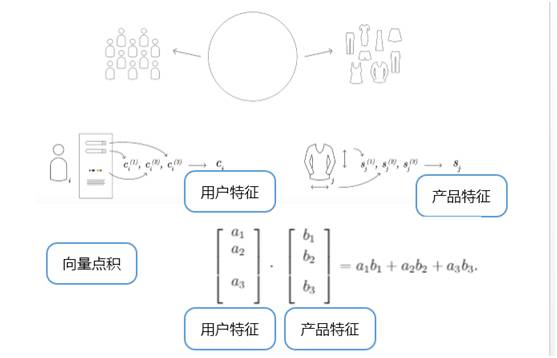
人貨匹配可以理解為比較傳統的機器學習算法,一種方法是協同過濾。協同過濾不用用戶特征和產品特征,只需用戶和過去產品交易的特征。
另一種方法是基于用戶特征和產品特征建模,用戶特征部分 Stitch Fix 有用戶問卷;產品特征部分,通過邏輯回歸,支持向量機,深度神經網絡學習得到。
如下圖,是用戶問卷特征:

圖中可以看到,對一個用戶會搜集他的數據,包括年齡、位置、職業,還有用戶的身材尺寸,顏色偏好等等。
Stitch Fix 還設計了一個樣式彩虹概念,把每個用戶樣式、偏好放在七維空間,七維包括經典、浪漫、波希米亞風、前衛、閃亮、休閑和制服式等。
除此之外可以根據交易歷史得到隱式尺寸,如用戶尺寸是從小到大,在不同范圍里會通過模型預測一些隱式尺寸來把用戶放到同一個范圍內。
如下圖,是產品特征:
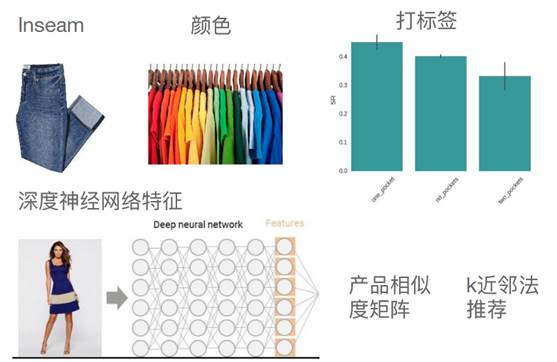
產品特征是通過深度神經網絡學習得到的,通過分析圖片,對每一個產品的圖片放到深度神經網絡中,生產一些進程,把每一件產品進程可計算產品相似度矩陣,這樣就可以用鄰近法進行推薦。
Stitch Fix 的推薦算法
在算法方面,Stitch Fix 主要是在開源庫的基礎上自研,這樣的模式比較像臉書。
如下圖,Stitch Fix 主算法 Mixed-effect logistic regression 混合效應邏輯回歸:
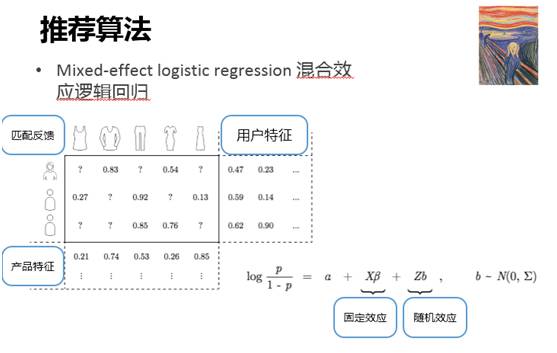
在矩陣中,每一行代表一個用戶,每一列代表一個產品。還有用戶特征、產品特征以及一些匹配反饋。之后通過建模預測這些數據,這個模型就是帶有混合效應的邏輯回歸。
推薦算法的挑戰
對于推薦算法而言,最需要考慮的是以什么指標排序?比如用交易數據、購買率?
