基于 RxJs 的前端數據層實踐
近來前端社區有越來越多的人開始關注前端數據層的設計。DaoCloud 也遇到了這方面的問題。我們調研了很多種解決方案,最終采用 RxJs 來設計一套數據層。這一想法并非我們的首創,社區里已有很多前輩、大牛分享過關于用 RxJs 設計數據層的構想和實踐。站在巨人的肩膀上,才能走得更遠。因此我們也打算把我們的經驗公布給大家,也算是對社區的回饋吧。
作者簡介
DaoCloud 前端工程師 瞬光
一名中文系畢業的非典型程序員
一、我們遇到了什么困難
DaoCloud Enterprise(下文簡稱 DCE) 是 DaoCloud 的主要產品,它是一個應用云平臺,也是一個非常復雜的單頁面應用。它的復雜性主要體現在數據和交互邏輯兩方面上。在數據方面,DCE 需要展示大量數據,數據之間依賴關系繁雜。在交互邏輯方面,DCE 中有著大量的交互操作,而且幾乎每一個操作幾乎都是牽一發而動全身。但是交互邏輯的復雜最終還是會表現為數據的復雜。因為每一次交互,本質上都是在處理數據。一開始的時候,為了保證數據的正確性,DCE 里寫了很多處理數據、檢測數據變化的代碼,結果導致應用非常地卡頓,而且代碼非常難以維護。
在整理了應用數據層的邏輯后,我們總結出了以下幾個難點。本文會用較大的篇幅來描述我們所遇到的場景,這是因為如此復雜的前端場景比較少見,只有充分理解我們所遇到的場景,才能充分理解我們使用這一套設計的原因,以及這一套設計的優勢所在。
二、應用的難點
1. 數據來源多
DCE 的獲取數據的來源很多,主要有以下幾種:
(1) 后端、 Docker 和 Kubernetes 的 API
API 是數據的主要來源,應用、服務、容器、存儲、租戶等等信息都是通過 API 獲取的。
(2) WebSocket
后端通過 WebSocket 來通知應用等數據的狀態的變化。
(3) LocalStorage
保存用戶信息、租戶等信息。
(4) 用戶操作
用戶操作最終也會反應為數據的變化,因此也是一個數據的來源。
數據來源多導致了兩個問題:
(1) 復用處理數據的邏輯比較困難
由于數據來源多,因此獲取數據的邏輯常常分布在代碼各處。比如說容器列表,展示它的時候我們需要一段代碼來格式化容器列表。但是容器列表之后還會更新,由于更新的邏輯和獲取的邏輯不一樣,所以就很難再復用之前所使用的格式化代碼。
(2) 獲取數據的接口形式不統一
如今我們調用 API 時,都會返回一個 Promise。但并不是所有的數據來源都能轉換成 Promise,比如 WebSocket 怎么轉換成 Promise 呢?結果就是在獲取數據的時候,要先調用 API,然后再監聽 WebSocket 的事件。或許還要同時再去監聽用戶的點擊事件等等。等于說有多個數據源影響同一個數據,對每一個數據源都要分別寫一套對應的邏輯,十分啰嗦。
聰明的讀者可能會想到:只要把處理數據的邏輯和獲取數據的邏輯解耦不就可以了嗎?很好,現在我們有兩個問題了。
2. 數據復雜
DCE 數據的復雜主要體現在下面三個方面:
- 從后端獲取的數據不能直接展示,要經過一系列復雜邏輯的格式化。
- 其中部分格式化邏輯還包括發送請求。
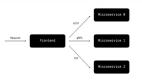
- 數據之間存在著復雜的依賴關系。所謂依賴關系是指,必須要有 B 數據才能格式化 A 數據。
下圖是 DCE 數據依賴關系的大體示意圖。

以格式化應用列表為例,總共有這么幾個步驟。讀者不需要完全搞清楚,領會大意即可:
- 獲取應用列表的數據
- 獲取服務列表的數據。這是因為應用是由服務組成的,應用的狀態取決于服務的狀態,因此要格式化應用的狀態,就必須獲取服務列表的數據。
- 獲取任務列表的數據。服務列表里其實也不包含服務的狀態,服務的狀態取決于服務的任務的狀態,因此要格式化服務的狀態,就必須獲取任務列表的數據。
- 格式化任務列表。
- 根據服務的 id 從任務列表中找到服務所對應的任務,然后根據任務的狀態,得出服務的狀態。
- 格式化 服務列表。
- 根據應用的 id 從服務列表中找到應用所對應的服務,然后根據服務的狀態,得出應用的狀態。順便還要把每個應用的服務的數據塞到每個應用里,因為之后還要用到。
- 格式化應用列表。
- 完成!
