













數(shù)據(jù)庫寫操作棄用“SELECT … FOR UPDATE”解決方案
問題闡述
Mysql Galera集群是迄今OpenStack服務***的Mysql部署方案,它基于Mysql/InnoDB,我的OpenStack部署方式從原來的主從復制轉換到Galera的多主模式。
Galera雖然有很多好處,如任何時刻任何節(jié)點都可讀可寫,無復制延遲,同步復制,行級復制,但是Galera存在一個問題,也可以說是在實現(xiàn) 真正的多主可寫上的折衷權衡,也就是這個問題導致在代碼的數(shù)據(jù)庫層的操作需要棄用寫鎖,下面我說一下這個問題。
這個問題是Mysql Galera集群不支持跨節(jié)點對表加鎖,也就是當OpenStack一個組件有兩個會話分布在兩個Mysql節(jié)點上同時寫入一條數(shù)據(jù),其中一個會話會遇到 死鎖的情況,也就是得到deadlock的錯誤,并且該情況在高并發(fā)的時候發(fā)生概率很高,在社區(qū)Nova,Neutron該情況的報告有很多。
這個行為其實是Galera預期的結果,它是由樂觀鎖并發(fā)控制機制引起的,當發(fā)生多個事務進行寫操作的時候,樂觀鎖機制假設所有的修改都能 沒有沖突地完成。如果兩個事務同時修改同一個數(shù)據(jù),先commit的事務會成功,另一個會被拒絕,并重新開始運行整個事務。 在事務發(fā)生的起始節(jié)點,它可以獲取到所有它需要的鎖,但是它不知道其他節(jié)點的情況,所以它采用樂觀鎖機制把事務(在Galera中叫writes et)廣播到所有其他節(jié)點上,看在其他節(jié)點上是否能提交成功。這個writeset會在每個節(jié)點上進行驗證測試,來決定該writeset是否被接受, 如果檢驗失敗,這個writeset就會被拋棄,然后最開始的事務也會被回滾;如果檢驗成功,事務就被提交,writeset也被應用到其他節(jié)點上。 這個過程如下圖所示:
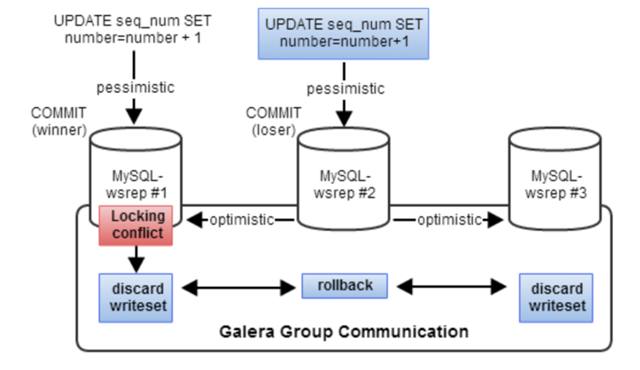
在Python的SQLAlchemy庫中,有一個“with_lockmode(‘update’)”語句,這個代表SQL語句中的“SELECT … FOR UPDATE”,在我參與過的計費項目和社區(qū)的一些項目的代碼中有大量的該結構,由于寫鎖不能在集群中同步,所以這個語句在Mysql集群中就沒有得到它應有的效果,也就是在語義上有問題,但是***Galera會通過報deadlock錯誤,只讓一個commit成功,來保證Mysql集群的ACID性。
一些解決方法
- 把請求發(fā)往一個節(jié)點,這個在HAProxy中就可以配置,只設定一個節(jié)點為master,其余節(jié)點為backup,HAProxy會在master失效的時候 自動切換到某一個backup上,這個也是很多解決方案目前使用的方法,HAProxy配置如下:
- server xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx:3306 check
- server xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx:3306 check backup
- server xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx:3306 check backup
- 對OpenStack的所有Mysql操作做讀寫分離,寫操作只在master節(jié)點上,讀操作在所有節(jié)點上做負載均衡。OpenStack沒有原生支持,但 是有一個開源軟件可以使用,maxscale。
***解決方法
上面的解決方法只是一些workaround,目前情況下最***的解決方法是使用lock-free的方法來對數(shù)據(jù)庫進行操作,也就是無鎖的方式,這就 需要對代碼進行修改,現(xiàn)在Nova,Neutron,Gnocchi等項目已經(jīng)對其進行了修改。
首先得有一個retry機制,也就是讓操作執(zhí)行在一個循環(huán)中,一旦捕獲到deadlock的error就將操作重新進行,這個在OpenStack的oslo.db中已 經(jīng)提供了相應的方法叫wrap_db_retry,是一個Python裝飾器,使用方法如下:
- from oslo_db import api as oslo_db_api
- @oslo_db_api.wrap_db_retry(max_retries=5, retry_on_deadlock=True,
- retry_on_request=True)
- def db_operations():
- ...
然后在這個循環(huán)之中我們使用叫做”Compare And Swap(CAS)”的無鎖方法來完成update操作,CAS是***在CPU中使用的,CAS說白了就是先比較,再修改,在進行UPDATE操作之前,我們先SELEC T出來一些數(shù)據(jù),我們叫做期望數(shù)據(jù),在UPDATE的時候要去比對這些期望數(shù)據(jù),如果期望數(shù)據(jù)有變化,說明有另一個會話對該行進行了修改, 那么我們就不能繼續(xù)進行修改操作了,只能報錯,然后retry;如果沒變化,我們就可以將修改操作執(zhí)行下去。該行為體現(xiàn)在SQL語句中就是在 UPDATE的時候加上WHERE語句,如”UPDATE … WHERE …”。
給出一個計費項目中修改用戶等級的DB操作源碼:
- @oslo_db_api.wrap_db_retry(max_retries=5, retry_on_deadlock=True,
- retry_on_request=True)
- def change_account_level(self, context, user_id, level, project_id=None):
- session = get_session()
- with session.begin():
- # 在會話剛開始的時候,需要先SELECT出來該account的數(shù)據(jù),也就是期望數(shù)據(jù) account = session.query(sa_models.Account).\
- filter_by(user_id=user_id).\
- one()]
- # 在執(zhí)行UPDATE操作的時候需要比對期望數(shù)據(jù),user_id和level,如果它們變化了,那么rows_update就會被賦值為0 ,就會走入retry的邏輯
- params = {'level': level}
- rows_update = session.query(sa_models.Account).\
- filter_by(user_id=user_id).\
- filter_by(level=account.level).\
- update(params, synchronize_session='evaluate')
- # 修改失敗,報出RetryRequest的錯誤,使上面的裝飾器抓獲該錯誤,然后重新運行邏輯 if not rows_update:
- LOG.debug('The row was updated in a concurrent transaction, '
- 'we will fetch another one')
- raise db_exc.RetryRequest(exception.AccountLevelUpdateFailed())
- return self._row_to_db_account_model(account)
數(shù)據(jù)的一致性問題
該問題在OpenStack郵件列表中有說過,雖然Galera是生成同步的,也就是寫入數(shù)據(jù)同步到整個集群非常快,用時非常短,但既然是分布式系 統(tǒng),本質上還是需要一些時間的,尤其是在負載很大的時候,同步不及時會很嚴重。
所以Galera只是虛擬同步,不是直接同步,也就是會存在一些gap時間段,無法讀到寫入的數(shù)據(jù),Galera提供了一個配置項,叫做wsrep_sync_ wait,它的默認值是0,如果賦值為1,就能夠保證讀寫的一致性,但是會帶來延遲問題。













