微信OCR(2):深度序列學習助力文字識別
此篇文章屬于微信OCR技術介紹系列,著重介紹如何采用深度序列學習(deep sequence learning)方法實現端到端的文本串識別并應用于微信產品。本篇主要為方法綜述,下一篇著重介紹深度序列學習技術在微信產品中的落地。這里,文本串識別的輸入默認已經是包含文本(行或者單詞)的最小外接矩形框,其目的是識別其中的文字內容,如圖1所示。前面的文本框檢測和定位工作,詳見我們之前的文章【1】介紹。

圖1:文本串識別示例
分階段vs端到端
文本串識別作為目標識別的一個子領域,其本質是一個多類分類問題:旨在尋找從文本串圖像到文本串內容的一種映射,這和人臉識別、車輛識別等都是類似的。然而,文本串作為序列目標,又有其獨特性:
1. 局部性:即文本串中的局部都會直接體現在其整體label中。舉個栗子:“我想吃飯” 和“我不想吃飯”,一字之差,體現在圖像特征中,只是局部特征變化,然而文本串的含義截然相反。而在一般的目標識別問題中(細粒度目標識別除外),這種局部干擾恰恰是要被抑制的。比如,張三帶了墨鏡還是張三。
2. 組合性:文本串內容千差萬別,以常用英文單詞為例,約有9w多個。漢字的組合就更加龐大了。然而不管是萬字長文,還是簡短對話,它們的組成都是有限種類的字符:26個英文字母,10個數字,幾千個漢字,諸如此類。
基于以上兩點,一種直觀的串識別方法是:首先切分到單字,識別單字的類別,然后將識別結果串聯起來。這種化整為零的方法是OCR在深度學習出現之前的幾十年里通用的方法,其流程如圖2所示。

圖2:根據各種圖像特征進行單字切分
然而,這個方法有兩個明顯的弊端:1. 切分錯誤會影響識別性能;2. 單字識別未能考慮上下文信息。為了彌補這兩點缺陷,傳統方法往往需要對圖像進行“過切分”,即找到所有可能是切點的位置,然后再將所有切片和可能的切片組合統統送給單字識別模塊,通過在各個識別結果中間進行“動態規劃”,尋找一條***路徑,從而確定切分和識別的結果。在尋優過程中,往往還需要結合文字的外觀統計特征以及語言模型(若干字的同現概率)。可見,這里切分、識別和后處理存在深度耦合,導致實際系統中的串識別模塊往往堆砌了非常復雜和可讀性差的算法。而且,即便如此,傳統方法依然有不可突破的性能瓶頸,比如一些復雜的藝術體和手寫體文字,嚴重粘連的情況等等。總而言之,傳統方法的問題在于:處理流程繁瑣冗長導致錯誤不斷傳遞,以及過分倚重人工規則并輕視大規模數據訓練。
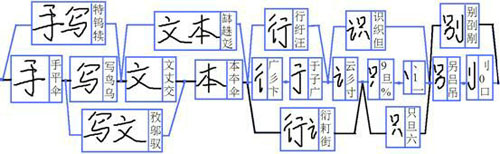
圖3:基于過切分和動態規劃得到文本串內容
從2012 年的ImageNet競賽開始,深度學習首先在圖像識別領域發揮出巨大威力。隨著研究的深入,深度學習逐漸被應用到音頻、視頻以及自然語言理解領域。這些領域的特點是針對時序數據的建模。如何利用深度學習來進行端到端的學習,并摒棄基于人工規則的中間步驟,以提升Sequence Learning的效果已經成為當前研究的熱點。基本思路是CNN與RNN結合:CNN被用于提取有表征能力的圖像特征,而RNN天然適合處理序列問題,學習上下文關系。這種CNN+RNN的混合網絡從本質上革新了文本串識別領域的研究。
CRNN:CNN+RNN+CTC
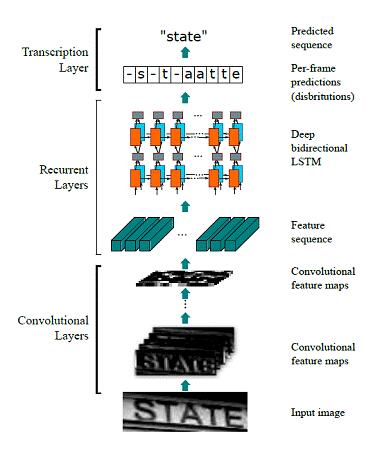
圖4:CRNN實現端到端的文本串識別
CRNN目前在串識別領域非常成功的模型。在我們之前的文章中也對其進行過介紹【2】。模型前面的CNN部分,將圖像進行空間上的保序壓縮,相當于沿水平方向形成若干切片,每個切片對應一個特征向量。由于卷積的感受野會相互重疊,這類特征本身就包含了一定的上下文關系。接下來的RNN部分,采用雙層雙向的LSTM,進一步學習上下文特征,據此得到切片對應的字符類別。***的CTC層設計了一種結構化損失,通過引入空白類和映射法則模擬了動態規劃的過程。CRNN在圖像特征和識別內容序列之間是嚴格保序的,極其擅長識別字分割比較困難的文字序列,甚至包括潦草的手寫電話號碼。此外,這一序列學習模型還使得訓練數據的標注難度大為降低,便于收集更大規模的訓練數據。