這其中摻雜了同步和異步的邏輯,非常繁瑣,非常難以維護(肺腑之言)。況且,這還只是處理應用列表的邏輯,服務、容器、存儲、網絡等等列表需要獲取呢,并且邏輯也不比應用列表簡單。所以說,要想解耦獲取和處理數據的邏輯并不容易。因為處理數據這件事本身,就包括了獲取數據的邏輯。
如此復雜的依賴關系,經常會發送重復的請求。比如說我之前格式化應用列表的時候請求過服務列表了,下次要獲取服務列表的時候又得再請求一次服務列表。
聰明的讀者會想:我把數據緩存起來保管到一個地方,每次要格式化數據的時候,不要重新去請求依賴的數據,而是從緩存里讀取數據,然后一股腦傳給格式化函數,這樣不就可以了嗎?很好!現在我們有三個問題了!
3. 數據更新困難
緩存是個很好的想法。但是在 DCE 里很難做,DCE 是一個對數據的實時性和一致性要求非常高的應用。
DCE 中幾乎所有數據都是會被全局使用到的。比如說應用列表的數據,不僅要在應用列表中顯示,側邊欄里也會顯示應用的數量,還有很多下拉菜單里面也會出現它。所以如果一處數據更新了,另一處沒更新,那就非常尷尬了。
還有就是之前提到的應用和服務的依賴關系。由于應用是依賴服務的,理論上來說服務變了,應用也是要變的,這個時候也要更新應用的緩存數據。但事實上,因為數據的依賴樹實在是太深了(比如上圖中的應用和主機),有些依賴關系不那么明顯,結果就會忘記更新緩存,數據就會不一致。
什么時候要使用緩存、緩存保存在哪里、何時更新緩存,這些是都是非常棘手的問題。
聰明讀者又會想:我用 redux 之類的庫,弄個全局的狀態樹,各個組件使用全局的狀態,這樣不就能保證數據的一致了嗎?這個想法很好的,但是會遇到上面兩個難點的阻礙。redux 在面對復雜的異步邏輯時就無能為力了。
三、結論
結果我們會發現這三個難點每個單獨看起來都有辦法可以解決,但是合在一起似乎就成了無解死循環。因此,在經過廣泛調研之后,我們選擇了 RxJs。
1. 為什么 RxJs 可以解決我們的困難
在說明我們如何用 RxJs 解決上面三個難題之前,首先要說明 RxJs 的特性。畢竟 RxJs 目前還是個比較新的技術,大部分人可能還沒有接觸過,所以有必要給大家普及一下 RxJs。
(1) 統一了數據來源
RxJs ***的特點就是可以把所有的事件封裝成一個 Observable,翻譯過來就是可觀察對象。只要訂閱這個可觀察對象,就可以獲取到事件源所產生的所有事件。想象一下,所有的 DOM 事件、ajax 請求、WebSocket、數組等等數據,統統可以封裝成同一種數據類型。這就意味著,對于有多個來源的數據,我們可以每個數據來源都包裝成 Observable,統一給視圖層去訂閱,這樣就抹平了數據源的差異,解決了***個難題。
(2) 強大的異步同步處理能力
RxJs 還提供了功能非常強大且復雜的操作符( Operator) 用來處理、組合 Observable,因此 RxJs 擁有十分強大的異步處理能力,幾乎可以滿足任何異步邏輯的需求,同步邏輯更不在話下。它也抹平了同步和異步之間的鴻溝,解決了第二個難題。
(3) 數據推送的機制把拉取的操作變成了推送的操作
RxJs 傳遞數據的方式和傳統的方式有很大不同,那就是改“拉取”為“推送”。原本一個組件如果需要請求數據,那它必須主動去發送請求才能獲得數據,這稱為“拉取”。如果像 WebSocket 那樣被動地接受數據,這稱為“推送”。如果這個數據只要請求一次,那么采用“拉取”的形式獲取數據就沒什么問題。但是如果這個數據之后需要更新,那么“拉取”就無能為力了,開發者不得不在代碼里再寫一段代碼來處理更新。
但是 RxJs 則不同。RxJs 的精髓在于推送數據。組件不需要寫請求數據和更新數據的兩套邏輯,只要訂閱一次,就能得到現在和將來的數據。這一點改變了我們寫代碼的思路。我們在拿數據的時候,不是拿到了數據就萬事大吉了,還需要考慮未來的數據何時獲取、如何獲取。如果不考慮這一點,就很難開發出具備實時性的應用。
如此一來,就能更好地解耦視圖層和數據層的邏輯。視圖層從此不用再操心任何有關獲取數據和更新數據的邏輯,只要從數據層訂閱一次就可以獲取到所有數據,從而可以只專注于視圖層本身的邏輯。
(4) BehaviorSubject 可以緩存數據。
BehaviorSubject 是一種特殊的 Observable。如果 BehaviorSubject 已經產生過一次數據,那么當它再一次被訂閱的時候,就可以直接產生上次所緩存的數據。比起使用一個全局變量或屬性來緩存數據,BehaviorSubject 的好處在于它本身也是 Observable,所以異步邏輯對于它來說根本不是問題。這樣一來第三個難題也解決了。
