













時培昕:工業物聯網和工業大數據助力企業實現智能制造|V課堂第83期
工業物聯網作為制造業智能化的核心部分被稱之為智能制造的神經系統。而工業大數據又是智能化的來源,未來制造企業的運營過程,或者說產品的全生命周期都將由大數據串聯起來。那么大數據和工業物聯網是如何共同助力企業實現智能智造呢?
第83期【智造+V課堂】分享嘉賓:北京寄云鼎城創始人兼CEO時培昕博士,作為互聯網專家,時博士就“工業大數據和工業物聯網如何助力企業實現智能制造”的主題帶來精彩分享!
分享嘉賓
北京寄云鼎城創始人兼CEO 時培昕
1. 個人簡介
- 北京寄云鼎城科技有限公司創始人兼CEO;
- 企業級云計算聯盟 副秘書長;
- 2003年畢業于北京郵電大學,信號與信息處理專業博士;
- 2003年-2005年,北京萬林克通信技術有限公司任硬件經理;
- 2005年-2013年,漢柏科技有限公司聯合創始人、歷任研發總監,研發中心總經理,戰略產品中心總經理,海外技術總監,漢柏研究院院長;
- 2012年,任《信息安全與與技術》雜志編審委員會成員 。
2. 行業成就
- 時培昕博士是國內最早從事云計算和大數據相關領域研究的人員之一,擁有長達15年的管理和創業經驗。
- 目前帶領所在公司團隊研發的寄云工業物聯網平臺的發布填補了國內該領域的空白,是國內******、擁有獨立自主產權的平臺。
- 在漢柏工作期間,組建研發團隊,開發包括防火墻、安全網關、防火墻、流控,此外負責新產品策劃和大項目支持,承接過多個大型云計算數據中心和大數據項目的設計和建設,對計算機網絡、網絡安全、計算和存儲、虛擬化、云計算以及大數據有著多年豐富的項目咨詢和實施的經驗。
- 憑借多年企業市場的產品開發和服務經驗,以及雄厚的技術積累,時培昕博士率領眾多技術專家和行業專家,發布了從設備端到服務器端的整體工業互聯網平臺解決方案,包括工業網關、工業物聯網平臺、工業大數據平臺和工業云平臺。
3. 榮獲獎項
- 2015年4月,榮獲商業伙伴頒發的方案商創新人物獎;
- 2015年12月,榮獲賽迪網頒發的2015 SaaS行業***影響力人物獎;
- 2016年4月,再次榮獲商業伙伴頒發的2016中國方案商***人物獎;
- 2016年9月,榮獲云鼎獎-中國***影響力人物獎;
- 2017年4月,入選2017未來人物100名;
- 2017年4月,連續第三次榮獲2017中國方案商精英人物獎;
分享主題
《工業物聯網和工業大數據助力企業實現智能制造》
原文實錄
原文實錄context:
先簡單介紹一下寄云科技,寄云科技還是一個比較年輕的公司,我們成立4年左右的時間,我們主要是在給大型的工業企業的客戶和一些不同行業的企業提供數字化轉型的解決方案,我們更關注怎么用先進的IT技術去解決一些OT的問題。我們現在的業務單元主要是在北京、上海和西安三個地方,我們服務的行業也包括軌道交通、電力能源、航空航天,還有包括一些裝備制造。

現在各方面都有一些非常多的新技術出現,會給整個工業帶來一些新的沖擊。這里面我們看得見的,跟工業緊密相關的是一些新的技術,包括工業物聯網聯接不同的工業設備,采集工作設備傳感器的數據實現邊緣計算,也包括工業大數據,通過存儲海量的歷史數據,實時地分析海量的工業數據掌控設備當前的狀況,洞悉設備歷史的趨勢。

同時,也會包括一部分人工智能的話題。比方說,怎么去找到問題的相關性,怎么從歷史數據里面去學習一些異常的模型來去實現對當前狀態的一個判決。包括怎么對一些關鍵指標實現人工智能的一些預測和判決。云計算主要是指能夠提供很多便利的一些手段和便利的一些資源,包括怎么在任何時間、任何地點來使用,以及怎么去彈性擴展、按需使用的一個方式。

