6倍性能差100TB容量,阿里云POLARDB如何實現?
一、 POLARDB產品架構簡介
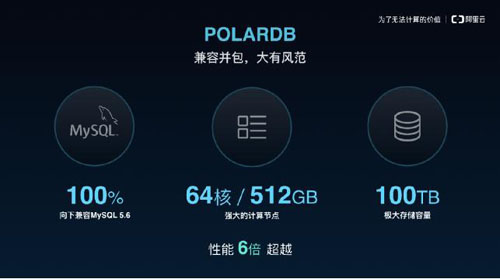
POLARDB是阿里云數據庫團隊研發的基于第三代云計算架構下的商用關系型云數據庫產品,實現100%向下兼容MySQL 5.6的同時,支持單庫容量擴展至上百TB以及計算引擎能力及存儲能力的秒級擴展能力,對比MySQL有6倍性能提升及相對于商業數據庫實現大幅度降低成本。
第三代分布式共享存儲架構究竟有什么優勢?

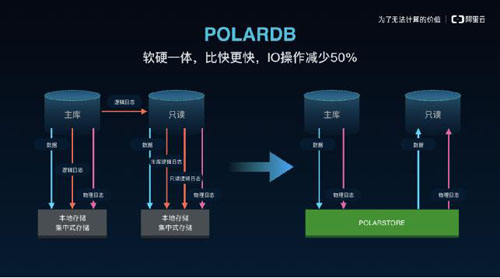
圖為POLARDB的第三代分布式共享存儲架構
首先,受益于第三代分布式共享存儲架構,使POLARDB實現了計算節點(主要做SQL解析以及存儲引擎計算的服務器)與存儲節點(主要做數據塊存儲,數據庫快照的服務器)的分離,提供了即時生效的可擴展能力和運維能力。
眾所周知,在傳統數據庫上做擴容、備份和遷移等操作,花費的時間和數據庫的容量成正比,往往上TB的數據庫容量加個只讀副本就需要一到兩天時間。POLARDB的存儲容量可以實現無縫擴展,不管數據量有多大,2分鐘內即可實現只讀副本擴容,1分鐘內即可實現全量備份,為企業的快速業務發展提供了彈性擴展能力。
其次,與傳統云數據庫一個實例一份數據拷貝不同,POLARDB同一個實例的所有節點(包括讀寫節點和只讀節點)都實現訪問存儲節點上的同一份數據,使得POLARDB的數據備份耗時實現秒級響應。(備份時間與底層數據量無關)
***,借助優秀的RDMA網絡以及***的塊存儲技術,實現服務器宕機后無需搬運數據重啟進程即可服務,滿足了互聯網環境下企業對數據庫服務器高可用的需求。
二、 為什么POLARDB能做到6倍于MySQL的性能?
這里我們將分別以存儲性能、計算性能來進行解讀詮釋。

圖為阿里云POLARDB性能全景
1. POLARDB的存儲引擎性能優化
- 持續釋放硬件紅利
眾所周知,關系型數據庫是IO密集型的應用,IO性能的提高對數據庫的性能提升至關重要。過去十年我們看到在數據庫領域,SSD替換HDD的過程給數據庫數據處理的吞吐能力帶來了數量級的提升。
POLARDB采用了領先的硬件技術:包括使用3DXpoint存儲介質的Optane存儲卡、NVMe SSD和RoCE RDMA網絡。同時面向新硬件架構實現軟硬一體優化:從數據庫、文件系統到網絡通訊協議、分布式存儲系統和設備驅動,POLARDB實現縱貫軟件棧各層次的整個IO鏈條的深度優化。
為了將3DXpoint顆粒的高性能和3D NAND顆粒的低成本結合起來,POLARDB創新的在軟件層實現對高速的Optane卡和大容量高吞吐的NVMe SSD進行組合,實現一個名為混合存儲層。既保證數據寫入的低延遲、高吞吐、高QoS,又使整體方案兼具較高的性價比。

- 旁路內核,榨干硬件能力
在POLARDB里,為了追求更高的性能、更低的延遲,阿里云數據庫團隊大膽的拋棄了Linux內核提供的各種機制,比如塊設備、各種文件系統例如ext4,以及TCP/IP協議棧和socket編程接口而選擇了另起爐灶。最終,POLARDB實現了一整套在用戶態運行的IO和網絡協議棧。
POLARDB用戶態協議棧解決了內核IO協議棧慢的問題。用戶程序在用戶態直接通過DMA操作硬件設備,通過輪詢的方式監聽硬件設備完成IO事件,消除了上下文切換和中斷的開銷。用戶程序還可以將IO處理線程和cpu進行一一映射,每個IO處理線程獨占CPU,相互之間處理不同的IO請求,綁定不同的IO設備硬件隊列,一個IO請求生命周期從頭到尾都在一個線程一顆CPU上處理,不需要鎖進行互斥。這種技術實現***化的和高速設備進行性能交互,實現一顆CPU達每秒約20萬次IO處理的能力,并且保持線性的擴展能力,也就意味著4顆CPU可以達到每秒80萬次IO處理的能力,在性能和經濟型上遠高于內核。
網絡也是類似的情況。過去傳統的以太網,網卡發一個報文到另一臺機器,中間通過一跳交換機,大概需要一百到兩百微秒。POLARDB支持ROCE以太網,應用程序通過RDMA網絡,直接將本機的內存寫入另一臺機器的內存地址,或者從另一臺機器的內存讀一塊數據到本機,中間的通訊協議編解碼、重傳機制都由RDMA網卡來完成,不需要CPU參與,使性能獲得極大提升,傳輸一個4k大小報文只需要6、7微秒的時間。如同內核的IO協議棧跟不上高速存儲設備能力,再一次的,內核的TCP/IP協議棧跟不上高速網絡設備能力,被POLARDB的用戶態網絡協議棧代替。