這樣一來三個問題是不是都沒有了呢?不,這下其實我們有了四個問題。
2. 我們是怎么用 RxJs 解決困難的
相信讀者看到這里肯定是一臉懵逼。這就是第四個問題。RxJs 學習曲線非常陡峭,能參考的資料也很少。我們在開發的時候,甚至都不確定怎么做才是***實踐,可以說是摸著石頭過河。建議大家閱讀下文之前先看一下 RxJs 的文檔,不然接下來肯定十臉懵逼。
| RxJs 真是太 TM 難啦!Observable、Subject、Scheduler 都是什么鬼啦!Operator 怎么有這么多啊!每個 Operator 后面只是加個 Map 怎么變化這么大啊!都是 map,為什么這個 map和_.map 還不一樣啦!文檔還只有英文噠(現在有中文了)!我昨天還在寫 jQuery,怎么一下子就要寫這么難的東西啊啊啊!!!(劃掉)
——來自實習生的吐槽 |
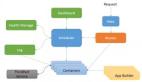
首先,給大家看一個整體的數據層的設計。熟悉單向數據流的讀者應該不會覺得太陌生。

- 從 API 獲取一些必須的數據
- 由事件分發器來分發事件
- 事件分發器觸發控制各個數據管道
- 視圖層拼接數據管道,獲得用來展示的數據
- 視圖層通過事件分發器來更新數據管道
- 形成閉環
可以看到,我們的數據層設計基本上是一個單向數據流,確切地說是“單向數據樹”。
樹的最上面是樹根。樹根會從各個 API 獲得數據。樹根的下面是樹干。從樹干分岔出一個個樹枝。每個樹枝的終點都是一個可以供視圖層訂閱的 BehaviorSubject,每個視圖層組件可以按自己的需求來訂閱各個數據。數據和數據之間也可以互相訂閱。這樣一來,當一個數據變化的時候,依賴它的數據也會跟著變化,最終將會反應到視圖層上。
四、設計詳細說明
1. root(樹根)
root 是樹根。樹根有許多觸須,用來吸收養分。我們的 root 也差不多。一個應用總有一些數據是關鍵的數據,比如說認證信息、許可證信息、用戶信息。要使用我們的應用,我們首先得知道你登錄沒登錄,付沒付過錢對不對?所以,這一部分數據是***層數據,如果不先獲取這些數據,其他的數據便無法獲取。而這些數據一旦改變,整個應用其他的數據也會發生根本的變化。比方說,如果登錄的用戶改變了,整個應用展示的數據肯定也會大變樣。
在具體的實現中,root 通過 zip 操作符匯總所有的 api 的數據。為了方便理解,本文中的代碼都有所簡化,實際場景肯定遠比這個復雜。
- // 從各個 API 獲取數據
- const license$ = Rx.Observable.fromPromise(getLicense());
- const auth$ = Rx.Observable.fromPromise(getAuth());
- const systemInfo$ = Rx.Observable.fromPromise(getSystemInfo());
- // 通過 zip 拼接三個數據,當三個 API 全部返回時,root$ 將會發出這三個數據
- const root$ = Rx.Observable.zip(license$, auth$, systemInfo$);
當所有必須的的數據都獲取到了,就可以進入到樹干的部分了。
2. trunk(樹干)
trunk 是我們的樹干,所有的數據都首先流到 trunk ,trunk 會根據數據的種類,來決定這個數據需要流到哪一個樹枝中。簡而言之,trunk 是一個事件分發器。所有事件首先都匯總到 trunk 中。然后由 trunk 根據事件的類型,來決定哪些數據需要更新。有點類似于 redux 中根據 action 來觸發相應 reducer 的概念。
之所以要有這么一個事件分發器,是因為 DCE 的數據都是牽一發而動全身的,一個事件發生時,往往需要觸發多個數據的更新。此時有一個統一的地方來管理事件和數據之間的對應關系就會非常方便。一個統一的事件的入口,可以大大降低未來追蹤數據更新過程的難度。
在具體的實現中,trunk 是一個 Subject。因為 trunk 不但要訂閱 WebSocket,同時還要允許視圖層手動地發布一些事件。當有事件發生時,無論是 WebSocket 事件還是視圖層發布的事件,經過 trunk 的處理后,我們都可以一視同仁。
