頭條面試官問:100TB文件上傳該怎么優化性能?

一、寫在前面
上一篇文章,我們聊了一下Hadoop中的NameNode里的edits log寫機制。
主要分析了edits log寫入磁盤和網絡的時候,是如何通過分段加鎖以及雙緩沖的機制,大幅度提升了多線程并發寫edits log的吞吐量,從而支持高并發的訪問。
如果沒看那篇文章的同學,可以回看一下:??放幾十億數據的系統還能抗每秒上萬并發,牛不牛???
這篇文章,我們來看看,Hadoop的HDFS分布式文件系統的文件上傳的性能優化。
首先,我們還是通過一張圖來回顧一下文件上傳的大概的原理。
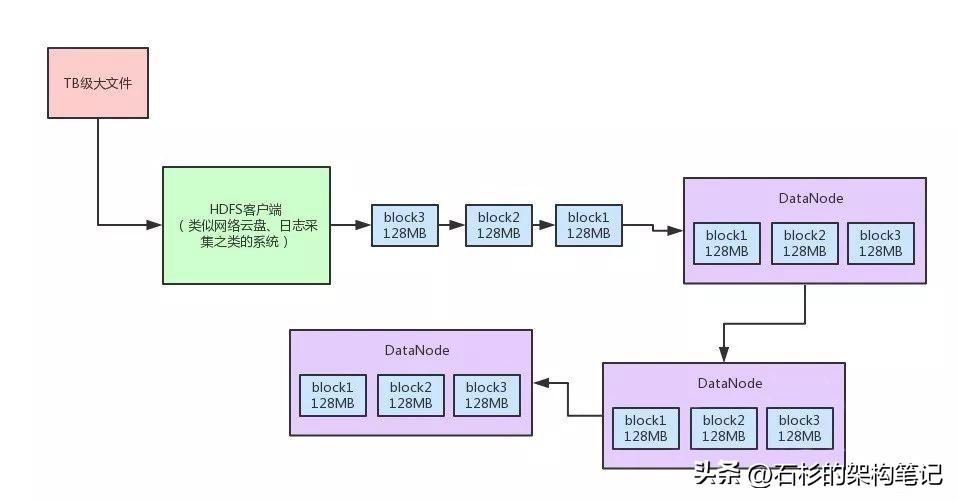
?由上圖所示,文件上傳的原理,其實說出來也簡單。
比如有個TB級的大文件,太大了,HDFS客戶端會給拆成很多block,一個block就是128MB。
這個HDFS客戶端你可以理解為是云盤系統、日志采集系統之類的東西。
比如有人上傳一個1TB的大文件到網盤,或者是上傳個1TB的大日志文件。
然后,HDFS客戶端把一個一個的block上傳到第一個DataNode
第一個DataNode會把這個block復制一份,做一個副本發送給第二個DataNode。
第二個DataNode發送一個block副本到第三個DataNode。
所以你會發現,一個block有3個副本,分布在三臺機器上。任何一臺機器宕機,數據是不會丟失的。
最后,一個TB級大文件就被拆散成了N多個MB級的小文件存放在很多臺機器上了,這不就是分布式存儲么??
二、原始的文件上傳方案
今天要討論的問題,就是那個HDFS客戶端上傳TB級大文件的時候,到底是怎么上傳呢?
我們先來考慮一下,如果用一個比較原始的方式來上傳,應該怎么做?
大概能想到的是下面這個圖里的樣子。
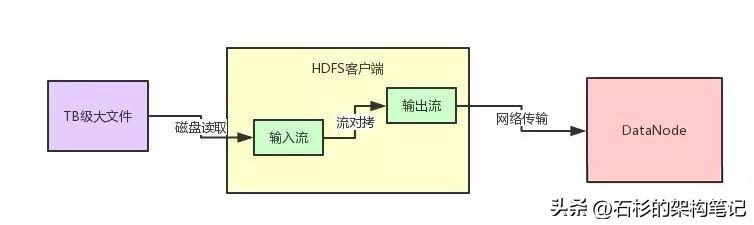
很多java的初學者,估計都知道這樣來上傳文件,其實無非就是不停的從本地磁盤文件用輸入流讀取數據,讀到一點,就立馬通過網絡的輸出流寫到DataNode里去。
上面這種流程圖的代碼,估計剛畢業的同學都可以立馬寫出來。因為對文件的輸入流最多就是個FileInputStream。
?而對DataNode的輸出流,最多就是個Socket返回的OutputStream。
然后中間找一個小的內存byte[]數組,進行流對拷就行了,從本地文件讀一點數據,就給DataNode發一點數據。
但是如果你要這么弄,那性能真是極其的低下了,網絡通信講究的是適當頻率,每次batch批量發送,你得讀一大批數據,通過網絡通信發一批數據。
不能說讀一點點數據,就立馬來一次網絡通信,就發出去這一點點的數據。
如果按照上面這種原始的方式,絕對會導致網絡通信效率極其低下,大文件上傳性能很差。
為什么這么說呢?