- 硬件DMA和物理復制實現的數據庫多副本
大家都知道關系型數據庫的重要特性歸納起來是“ACID”,其中A是原子性,C是約束,I是隔離性,D是持久性。
POLARDB將從兩個維度出發,從根本上改進多副本復制。一個是保證數據庫ACID中的D(Durable),把網絡、存儲硬件提供的DMA能力串起,用硬件通道高性能的把主庫的日志數據持久化到三個存儲節點的磁盤中;另一個是實現了高效的只讀節點,在主庫和只讀節點之間通過物理復制同步數據,直接更新到只讀節點的內存里。 如何實現?
POLARDB實現日志數據持久化到三個存儲節點的磁盤中。主庫通過RDMA將日志數據發送到存儲節點的內存中,存儲節點之間再通過RDMA互相復制,每個存儲節點用SPDK將數據寫入NVMe接口的存儲介質里,整個過程CPU不用訪問被同步的數據塊(Payload),實現數據零拷貝。
同時由RDMA網卡和NVMe控制器完成數據傳輸和持久化,CPU僅做狀態機的維護,在一致性協議的協調下,把網卡和存儲卡兩塊硬件串起來,存儲節點之間數據同步采用并發Raft(Parallel Raft)協議,和Raft協議一樣,決議在leader節點上是串行生成和提交的,但并發Raft協議可以允許主從之間亂序同步,簡單的說,允許follower節點在漏掉若干條日志的情況先commit并apply后面過來的日志,并異步的去補之前漏掉的日志,數據同步的性能和穩定性都顯著優于Raft協議。
POLARDB在主庫和只讀實例之間的數據流上,放棄了基于binlog的邏輯復制,而是基于innodb的redolog實現了物理復制,從邏輯復制到物理復制對主庫和從庫性能帶來的提升都非常明顯。
在主庫上,原本引擎需要和binlog做XA事務,事務要等到binlog和redolog同時寫盤后才能返回,去掉binlog后,XA事務可以去掉,事務的執行路徑更短,IO開銷也更小。在從庫上,redolog由于是物理復制,僅需比對頁面的LSN就可以決定是否回放,天然可以多線程執行,數據的正確性也更有保證,此外,POLARDB的從庫收到redolog后只需要更新緩存里的頁面,并不需要寫盤和IO操作,開銷遠低于傳統多副本復制里的從庫。
- 針對數據庫加速的Smart Storage
POLARDB的存儲節點針對數據庫的IO workload進行了一些針對性的優化。
IO優先級優化:POLARDB在文件系統和存儲節點兩層都開了綠色通道,對redolog文件的更新進行優待處理,減少排隊,提高IO的優先級。redolog也從512對齊調整為4k對齊,對SSD性能更加友好。
double write優化:POLARDB存儲節點原生支持1MB的原子寫,因此可以安全關閉double write,從而節省了近一倍的IO開銷。
group commit優化:POLARDB里一次group commit可以產生寫入幾百KB的單個大IO。對于單個SSD,延遲和IO的大小是呈線性的,而POLARDB從文件系統到存儲節點都進行一系列優化來保證這種類型的IO能盡快刷下去,針對redolog文件進行條帶化,將一個上百KB的大IO切割為一批16KB的較小IO,分發到多個存儲節點和不同的磁盤上去執行,進一步的降低關鍵IO路徑的延遲。
2. POLARDB的計算引擎性能優化
- 使用共享存儲物理復制
由于POLARDB使用共享存儲和物理復制,實例的備份恢復也做到完全依賴redolog,因此去掉了binlog。使得單個事務對io的消耗減少,有效減少語句響應時間,提升吞吐量。同時避免了引擎需要與binlog做的XA事務邏輯,事務語句的執行路徑更短。
- 鎖優化
POLARDB針對高并發場景,對引擎內部鎖做了大量優化,比如把latch分解成粒度更小的鎖,或者把latch改成引用計數的方式從而避免鎖競爭,例如Undo segment mutex, log system mutex等等。PolarDB還把部分熱點的數據結構改成了Lock Free的結構,例如Server層的MDL鎖。