從大的角度來說,大家也都理解未來的制造一定是一個數據驅動的智能制造。左邊這張圖其實是一個大家比較耳熟能詳的一套數據流程,但是它是以控制為目的的,從傳感器的數據采集到PLC這種控制系統,實現簡單地一些存儲和一些告警,然后再上到生產管理系統,再上到企業的經營管理系統,一直到上面最上層的決策系統,所以它實現的是從最原始的數據到到***層價值的一個體現。

其實我們看得見是從最原始的數據到最終展現,它是需要一層一層往上傳遞的,但原有的系統由于它是以控制為目的的,所以它在以數據采集,包括數據分析都是以控制為目標的,實現的數據采集的量,包括準確度,包括范圍可能都有一些限制。
我們現在看得見更多還是希望通過這些原始的數據能夠發現更多的價值,這個價值包括一些設備的故障診斷,包括性能的優化,包括能效的一些分析,這些價值的原始數據都是來自于最原始的控制系統和傳感器的這些數據。
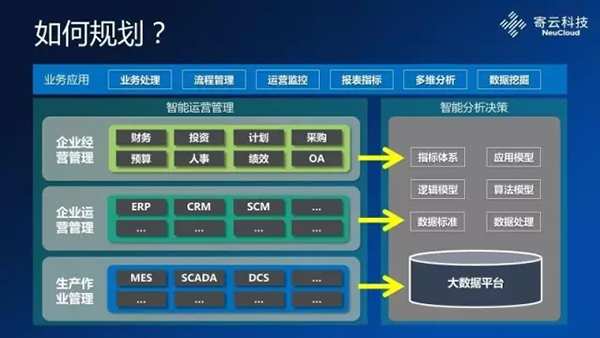
關于工業企業的大數據平臺,我這里給了一些規劃的建議圖,大家可以做一些參考。其實左邊這一列是大家都比較熟悉的一些,從最基本的生產作業的管理MES、DCS、FCS這些控制系統里面做的一些控制邏輯提取來的數據,再上升到企業的經營管理、運營管理的過程中,需要的供應鏈管理,相應的決策經營管理,包括整個物料的管理。再上到最上層其實就是相當于企業內部流程的管理,包括財務,包括人事,包括績效這些。但這些業務系統其實跟我們要做的工業大數據分析并不沖突。我們更多還是希望從左邊業務系統和控制系統中,從更多地維度來去提取有效的數據,來形成右邊工業大數據的一個平臺,把它所有的數據注入到我們一個大的平臺里面,采用不同的模型,建立不同的指標,包括基于不同主題來去構建相應算法和模型來實現可視化。
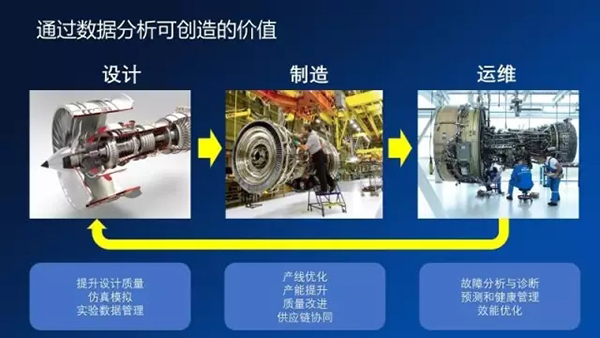
通過這種數據分析能創造什么樣的價值?可以用在哪些應用場景呢?我們看得見,主要還是在三段:設計、制造、運維。
在設計端其實大家討論得比較少,主要還是針對一些提升設計質量,包括一些模擬仿真,包括實驗數據管理這些,我們接觸得也相對比較少一點。我們在做的更多一個范疇其實還是集中在后面兩塊,制造和運維。在制造這一端,我們可以從很多的生產數據里面提取出來有效地數據來實現一些質量的改進,產線地優化,包括一些供應鏈協同的,包括效能提升的一些事情。
在運維端主要是針對一些大型地工業設備,其實我們現在在提的比較多PHM,也就是預測和健康管理。通過采集這種大型工業設備的運行數據來實時地評估設備當前的工作狀態,以及提前的預警來保證這種大型裝備不要出故障,不要出現一些非計劃的停機,最終實現效能的提升,這是運維端要考慮的事情。我就拿幾個例子來簡單給大家展開分析一下。

