全棧必備 敏捷估點
老板常問:“產品什么時候可以上線呢?”
產品經理常問:“完成這些功能需要多長時間呢?”
技術經理常問:”這個模塊要開發多久呢?“
自己常問:“為啥又要delay呢?”
……
所有這些問題,都會指向一件事————研發中的估點。估點是計劃的基礎,不論你關注還是不關注它,它都在那里。估點不是拍腦袋,是一種對事件的客觀描述方式。通過統計學可以讓我們知道,用兩個數字就能夠描述世界——期望和方差。然而,如果沒有歷史數據的話,統計學的技術方法就無法應用。因此,估點既是獲取研發中經驗數據的開始,也貫穿于研發過程的始終。
從零開始——無歷史參考的初始估點
對產品開發時間的估算有多重方式,其中目標分解后對每個子任務的時間估算一般被認為是估點,產品開發時間的估算是由估點后形成的關鍵路徑決定的。對于估算本身而言,如果是基于一種次序性的尺度,而且有把握對等距尺度作出解釋,那么就可以在這種類型的數據上安全地執行推斷性統計分析,從而得到預測的結果。
如果使我們的研發時間估算相對準確,那么估點中的等距尺度是什么呢?
估點的單位
不論是TRIZ還是一般的架構思想,都會考慮以終為始。 對于估點中的等距尺度即估點的時間單位而言,也是如此。
既然要得到一個時間的數值,進一步提高準確度的話,還需要一個置信區間,所以估點應該依據一個相等的時長。就像我們在物理課上做測量那樣,需要一個測量單位。如果單位是米,誤差就可能是米或者更大,如果是厘米,那么誤差就可能是厘米,以此類推。同理,如果估點的單位時長較大,那么整個估算的誤差也會較大,如果估點的單位時長過小,那么操作起來就會比較復雜,就像我們學生時代使用游標卡尺去測量長度那樣。
那么多大的時長是相對合適的呢?
互聯網上有一種說法,“三個月就是一年”,不僅是形容了互聯網的發展速度,而且是符合敏捷開發的思想和實踐的——快速迭代。三個月就是一年,這是一個1:4的關系,一周頂四周用,一天相當于四天,那么兩個小時(Double Hours,DHR)就相當于一天了。因此,對人/天的任務估算可以轉化為對人/DHR的估算,也就是說,估點的單位時長為兩個小時(DHR)是相對合理,而且是可以接受的。
初始估點的方法
作為一個新組建的團隊,如果沒有可測量的歷史數據作為支撐,那么初始估點的方式一般是:
將產品的目標轉化為一個個以兩小時為單位的可開發實現任務。
將產品的目標轉化為以DHR為單位的小任務是一個設計、建模和架構的過程,同樣可以通過敏捷開發的方法來實現。具體地,就是明確我們的Sprint周期,根據需求來定義用戶故事,將用戶故事拆分為一個個以每兩小時為單位的backlog。
估點中兩個主要的難點是:需求的不確定性 和 思維的系統性。
需求的不斷變化是導致估點無效的主要因素,這就要求對需求的邊界有相對明確的定義和細化。軟件估算的準確度取決于對軟件定義的細化程度,必須通過排除可變性來源的方法來實現對需求邊界的界定。 同時,由一個人來估算“有多少”,由另一個人來估算“有多不確定”,這是考慮不確定性影響的一種不錯的方式。
對于思維的系統性是指我們思考問題過程中的盲點,也就是說,有一些我們可能遺漏的東西,可以通過建立一個檢查列表的方式實現,這一列表可以根據自己的團隊來補充完善。筆者曾經遇到過的功能性遺漏包括:
- 安裝程序和構建環境
- 數據轉換和數據遷移的相關工具
- 使用第三方API或者開源軟件所需的集成代碼和選型評估
- 幫助和引導系統
- 部署方式和監控管理
- 與外部系統接口的集成、測試及評估
非功能性需求往往是隱式的,但對于架構而言是必須關注的,筆者曾經遇到遺漏過的非功能性需求約束包括:
- 互操作性,產品所運行的環境與產品之間的相互影響
- 可修改性,這是一個參數化的過程,要求對內容或展現形式的動態修改
- 性能,具體的性能指標是否實現
- 可靠性,結果是否確定,異常是否處理全面等
- 可復用性,這一功能是否可以復用,粒度如何(函數,模塊乃至服務的復用性)等
- 可伸縮性,隨著數據規模或者時間的變化是否可以實現彈性
- 安全性,涉及安全的林林總總,例如SQL注入,跨域攻擊等等
- 抗毀性,是高可用性的一個分支,主要考慮服務可恢復的場景
- 易用性,使用是否容易,不論是涉及用戶交互,還是進程間或進程內的相互調用
其中性能在估點時尤其是項目的初期是一個非常有爭議的話題,那句“過早優化是萬惡之源”實際上是我們對高德納先生的斷章取義,原文大概是這樣的:
我們應該在例如97%的時間里,忘掉小處的效率;
過早優化是萬惡之源。
但我們不應該錯過關鍵的3%中的機會。
實際上,非關鍵路徑上的優化是萬惡之源,問題的核心所在————如何確定我們的代碼是否在關鍵路徑上。不論節省的時間是多少,花費在關鍵路徑上的性能優化都是值得的,也是我們必須要重視的。
估點的簡單示例
舉一個最常見的例子——用戶登陸,如何進行估點呢?