Naïve 的方案是忽略造型師選擇,對交易數據建模。
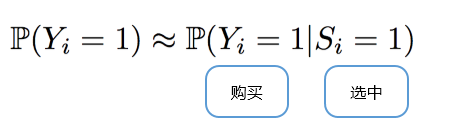
交易數據就是每一個用戶,每次郵寄的物件產品,哪些被購買、哪些被退回。這樣做的好處是用傳統機器學習就可以解決問題,交易數據的數據量不是很大。
但是,我們如果真的用這樣的方式,就會遇到很多問題。如刪除數據:

當用戶有特殊請求時,如有用戶不喜歡無袖,造型師就不會推薦,這部分數據在交易數據中就體現不出來,對于這樣的用戶就沒辦法估計這些產品在這些用戶推薦的成功率。
購買率不一定是好的排序指標
如下兩圖,是兩件衣服購買率的比較:
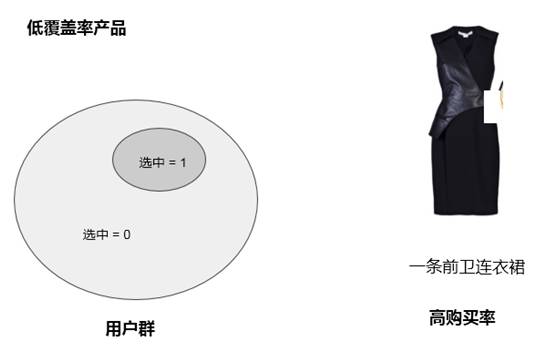
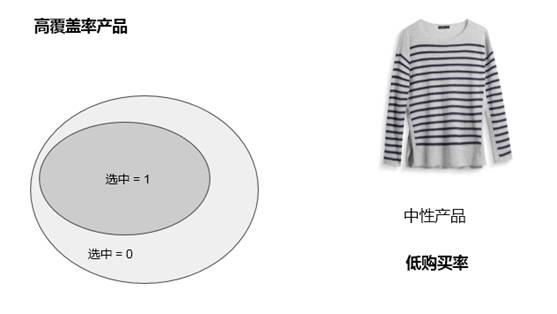
圖中可以看到第一件是覆蓋率比較低的,大圈是所有用戶群,在所有用戶群中只有很小一部分用戶挑選了這個產品,因為這個產品是比較前衛的,雖受眾較小,但知道應該選給誰,購買率很高。
第二件比較中性、百搭,給誰都可以,但是造型師不太清楚哪些是購買客戶。所以選中用戶圈覆蓋很大,但高覆蓋率下是低購買率。
如下圖,如果用購買率做指標需要把第一件排前:
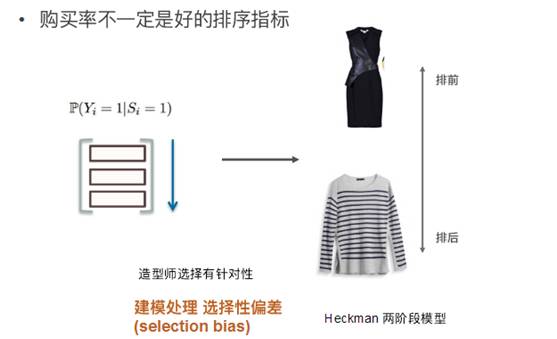
這樣做排序還需要注意一個很重要的因素就是造型師選擇過程中會有選擇性偏差,解決這個偏差可以采用 Heckman 兩階段模型。
總結
本文主分享了數據科學的一些心得體會以及 Stitch Fix 的一些關鍵技術。如果讀者對數據科學感興趣,個人建議有三個詞:興趣、實戰、分享。
- 興趣:高山仰止,雖不能至,然心向往之。
- 實戰:千里之行始于足下。
- 分享:獨樂樂不如眾樂樂。
以上內容根據王建強老師在 WOTA2017 “大數據應用創新”專場的演講內容整理。
前Twitter美國總部技術主管、中科大管理科學學士,2008 年獲 Lowa State University統計學博士。曾任科羅拉多州立大學(Colorado State University)統計系客座教授,美國國家統計院(National Institute of Statistical Sciences)和美國農業部聯合培養的博士后,惠普研究院(Hewlett-Packard Labs)高級科學家,推特廣告組數據科學家。他有多年數據分析及建模經驗,涉及領域有需求預測,供應鏈管理,廣告點擊率預測,廣告排序,推薦算法,統計預測模型。對數據科學教育,互聯網廣告和新興的零售業模式有興趣。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】