***個例子,其實是我們在做的一個整車廠質量追蹤的問題。這個整車廠其實是在生產的過程中發現有一些問題,它因為從上游的零件大概過了三天之后才能到總裝的車間,但是到了總裝車間的時候會發現有一些部件縫隙過大的情況,但是因為它在整個生產流程的過程中,上百個環節里面,都按照標準的SOP的方式來去操作,所以它非常想知道最終縫隙過大的情況到底是由什么造成的。我們找客戶搖了整個生產過程中產線采集下來的數據,總共9個測量的參數和不同維度的一些數據。
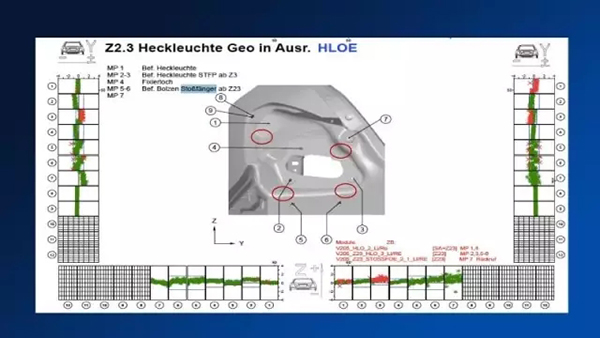

這一塊其實有9個測點,每個測點大概有X、Y、Z,三個不同方向的一些誤差測量。我們其實也是把這些數據采集下來,首先做了一個前后的對齊,因為它有不同批次。之后我們又做了一個關聯矩陣的分析,找到最終的測量數據是和之前的哪一個測點的數據是相關的,最終得到了一個判決結果,也就是導致縫隙過大的質量問題其實是由三個測點的數據造成的。對于客戶來說,你在整個三天的過程中,你只要能夠實時地監測這三個測點,而不用監測全部九個參數,構建一個異常模型,就可以監控加工過程的質量。一旦我們實時的數據跟這個模型出現一些偏差,我們就可以提前預知到這個設備已經出現了縫隙過大這樣的情況,我們就可以提前把這個設備給停下來,而不用到***一步才采取措施。

第二個案例,風力發電機葉根螺栓斷裂的分析。風力發電機大家其實也都知道,一般都是在野外幾百公里之外,客戶每巡檢一次他都會發現風力發電機的葉片有一些都已經掉下來了,但什么時候掉的,其實他并不知道。
有些葉片都已經掉下來了,但什么時候掉的其實他并不知道。掉的原因客戶也都知道,葉片根部會有一些螺栓,螺栓在旋轉的過程中都出現一些松動,當掉1-6根的時候螺栓葉片還可以修,但是超過6根之后,螺栓基本上會出現一個加速損壞的過程,直到葉片斷下來。每次維修葉片的費用基本上是在幾十萬到幾百萬不等。