- //一個產生 WebSocket 事件的 Observable
- const socket$ = Observable.webSocket('ws://localhost:8081');
- // trunk 是一個 Subject
- const trunk$ = new Rx.Subject()
- // 在 root 產生數據之前,trunk 不會發布任何值。trunk 之后的所有邏輯也都不會運行。
- .skipUntil(root$)
- // 把 WebSocket 推送過來的事件,合并到 trunk 中
- .merge(socket$)
- .map(event => {
- // 在實際開發過程中,trunk 可能會接受來自各種事件源的事件
- // 這些事件的數據格式可能會大不相同,所以一般在這里還需要一些格式化事件的數據格式的邏輯。
- });
3. branch(樹枝)
trunk 的數據最終會流到各個 branch。branch 究竟是什么,下面就會提到。
在具體的實現中,我們在 trunk 的基礎上,用操作符對 trunk 所分發的事件進行過濾,從而創建出各個數據的 Observable,就像從樹干中分出的樹枝一樣。
- // trunk 格式化好的事件的數據格式是一個數組,其中是需要更新的數據的名稱
- // 這里通過 filter 操作符來過濾事件,給每個數據創建一個 Observable。相當于于從 trunk 分岔出多條樹枝。
- // 比如說 trunk 發布了一個 ['app', 'services'] 的事件,那么 apps$ 和 services$ 就能得到通知
- const apps$ = trunk$.filter(events => events.includes('app'));
- const services$ = trunk$.filter(events => events.includes('service'));
- const containers$ = trunk$.filter(events => events.includes('container'));
- const nodes$ = trunk$.filter(events => events.includes('node'));
僅僅如此,我們的 branch 還沒有什么實質性的內容,它僅僅能接受到數據更新的通知而已,后面還需要加上具體的獲取和處理數據的邏輯,下面就是一個容器列表的 branch 的例子。
- // containers$ 就是從 trunk 分出來的一個 branch。
- // 當 containers$ 收到來自 trunk 的通知的時候,containers$ 后面的邏輯就會開始執行
- containers$
- // 當收到通知后,首先調用 API 獲取容器列表
- .switchMap(() => Rx.Observable.fromPromise(containerApi.list()))
- // 獲取到容器列表后,對每個容器分別進行格式化。
- // 每個容器都是作為參數傳遞給格式化函數的。格式化函數中不包含任何異步的邏輯。
- .map(containers => containers.map(container, container => formatContainer(container)));
現在我們就有了一個能夠產生容器列表的數據的 containers$。我們只要訂閱 containers$就可以獲得***的容器列表數據,并且當 trunk 發出更新通知的時候,數據還能夠自動更新。這是巨大的進步。
現在還有一個問題,那就是如何處理數據之間的依賴關系呢?比如說,格式化應用列表的時候假如需要格式化好的容器列表和服務列表應該怎么做呢?這個步驟在以前一直都十分麻煩,寫出來的代碼猶如意大利面。因為這個步驟需要處理不少的異步和同步邏輯,這其中的順序還不能出錯,否則可能就會因為關鍵數據還沒有拿到導致格式化時報錯。
實際上,我們可以把 branch 想象成一個“管道”,或者“流”。這兩個概念都不是新東西,大家應該比較熟悉。
| We should have some ways of connecting programs like garden hose—screw in another segment when it becomes necessary to massage data in another way.