- 日志提交優化
Redolog的順序寫性能對數據庫性能的影響很大,為了減少Redolog切換時對性能的影響,我們后臺采用類似Fallocate的方式預先分配日志文件,此外,現代的SSD硬盤很多都是4K對齊,而MySQL代碼還是按照早期磁盤512字節對齊的方式刷日志的,這樣會導致磁盤做很多不必要的讀操作,不能發揮出SSD盤的性能,我們在這方面也做了優化。我們對日志提交時Group Commit進行優化,同時采用Double RedoLog Buffer提升并行度。
- 復制性能
POLARDB中物理復制的性能至關重要,我們不僅通過基于數據頁維度的并行提高了性能,還對復制中的必要流程進行了優化,例如在MTR日志中增加了一個長度字段,從而減少了日志Parse階段的CPU開銷,這個簡單的優化就能減少60%的日志Parse時間。我們還通過復用Dummy Index的內存數據結構,減少了其在Malloc/Free上的開銷,進一步提高復制性能。
- 讀節點性能
POLARDB的Replica節點,日志目前是一批一批應用的,因此當新的一批日志被應用之前,Replica上的讀請求不需要重復創建新的ReadView,可以使用上次緩存下來的。這個優化也能提高Replica上的讀性能。
三、 為什么POLARDB能做到遠低于商業數據庫的成本
- 存儲資源池化
POLARDB采用了一種計算和存儲分離的架構,DB運行在計算節點,計算節點組成了一個計算資源池,數據都放在存儲節點上,存儲節點組成了一個存儲資源池。如果CPU和內存不夠了,就擴充計算資源池,如果容量或者IOPS不夠了,就擴充存儲資源池,兩個池子都是按需擴容。而且存儲節點和計算節點可以分別向兩個方向優化,存儲節點會選擇低配的CPU和內存,提高存儲密度,而計算節點可以選擇小容量、低配的SSD作為操作系統和日志盤,上多路服務器增加CPU的核數。
而傳統的數據庫部署模型則是一種煙囪模型,一臺主機既跑數據庫又存數據,這帶來兩個問題。一個是機型難以選擇,CPU和磁盤的配比主要取決于實際業務的需求,很難提前找到***比例。第二是磁盤碎片問題,一個生產集群里,總有部分機器磁盤使用率是很低的,有的還不到10%,但出于業務穩定性要求,會要求獨占主機的CPU,這些機器上的SSD其實是被浪費的。通過存儲資源池化,這兩個問題都能得到解決,SSD的利用率得到提高,成本自然也降低下來。
- 透明壓縮
POLARDB的存儲節點除了對ibd文件提供1MB的原子寫,消除double write的開銷,還支持對ibd文件的數據塊進行透明壓縮,壓縮率可以達到2.4倍,進一步降低了存儲成本。
而傳統數據庫在DB內進行壓縮的方案相比,存儲節點實現透明壓縮不消耗計算節點的CPU,不影響DB的性能,利用QAT卡進行加速,以及在IO路徑上用FPGA進行加速。POLARDB的存儲節點還支持快照去重(dedup)功能,數據庫的相鄰快照之間,如果頁面沒有發生修改,會鏈接到同一份只讀頁面上,物理上只會存儲一份。
- 0存儲成本的只讀實例
傳統數據庫做只讀實例,實施一寫多讀方案,是通過搭建只讀副本的方案,先拷貝一個最近的全量備份恢復一個臨時實例,再讓這個臨時實例連接主庫或者其他binlog源同步增量數據,增量追上后,把這個臨時實例加到線上升級為一個只讀副本。這種方法一個是耗時,搭建一個只讀實例需要的時間與數據量成正比;另一方面也很昂貴,需要增加一份存儲成本,比如用戶購買一個主實例加上五個只讀實例,需要付7~8份存儲的錢(7份還是8份取決于主實例是兩副本還是三副本)。
而在PolarDB架構中,這兩個問題都得到解決,一方面新增只讀實例不需要拷貝數據,不管數據量有多大都可以在2分鐘內創建出來;另一方面,主實例和只讀實例共享同一份存儲資源,通過這種架構去增加只讀副本,可以做到零新增存儲成本,用戶只需要支付只讀實例消耗的CPU和內存的費用。
POLARDB是未來云數據庫的雛形(All in one),一個數據庫即可滿足現時多類數據庫混合使用效果。阿里云發揮自身自研能力優勢,以POLARDB為產品契機,實現數據庫OLTP與OLAP的一體化設計,為企業的數字化升級所需的IT設施架構實現革命性進化。