我們自然會想能不能給螺栓加一個傳感器來監測這個螺栓什么開始斷的,其實這個比較比較難。因為螺栓實在是太多了,每個風機上大概有150個螺栓,加傳感器的成本是實在太高。我們就給客戶建議,是不是能夠通過傳感器本身的風機上帶來各種各樣的數據來推測螺栓斷裂的情況呢?正好風機現在有很多的傳感器,包括機艙角度、輪轂的轉速、風速、變槳角度,這些大概總共有幾十個指標,我們就拿過來做分析。
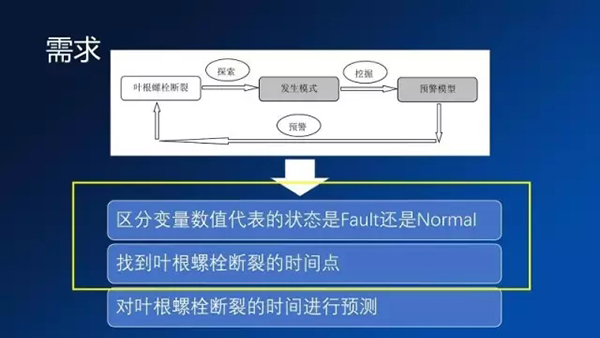
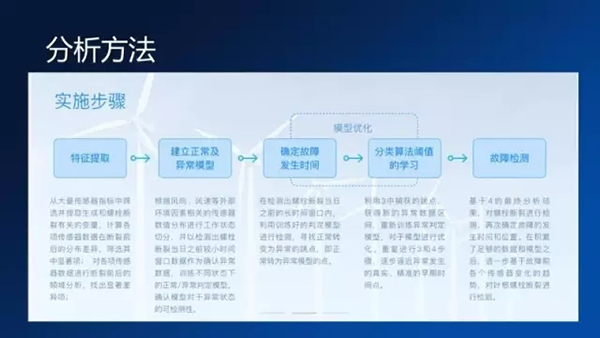
我們在這上面做的事情其實就是包括下面幾步了,首先我們從歷史的數據里面提取一些特征,然后構建一個正常和一個異常的模型,把其他故障風機的數據輸入到模型里面,來去根據模型去做判決,來去確定故障發生的時間,在這個上面去預測故障發生的未來趨勢。
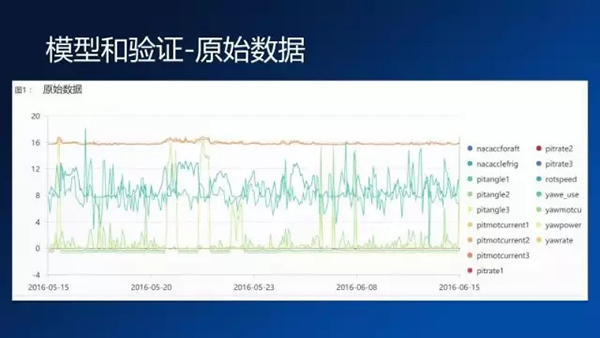
這張圖其實是一個原始的數據。大家可以從圖上可以看到,從2016年5月16日到6月15日,如果從單一變量或者組合變量這個邏輯上來說,其實你是看不出來有太大的規律,每個信號在這段時間內表現的現象前后沒有什么差別。
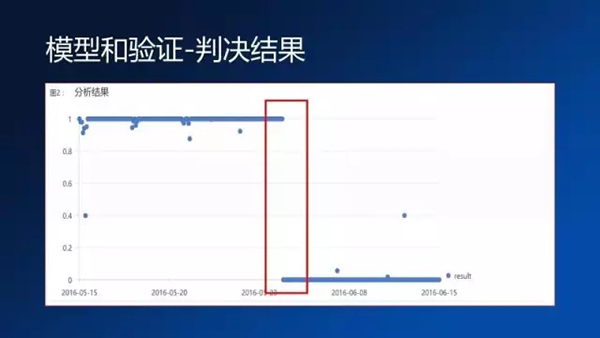
但是我們把這個變量全部送到模型之后,我們得到的判決結果是非常驚人的。這個判決結果在我的紅框這一段范圍之前,大家也都看得見,這是一個1的判決,就是說明它是一個正常的狀態。在紅框的范圍之后,是一個0判決,零判決是一個故障的狀態。這個判決其實非常明顯,我們做的過程其實就是拿歷史數據訓練出來一個故障模型,基于這個模型去對設備實時的數據進行判決,根據這個模型的判決結果和歷史之間的偏差,它相應的分布來去決定這個設備當前狀態是一個正常狀態,還是一個故障狀態。