相當于你可能剛讀出來幾百個字節的數據,立馬就寫網絡,卡頓個比如幾百毫秒。
然后再讀下一批幾百個字節的數據,再寫網絡卡頓個幾百毫秒,這個性能很差,在工業級的大規模分布式系統中,是無法容忍的。?
三、HDFS對大文件上傳的性能優化
好,看完了原始的文件上傳,那么我們來看看,Hadoop中的大文件上傳是如何優化性能的呢?一起來看看下面那張圖。
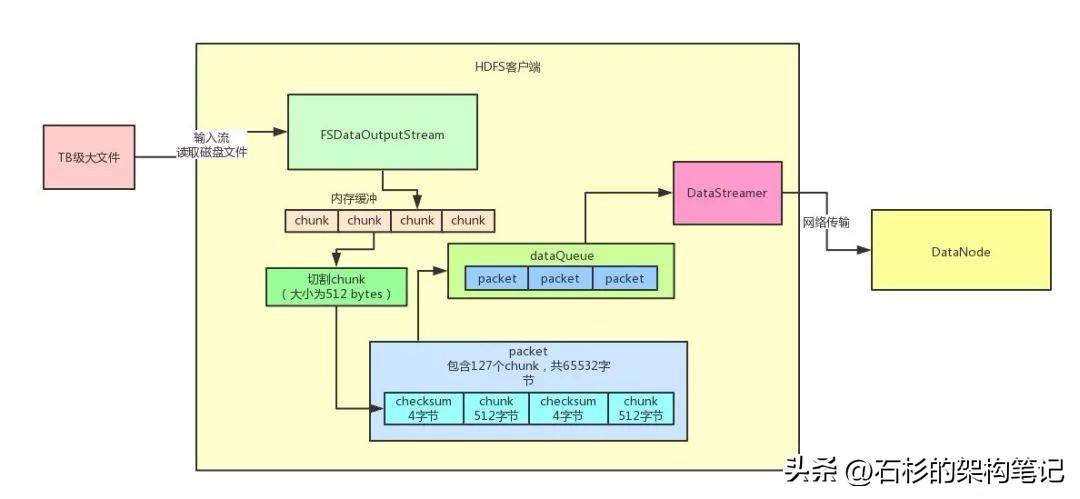
首先你需要自己創建一個針對本地TB級磁盤文件的輸入流。
然后讀到數據之后立馬寫入HDFS提供的FSDataOutputStream輸出流。
這個FSDataOutputStream輸出流在干啥?
大家覺得他會天真的立馬把數據通過網絡傳輸寫給DataNode嗎?
答案當然是否定的了!這么干的話,不就跟之前的那種方式一樣了!
1、 Chunk緩沖機制
首先,數據會被寫入一個chunk緩沖數組,這個chunk是一個512字節大小的數據片段,你可以這么來理解。
然后這個緩沖數組可以容納多個chunk大小的數據在里面緩沖。
光是這個緩沖,首先就可以讓客戶端快速的寫入數據了,不至于說幾百字節就要進行一次網絡傳輸,想一想,是不是這樣?
2、 Packet數據包機制
接著,當chunk緩沖數組都寫滿了之后,就會把這個chunk緩沖數組進行一下chunk切割,切割為一個一個的chunk,一個chunk是一個數據片段。
然后多個chunk會直接一次性寫入另外一個內存緩沖數據結構,就是Packet數據包。
一個Packet數據包,設計為可以容納127個chunk,大小大致為64mb。所以說大量的chunk會不斷的寫入Packet數據包的內存緩沖中。
通過這個Packet數據包機制的設計,又可以在內存中容納大量的數據,進一步避免了頻繁的網絡傳輸影響性能。
3、內存隊列異步發送機制
當一個Packet被塞滿了chunk之后,就會將這個Packet放入一個內存隊列來進行排隊。
然后有一個DataStreamer線程會不斷的獲取隊列中的Packet數據包,通過網絡傳輸直接寫一個Packet數據包給DataNode。
如果一個Block默認是128mb的話,那么一個Block默認會對應兩個Packet數據包,每個Packet數據包是64MB。
也就是說,傳送兩個Packet數據包給DataNode之后,就會發一個通知說,一個Block的數據都傳輸完畢。
這樣DataNode就知道自己收到一個Block了,里面包含了人家發送過來的兩個Packet數據包。
四、總結
OK,大家看完了上面的那個圖以及Hadoop采取的大文件上傳機制,是不是感覺設計的很巧妙?
說白了,工業級的大規模分布式系統,都不會采取特別簡單的代碼和模式,那樣性能很低下。
這里都有大量的并發優化、網絡IO優化、內存優化、磁盤讀寫優化的架構設計、生產方案在里面。
所以大家觀察上面那個圖,HDFS客戶端可以快速的將tb級大文件的數據讀出來,然后快速的交給HDFS的輸出流寫入內存。
?基于內存里的chunk緩沖機制、packet數據包機制、內存隊列異步發送機制。絕對不會有任何網絡傳輸的卡頓,導致大文件的上傳速度變慢。
反而通過上述幾種機制,可以上百倍的提升一個TB級大文件的上傳性能。?