從人肉運維到智能運維,京東金融服務監控的進階之路
原創【51CTO.com原創稿件】人肉階段的運維,理想與現實有天壤之別,同時還有背不完的鍋,填不完的坑。人工、自動、智能運維相互交疊是當前運維領域的現狀,智能運維是大勢所趨,但真正的落地實踐并不多。
在由 51CTO 主辦的第十四期“Tech Neo”技術沙龍活動中,資深架構師沈建林分享了京東金融的服務監控、服務治理等方面的應用與技術實現。
為什么要做服務監控?
業務規模不斷擴大、微服務化、頻繁變更這三方面現實需求,是做服務治理和監控的重要原因。為保證這三方面的正常進行,需要做很多事,重點包括如下幾點:
- 如何快速發現問題?采用哪些技術?
- 如何梳理服務依賴?面對京東過萬的服務,如何進行梳理,具體實現過程是怎么樣的?
- 如何判斷依賴合理性?微服務之間相互依賴,采用什么樣方式判斷依賴是否合理?
- 如何實現實時容量規劃?傳統的方式是在618前兩月進行封網,不允許上線,利用這段時間進行線上壓測,得到應用的容量,隨后根據現實情況進行擴容。這樣的方式耗時耗力,所有研發不讓上線,成本很難評估。現在的做法是基于歷史數據,機器學習,自動運算,那具體是如何實現的?
- 如何判斷故障影響范圍?也就是故障定位問題,如何能知道哪個節點發生故障,響應了哪些業務?
- 如何實現業務級監控?京東金融會和很多第三方支付機構打交道,如何去監控和合作伙伴之間交易的服務質量?
綜上都是服務監控要完成的使命,下面我們先從服務監控設計原則、自主監控的基本要素、服務依賴關系梳理、調用鏈分析、容量規劃、根源分析等方面來看看服務監控的應用。
服務監控的應用實踐
服務監控設計原則
服務監控與治理軟件的設計原則主要有五個方面,分別是微內核、樂觀策略、零侵入、約定大于配置、動態路由。
- 微內核。設計產品時把內核設計的非常小,稱之為微內核。采用Plugin模式,所有功能采用微內核方式,把自己也當做第三方去擴展,這樣的產品,不管是開源或商用,別人擴展時也會更加便捷。
- 樂觀策略。不能因為監控影響業務,一旦影響業務采用拋棄策略,監控項要全部異步處理。通過SoftReference(軟引用)的方式,在內存吃緊的時候優先釋放掉監控本身所占用的內存。
- 零侵入。簡化研發使用,實現業務、中間件、監控完全獨立。
- 約定大于配置。自動發現:部署規范,配置規范默認返回碼、描述。
- 動態路由。日志傳輸節點遠程控制,***擴容。
自主監控三劍客
做自主監控有三個最基本要素,分別是調用量、性能、成功率。后期的一些監控擴展,都是基于這三個指標。如下圖,是監控的細節:

如圖中所示,紅顏色的線條被稱之基線,通過波動可知當前這個服務的響應時間、調用量、成功率等情況。基線計算很復雜,基于以前歷史數據,利用異常檢測算法,推算當前的量應該是多少。
如下圖,是監控分層的細節展示:

如圖中所示,每一條線都可以下鉆,鉆進去就可看到某個應用里有哪些類正在被監控,進一步下鉆可以看到方法、IP級別。當出現某一臺服務器故障,影響整個響應時間時,從IP級別的圖中就可以快速定位,看到是哪個IP出現了問題。
服務依賴關系梳理
分享服務梳理方法之前,先來了解兩個概念:依賴強度和依賴頻度。
- 依賴強度指服務之間的依賴關系強弱。比如購物必須要交易,交易必須經過支付后才發貨,交易對支付就是強依賴,支付系統出故障,交易也不能幸免。
- 依賴頻度指對某一個服務的調用次數,調用頻繁,就是高頻依賴。
基于這兩個概念,可以進一步對方法、應用和業務線之間的依賴關系進行分析,如下是某場景依賴關系的全拓撲圖:

從圖中,可以很清晰的看到整個調用的拓撲,所有應用相互之間的依賴強度,通過連線之間的數字來描述應用之間的依賴頻度。
如下,是依賴關系的主流程圖:

把弱依賴及依賴頻度較小的應用去掉以后,可以看到主流程,主流就是核心系統,如果出現故障,影響會非常大。
調用鏈分析
如下圖,是調用鏈分析:
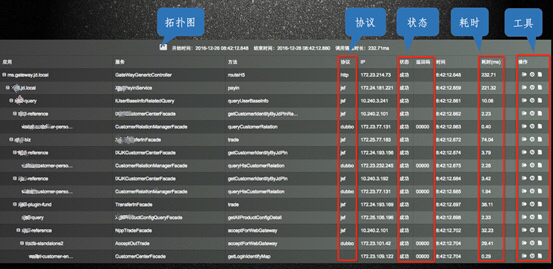
這是整個服務監控中相對重要的環節,當觸發一次請求,如用戶在京東購物,用戶付款這個動作要經過哪些IP來處理,IP上有哪些方法進行處理,通過哪些協議去調用,耗時是多少,每一次調用都要跟蹤,每天有千億以上類似的調用。
整個調用鏈都處于監控中,如出現故障,告警就會通過短信、郵件的方式把鏈接推送給運維人員。運維人員點開鏈接就可知曉故障位置,同時還有一些工具輔助處理問題。
容量規劃
容量規劃方面,傳統的方式是應用上線之前做壓測,但很多時候一上線容量就變了,導致之前設置的數據都是沒有意義了。如下圖,是現在的實時容量規劃方式:

如上圖左側所示,在618,雙11等大促時,把這些拓撲圖實時數據和性能指標都擺放在大屏上,當水位、響應時間等任何一個指標出現異常,運維人員就會及時發現問題,并快速進行問題解決。
如下圖,是服務訪問慢,出現異常的快速定位案例:

當服務訪問慢時,系統會計算到IP上的指標,很多時候是一兩臺服務器過慢,可通過郵件看到是哪個服務器出問題。點開郵件鏈接,就可以看到從什么時間開始慢,什么時間結束,平均的響應時間是否偏高。進一步下鉆,可看到什么樣的問題導致響應時間偏高,這里會引用一些智能故障分析工具。
根源分析
根源分析可基于自動學習的拓撲關系、數據庫與應用的關系、應用與IP的關系等確定性因素來做,如下圖,是一個非常典型的磁盤IO導致日志打印慢的問題。

這樣因一臺機器由于打印日志排隊造成堵塞,導致后面好多應用出現調用性能下降的簡單問題。如果沒有根源分析,要靠人為分析去定位根本原因還是非常困難的。
綜上所述是服務監控的應用,下面我們從日志采集方案對比、分布式服務跟蹤的挑戰、整體技術架構等方面來看看技術實現。
服務監控的技術實現
日志采集方案對比
所有的服務監控是基于一條日志,日志采集方案有很多,如下圖所示,分為四個階段:

最原始的階段,是業務各自監控,自己編寫監控邏輯,業務上埋點,輸出自己的監控日志。
第二階段,是業務與監控耦合,提供公共的監控API,通過API的方式自動產生這條日志。
第三階段,是中間件與監控的耦合,通過中間件埋點方式來產生這條日志。
第四階段,是業務、中間件、監控無耦合,采用APM或流量鏡像分析的方式。流量鏡像分析,是從設備上把流量鏡像下來,分析服務之間的關系,但存在的問題是,流量分析出來的是一個結果,當應用調整或服務依賴發生變化,結果會受到很大影響。APM是目前主流的方式。
分布式服務跟蹤的挑戰
在分布式追蹤上,我們碰到了一些問題,這里主要分享三方面,分別是跨線程、跨協議、擴展性。
- 跨線程。在設計過程中,服務被訪問時,可能會啟動新線程去處理,跨線程去追蹤會有些難度。以Java語言舉例來說,同線程之內,可借助現有ThreadLocal非常方便的去追蹤。如某個服務有一部分代碼邏輯是放在另一個線程上執行的,就要去修改JDK對線程的一些實現邏輯。
- 跨協議。通常情況下,追蹤鏈都很長,一個正常的交易要由很多應用串起來,提供服務。這時就要跨很多協議如RPC、HTTP、JMS、AMQP等去追蹤。
- 擴展性。當新增協議、與其他企業框架不同怎么辦?這需要自定義的擴展性描述語言來解決。
服務監控平臺的整體技術架構
如下圖,是服務監控平臺的整體技術架構:

服務監控平臺的核心是產生日志的Agent,采用Java Bytecode的方式進行自動增強。由統一的Config Server下發監控指令,Agent在應用啟動時或者運行時動態增強需要監控的方法。日志產生后由路和模塊決定發送到哪里,可以是本地磁盤、消息隊列、Collector等。隨后進行流水計算,實時匯聚結果,存入NoSQL,然后由頁面進行展示。
由于篇幅原因,很多內容沒有一一整理,服務監控應用部分:調用來源分析、耗時分析、JVM監控以及針對業務的一系列監控模型,像分類、比值等。服務監控技術實現部分:Agent采集內容、調用鏈擴展方式、自動監控擴展以及一些優化小貼士。欲知更詳盡的內容,請點擊 視頻觀看。
【講師簡介】
曾在多家知名第三方支付公司任職系統架構師,致力于基礎中間件與支付核心平臺的研發,主導過 RPC 服務框架、數據庫分庫分表、統一日志平臺,分布式服務跟蹤、流程編排等一系列中間件的設計與研發,參與過多家支付公司支付核心系統的建設。現任京東金融集團資深架構師,負責基礎開發部基礎中間件的設計和研發工作。擅長基礎中間件設計與開發,關注大型分布式系統、JVM 原理及調優、服務治理與監控等領域。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】