第三個案例,我們叫做故障關聯性的分析。這個案例是整車的一些維修記錄的分析,我們的目標是從長達十多年的故障維修記錄里面找到故障的關聯關系。大家可以看左邊的這個圖,所有的結點代表了一種不同類型的故障,故障和故障之間會有一定的關聯關系。通過調整每一個結點,你把鼠標移到這些結點之上呢,你都可以看見這個故障是和什么樣的故障相關。比方說,雨刷只和玻璃相關,但是玻璃又和非常多的部件相關。在這個過程中,我們可以調整過濾的關聯門限值,我們發現了最Top的兩個故障是一個通訊設備的故障和一個探照頂燈的故障,也就是照明系統的故障。在原廠的設計過程中,不可能預測到照明系統和通信系統之間有很強的故障關聯性。我們用這種大數據的方式幫他去找出關聯關系,客戶自己去找的原因,***發現其實是在組裝的過程中,把不同的線捆在了一起,這就造成了它兩種不同的故障之間伴隨高頻次發生的概率。

還有一個案例,其實也是故障分析的方式。我們其實是把大量的故障,根據他的時間軸上做了一些切片。切片然后之后,找出來每一個故障的前序和后續發生的一些事件,相當于來做故障的溯源,分析這個故障產生的路徑。你可以看這張圖,其實是風機故障的圖,我們叫Spath。你根據最右邊出現的一個故障,你可以往前去推這個故障,比方說,產生1000種這樣的故障有多少個?有500個是由故障造成的?這500個故障又是由一個什么樣故障造成的?你可以按照這種方式時間軸來去推測這個故障發生的路徑,這其實是幫助維修和分析人員能快速來找到故障產生的原因。

前面提到的各個不同的案例,其實還是主要還是數據分析,我也是想讓大家看得見,通過數據分析能夠解決很多質量包括運維層面,很多我們以前解決不了的一些問題。但是這個問題怎么從數據來發現價值呢?其實它要有很長的鏈條,我們把它分成了幾段,一個是數據采集,一個是數據存儲,一個是數據分析還有性能的預測,包括應用開發出來一個可視化的應用。

我們說這幾個環節大家都理解,但是是大家都會面對很多的難題。首先說數據采集,工業數據采集的時候都會涉及到不同的設備,不同的封閉的協議,不同的接口,海量的測點你怎么去采集,包括很多的惡劣的工況,你的數據怎么去傳回來。

同樣在工業這種傳感器的數據、工業設備的數據的存儲上面也存在很多問題。
***,它的測點非常多,采集的點也非常多。無論是采集的方式還是存儲的介質都非常多樣,同時量也非常大。對存和查的性能壓力也非常大。因為海量的數據,特別是大型的設備都希望有一個長達數年的存儲周期,但原有的控制系統并不是以分析為目標的,他更多是以控制為目標的,所以他采集的時間跨度都不大,這也是一個巨大的挑戰。

數據分析同樣面臨著一些問題,不用說數據量大了,因為原來大家用的各種各樣的分析,包括Matlab等,我們都把這類的分析叫截面分析,或者說對短時間離線數據的一個分析。它處理幾十M到幾十G這樣小的、短時的數據沒問題,但是如果要讓他處理一個TB級別、數據維度比較多的,而且還是實時的這種數據時,基本上這類工具都沒有特別好的一個辦法。因此也沒辦法從這里面去得到一些定量的分析結果,因此這些工具都并不是為我們現在的、實時的、海量的工業數據的分析而設計的。

正是由于這些數據采集的維度比較少,歷史跨度比較短,所以沒有辦法積累起來長期的故障模型和歷史的學習曲線。因此在這上面去做預測基本上會非常難,而且很多新的算法,如今天神經網絡、深度學習的一些方法,都沒辦法在這些原有的分析工具上得到體現。

***是應用開發,把這些我們可以看得見的分析結果,以可視化、可交互的一個應用的方式展示出來,還需要很多的應用開發工作。但是大家也都知道,工業應用本身開發的過程就是非常漫長的過程,也包括特性的迭代相對比較慢,包括架構都很落后,很多工業應用還在采用單塊化的應用架構,它并不是可以支持海量數據、分布式、可拓展的這種架構,后期運維的壓力也都會比較大。