EDA:Encoder+Decoder+attention model
文本串識別另一種常用的網絡模型為編碼-解碼模型(Encoder-Decoder),并加入了注意力模型(Attention model)來幫助特征對齊,故簡稱EDA。其方法流程如圖所示:
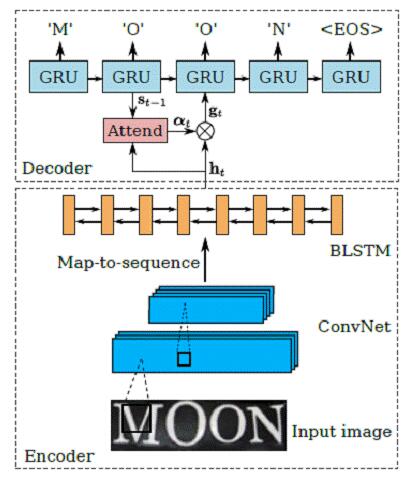
圖4:EDA實現端到端的文本串識別
Encoder-Decoder模型從提出伊始就是為了解決seq2seq問題。即根據一個輸入序列x,來生成另一個輸出序列y。這里的編碼,就是將輸入序列轉化成一個固定長度的向量;解碼,就是將之前生成的固定向量再轉化成輸出序列。Encoder-Decoder模型雖然非常經典,但是局限性也很大:編碼和解碼之間的唯一聯系就是一個固定長度的語義向量C。也就是說,編碼器要將整個序列的信息壓縮進一個固定長度的向量中去。這種強壓縮導致語義向量無法完全表示整個序列的信息,且先輸入的內容攜帶的信息會被后輸入的信息稀釋。輸入序列越長,這個現象就越嚴重。
Attention模型旨在解決這個問題:在產生當前輸出同時,還會產生一個“注意力范圍”表示接下來輸出的時候要重點關注輸入序列中的哪些部分,然后根據關注的區域來產生下一個輸出,如此往復。這樣,解碼不再依賴一個中間向量,而是由注意力模型對所有編碼特征進行加權調整后得到的特征向量。Attention模型實現了一個軟對齊(soft align)的功能,同時也使得輸入向量和輸出向量不再是嚴格保序的。后面會提到這對于文本串識別的影響。
值得一提的是,今年5月,Google發布了Attention OCR方法,用于端到端的自然場景文本識別。該方法在EDA的基礎上,將輸入擴展到全圖(如圖5所示)。因此,該方法理論上可以實現任意包含文字的圖片到文字內容的映射,不僅不需要文字切分,連文本檢測步驟也不需要了(聽起來是不是很酷)。該算法在French Street Name Signs(FSNS)數據集(一個法國街道路標數據集,包含約100w街道名稱)中達到了 84.2% 的準確率。
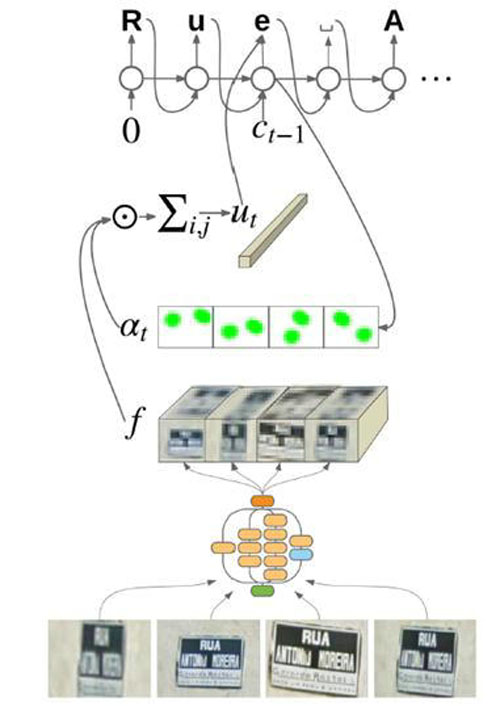
圖5:谷歌的Attention OCR實現端到端的文字檢測識別
從流程圖中可以看到,該網絡輸入為同一標志牌的四張不同角度拍攝的圖像,經過Inception-V3網絡(CNN的一種)對圖像編碼后形成特征圖,然后根據注意力模型給出的權重對不同位置的特征加權作為解碼模型的輸入。為了突出位置信息,這里采用了location aware attention,即位置相關的注意力模型。從文章給出的注意力模型可視化結果可以看出,該模型的確可以在一定程度上預測文字出現的位置。
該方法可以同時對語言和圖像序列建模,可以適應大小、位置分布不均勻的文字排版,不需要標注文本框的位置,真正實現了端到端的文字檢測識別。
實踐中,我們利用公開的FSNS數據集復現該論文的結果。但也發現該方法的一些局限性:1.由于注意力模型的軟對齊機制,可能出現識別結果字符內容亂序;2.因RNN記憶功能限制,不適用于文字內容較多的圖片;3.由于輸入圖像中包含較多背景干擾,僅當文字內容和樣式比較單一的情況下效果可靠。
本文主要對于深度序列學習在OCR中的應用進行了綜述總結,接下來將主要介紹這類技術在微信產品中的落地情況。
原文鏈接:http://t.cn/R0w2hAP
作者:麻文華
【本文是51CTO專欄作者“騰訊云技術社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】