——Douglas McIlroy |
如果數據是以管道的形式存在的,那么當一個數據需要另一個數據的時候,只要把管道接起來不就可以了嗎?幸運的是,借助 RxJs 的 Operator,我們可以非常輕松地拼接數據管道。下面就是一個應用列表拼接容器列表的例子。
- // apps$ 也是從 trunk 分出來的一個 branch
- apps$
- // 同樣也從 API 獲取數據
- .switchMap(() => Rx.Observable.fromPromise(appApi.list()))
- // 這里使用 combineLatest 操作符來把容器列表和服務列表的數據拼接到應用列表中
- // 當容器或服務的數據更新時,combineLatest 之后的代碼也會執行,應用的數據也能得到更新。
- .combineLatest(containers$, services$)
- // 把這三個數據一起作為參數傳遞給格式化函數。
- // 注意,格式化函數中還是沒有任何異步邏輯,因為需要異步獲取的數據已經在上面的 combineLatest 操作符中得到了。
- .map(([apps, containers, services]) => apps.map(app => formatApp(app, containers, services)));
4. 格式化函數
格式化函數就是上文中的 formatApp 和 formatContainer。它沒有什么特別的,和 RxJs 沒什么關系。
唯一值得一提的是,以前我們的格式化函數中充斥著異步邏輯,很難維護。所以在用 RxJs 設計數據層的時候我們刻意地保證了格式化函數中沒有任何異步邏輯。即使有的格式化步驟需要異步獲取數據,也是在 branch 中通過數據管道的拼接獲取,再以參數的形式統一傳遞給格式化函數。這么做的目的就是為了將異步和同步解耦,畢竟異步的邏輯由 RxJs 處理更加合適,也更便于理解。
5. fruit
現在我們只差緩存沒有做了。雖然我們現在只要訂閱 apps$ 和 containers$ 就能獲取到相應的數據,但是前提是 trunk 必需要發布事件才行。這是因為 trunk 是一個 Subject,假如 trunk 不發布事件,那么所有訂閱者都獲取不到數據。所以,我們必須要把 branch 吐出來的數據緩存起來。 RxJs 中的 BehaviorSubject 就非常適合承擔這個任務。
BehaviorSubject 可以緩存每次產生的數據。當有新的訂閱者訂閱它時,它就會立刻提供最近一次所產生的數據,這就是我們要的緩存功能。所以對于每個 branch,還需要用 BehaviorSubject 包裝一下。數據層最終對外暴露的接口實際上是 BehaviorSubject,視圖層所訂閱的也是 BehaviorSubject。在我們的設計中,BehaviorSubject 叫作 fruit,這些經過層層格式化的數據,就好像果實一樣。
具體的實現并不復雜,下面是一個容器列表的例子。
- // 每個數據流對外暴露的一個借口是 BehaviorSubject,我們在變量末尾用$$,表示這是一個BehaviorSubject
- const containers$$ = new Rx.BehaviorSubject();
- // 用 BehaviorSubject 去訂閱 containers$ 這個 branch
- // 這樣 BehaviorSubject 就能緩存***的容器列表數據,同時當有新數據的時它也能產生新的數據
- containers$.subscribe(containers$$);
6. 視圖層
整個數據層到上面為止就完成了,但是在我們用視圖層對接數據層的時候,也走了一些彎路。一般情況下,我們只需要用 vue-rx 所提供的 subscriptions 來訂閱 fruit 就可以了。
- <template>
- <app-list :data="apps"></app-list>
- </template>
- <script>
- import app$$ from '../branch/app.branch';
- export default {
- name: 'app',
- subscriptions: {
- apps: app$$,
- },
- };
- </script>
但有些時候,有些頁面的數據很復雜,需要進一步處理數據。遇到這種情況,那就要考慮兩點。一是這個數據是否在別的頁面或組件中也要用,如果是的話,那么就應該考慮把它做進數據層中。如果不是的話,那其實可以考慮在頁面中單獨再創建一個 Observable,然后用 vue-rx 去訂閱這個 Observable。
還有一個問題就是,假如視圖層需要更新數據怎么辦?之前已經提到過,整個數據層的事件分發是由 trunk 來管理的。因此,視圖層如果想要更新數據,也必須取道 trunk。這樣一來,數據層和視圖層就形成了一個閉環。視圖層根本不用擔心數據怎么處理,只要向數據層發布一個事件就能全部搞定。
- methods: {
- updateApp(app) {
- appApi.update(app)
- .then(() => {
- trunk$.next(['app'])
- })
- },
- },
下面是整個數據層設計的全貌,供大家參考。

總結
之后的開發過程證明,這一套數據層很大程度上解決了我們的問題。它***的好處在于提高了代碼的可維護性,從而使得開發效率大大提高,bug 也大大減少。
【本文是51CTO專欄機構“道客船長”的原創文章,轉載請通過微信公眾號(daocloudpublic)聯系原作者】