前面五個環節提到了很多的挑戰,我們為了解決這些問題,花了三年多的時間,開發了我們自己的NeuSeer工業互聯網平臺,也非常歡迎大家登錄到我們這個平臺上去做測試。它有非常多的算法、模型,包括開發應用的一些工具和服務。

平臺也是分成三段的一個架構,在邊緣端我們會有相應的工業網關,能夠讀取得不同的協議,然后把它的數據傳到我們云端。平臺可以私有化部署,也可以基于我們公有云的平臺來提供服務。云端的平臺會提供一些基礎的數據存儲能力。基于這些存儲的歷史數據,我們可以在上面利用我們的工業大數據分析平臺和應用開發平臺來構建相應的遠程監控、故障診斷、故障預測的應用,***能夠以不同的行業解決方案的方式給到最終的客戶。

這是我們一款工業網關,它***的特點能夠實現不同的工業協議的解析,我們也在不斷豐富我們能夠支持的協議類型。它能夠提供相應的數據的采集,能夠把數直接從工業協議的接口里面直接讀出來,并且把它變成一個可以傳輸到我們的平臺上來實現解析規劃的協議。

這是一個架構我就不多說了,支持不同的協議,我們通過讀取PLC、DCS、SCADA這樣不同的業務系統,實現歸一化,然后把它通過MQTT的格式傳回到我們的NeuSeer平臺。

在平臺的數據存儲上我們提供很多不同的方式,因為根據客戶的不同類型可能會有不同的需求,包括文件存儲,包括HDFS的文件存儲,包括一些結構化數據庫,還有包括我們自己開發的時序數據庫。


時序數據庫是我們針對海量的工業設備的數據提取、查詢和展示的產品套件。這個架構大家也都可以看它本身就是一個分布式的架構,我們可以支持文件和實時的流的導入,實現數據的海量歷史數據的存儲,我們也可以在上面構建一些分析和定制化的儀表盤,可以做一些簡單的統計分析。比方說平均值、***值、最小值,包括一些簡單關聯分析。針對海量工業數據,特別是帶有時間標簽的工業數據,時序數據庫能夠提供***的測點,實現讀取和分析,提供很好的擴展性。

除了提供海量的存儲和讀取的能力我們還在上面構建了一些可以自己定義的可視化面板,用戶可以根據我們大概提供的幾十種的不同的模板,基于時序數據來做一些比較好的分析圖表,并且嵌入到用戶自己的應用里面。

關于大數據分析的平臺,我們也是針對這種海量的、實時的、多維的數據來提供一個相對比較高性能、分布式的、專門的工業大數據分析平臺。它是基于Spark這樣架構構建起來的,并且我們增強了很多Spark本身沒有的算法和模型庫。

這是我們提供的一些基礎的算法,工業分析里面用了非常多的一些信號處理的算法,包括去噪、差值、取樣、填充,很多這類型的基礎數據預處理。針對振動信號這類的分析,還要做傅立葉變化、小波變換等。我們提供了非常多的基礎的數據處理的方式,并且是基于Spark架構來開發的,算法能夠在可以拓展的分布式的架構上面跑,這是傳統像Matlab這樣的分析工具沒辦法實現的。同時我們也提供了很多的針對海量數據、特別是時序數據的轉換工具。比方說橫豎變化、平均、差值等,還有大量的自回歸、神經萬絡算法,都是針對海量的、帶有時間標簽的傳感器數據的算法和工具。

我們也提供一些可視化的模塊,可視化開發的模塊用戶可以構建類似剛才我提到的相關的關聯分析、故障路徑的分析這樣的可視化結果。其實跟以前需要自己畫圖這種方式不太一樣,用戶可能只需要調用一個平臺的API,把數據送給平臺,平臺就可以直接能畫好的結果,以一個鏈接地址的方式嵌入到用戶的應用里面就可以了。

