













大數據計數原理1+0=1這你都不會算(五)
Hello哈,又好久沒聊大數據相關的東西了,是不是又忘記了吖?這次聊聊B-樹的升級版,B+樹。前面的內容小伙伴可以回顧一下。
所謂B+樹,跟B-樹主要有這么幾個差別。
1、只有葉子節點會保存數據,根節點和子節點都只把子樹最小的值(或***值)作為索引
2、t階B+樹,除根節點外,每個子節點最多可以保有2t個關鍵字(索引或數據)
3、葉子節點除了數據外,還有衛星數據(比如一些屬性啊什么的)
4、每個葉子節點都有指向下一葉子節點的指針,方便遍歷和range 搜索。
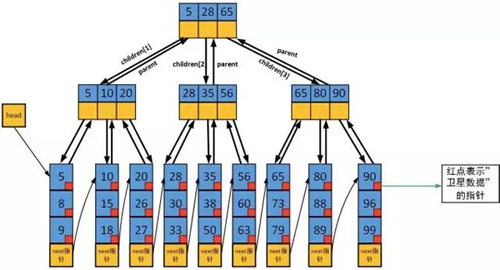
怎么去找到一個數據呢?
從根節點開始搜索,找到其中一個子樹,然后繼續遍歷,直到葉子節點。遍歷葉子節點的所有數據,從而找到對應的數據。若需要附屬數據,則直接拿衛星數據。若需要繼續遍歷這棵樹,則使用next指針進行樹的遍歷。
那現在有哪些成熟的場景在用B+樹呢?
1、數據庫索引。
比如Mysql,Oracle等。
2、文件系統索引。
比如NTFS。
3、搜索引擎索引。
比如Lucene以前用B+,現在用FST(Finite State Transducer)了
ElasticSearch是基于Lucene,也就隨著變了。
那為什么這些場景會使用B+樹呢?跟B-樹比起來又有什么差別?
1、搜索更加穩定。B+樹的一切搜索都需要付出樹的高度那么多的次數來進行遍歷,而B-樹可能快也可能慢。
2、數據存儲更加密集。B+樹的一切數據都存在葉子節點中,不同與B-樹的數據非常分散,所以同一塊硬盤可以比B-樹種存儲的數據更加集中連續,這樣磁盤的手臂就不需要移動太遠。
3、數據附屬有了根基。B+樹的葉子節點有衛星數據,可以用來存放一些不需要被索引但是需要被查詢出來的數據,比如數據庫的整一行數據。
4、樹的遍歷更加方便。B+樹的葉子節點中,有指向下一個葉子節點的指針。與B-樹比較,B-樹在遍歷的時候只能遍歷整棵樹進行多個IO操作,而B+樹只需要順序往下對比即可。因為葉子節點都是有序的,所以作為范圍查找也比較方便。
那問題來了,這跟大數據計數又有什么關系呢?
請參照上一篇B-樹,跟B-樹一樣。都是將數據存儲起來,然后進行搜索,搜索不到就添加到樹中。
下一篇可能理論性比較強了,知識難度跳躍性比較高,小伙伴們做好準備。
【本文為51CTO專欄作者“大蕉”的原創稿件,轉載請通過作者微信公眾號“一名叫大蕉的程序員”獲取授權】
