除了算法之外,我們還提供了一些模型,我們分為三類模型:
***類是指追溯過去,洞悉過去。這包括我們剛才提到的故障診斷。故障診斷其實就是從海量歷史數據里面找到故障產生的原因,找到故障產生的路徑,我們可以提供關聯分析、故障路徑的分析這類的模型。

第二類模型叫掌控當前、性能評估的模型,客戶可以利用歷史數據來去選擇相應的變量,去訓練出來一些模型。客戶會參與到這個模型訓練,指定哪一段時間是一個正常狀態,我們就把所有相關的變量扔到模型里面來訓練出一個正常狀態。后期的所有的數據都針對于訓練出來的模型來去做相應的判決,一旦出現了超出歷史數據分布范圍之外的一些數據,我們就認為是異常的情況。結合很多維度的分析,我們就可以實現異常檢測。

基于歷史數據,我們還可以實現對未來的預測,我們基于神經網絡來構建這種預測模型,其實大家可以從這個圖去看見,它可以很好根據你之前的數據來去預測未來信號的走向和變量發展的趨勢。

我們也提供了很好的模型開發與應用的過程,客戶可以在我們基于他的歷史數據,來去訓練出來一個模型,然后經過一些測試把這個模型發布到我們模型目錄里面,算法目錄里面。根據這個算法目錄再把實時的數據去調取,通過API的方式扔到這個模型上做實時的判決,來實現對未來的預測。未來預測的結果還可以經過一個反饋,來去修正原有的模型,***以一個工業應用的方式實現人機交互。


***說到一些工業應用的應用開發。我給了一張框圖,大家可以看見,我們把整個工業應用分成了非常多的模塊。我們提供了一個框架,這個框架左邊是一些工業采集的設備,這些設備包括我們自己的工業網關和合作伙伴的一些網關,只要滿足我們的SDK,就可以接入。把它發到我們平臺提供的MQTT的Broker上面。
MQTT的消息直接可以被應用訂閱,實現實時監控。同時,MQTT的數據可以通過KAFKA再到HDFS成為一個歷史數據,再變成TSDB里面的可以存的這種被檢索出來的歷史數據,可以再提供到我們大數據分析平臺上面來去構建相應的歷史模型。這些歷史模型構建完之后,可以發布到我們的目錄里面,然后再通過API的方式對這個應用來去調用,同時我們還提供了很多外圍Service,包括賬戶管理,包括權限,包括數據庫,包括可視化結果的呈現,這些所有外圍的功能,我們都把它做成一個微服務的方式,可以極大降低的應用開發的工作量。

開發的過程中我們提供了很好的DevOps的過程,從整個應用的代碼源,把代碼抓下來,編譯、打包生成一個部署環境。再把他扔到云端平臺上來,實現一個可以拓展的架構,這都是一個自動化的過程,并且我們也提供很好的重新自動構建的過程,用戶只要把代碼做一些改動,它會自動來去抓起這個代碼,完成整個自動編譯打包、生成部署環境的完整的自動化的過程。

這個是剛才我們提到的微服務的架構。一些新的應用,我們建議盡量采用微服務的方式去構建,每個應用有自己相應的邏輯,后臺每個功能模塊我們都建議設計成微服務的架構,并且可以調用我們平臺提供各種各樣的服務接口。比方說HDFS、包括TSDB這些服務,你根本不用考慮這個服務怎么去部署,怎么去運維,你只需要訂閱我們的一個服務,你就可以得到一個接入地址,你把數據扔到這個平臺上你就可以存,你把數據扔到模型里面你就可以算,這個是非常方便的。

***,希望通過我們的NeuSeer平臺幫助客戶來實現連接、洞察和優化,通過連接來連接不同的IT和OT的系統采集數據,把設備聯上來,建立一些數據標準,存儲海量的工業數據。通過洞察能夠對設備的質量,故障產生的原因進行深度的分析,構建可分析的指標,構建一些可視化各應用。通過優化實現我們更智能的動作,包括計劃排產,包括預測性維修,包括一些質量改進,供應鏈優化這些。