首先,確定這一功能的邊界。這里不用贅述領域驅動開發或者5W1H等其他的設計方法,一個簡單的用戶故事描述可能是這樣的:
作為一個XXX系統的用戶,可以通過在客戶端輸入帳戶信息登陸到XXX系統,看到XXX系統的主頁面。
接著,把這一用戶故事轉換成可以實現的backlog。采用面向接口的方式,把它分割成前后端的設計,那么接口協議的設計可以作為一個backlog。對用戶故事中的對象實體進行分析同樣是一個backlog,用戶是否分類?用戶是否存在不同的類型,這涉及到后臺的數據表設計。客戶端有哪些類型,Android,iOS,還是網頁?不同的客戶端是否具有相同的呈現形式,還是有各自的特點? 帳戶信息指的的是什么?用戶名/密碼? 用戶名是否有規則呢?密碼是否密文傳輸?……
簡化起見,對各種客戶端的登陸實現分別作為一個backlog,后臺的登陸接口實現以及數據表設計作為一個backlog。得到的估點結果是,6個人/DHR。
這就足夠了嗎?
對于功能性需求而言,如果前置條件不足,就需要考慮注冊與登錄的一致性,登錄失敗等異常處理和引導有可能又是一個backlog。如果允許使用第三方帳戶登錄,那又是一個backlog。登錄頁面的引導和幫助,又是一個backlog ……
對于非功能性而言,如果開發者使用的是新的電腦?那么環境的搭建也將是一個backlog。如果需要持續集成,那么Jinkens的搭建及各端構建腳本的編寫同樣至少是一個backlog。考慮性能因素,引入緩存不會少于兩個backlog。對于安全性問題,客戶端在輸入的時候需要規則檢驗,同時要做簡單的防SQL注入,至少是一個backlog。 至于易用性,是否要在客戶端記住用戶名/密碼,在跟換用戶登錄時,如何處理本地的存儲,往往涉及多用戶使用同一終端登錄的問題,至少又一個backlog。 如果一個用戶在多個終端同時登錄,會是一種怎樣的表現呢?這往往用一個新的用戶故事來描述更好。當用戶總量和并發發生變化的時候,在一個怎樣的范圍內,應用的后臺可以足夠適應……
具體的情況還有很多,一個登錄的功能模塊,backlog可以從6個到20多個不等,當產品的定義不能覆蓋我們在技術上的定義要求的時候,我們有責任和義務就估點提出建議和解決方案。
在我們把目標分解為backlog 之后,具體的就是在兩個小時內完成交付了。同樣采用一比四的方式,兩個小時被分為四段————半小時設計,半小時測試代碼,半小時編碼實現,最后半小時是測試和文檔輸出,這不是絕對的,可以交叉,但最好是相對清晰。幸運的是,半小時剛好滿足番茄工作法對時間的要求。
在確定了估點之后,思考不確定性是必要的。例如對這一登錄的示例而言,如果6個DHR是一個最大可能的時間,最樂觀的估計可能是2個DHR,最悲觀的估計是8個DHR,可以通過簡單的經驗公式得到一個估算值:
估算時間=( 樂觀估計 + 可能時間*4 + 悲觀估計)/6
即 (2+6*4 +8)/6= 5.7 DHR,這個數是可以作為一個期望值的。
尤其需要注意的是,對系統架構而言,往往要復雜的多,但是思路和方法是一致的。對整個產品而言,資源的約束和關鍵路徑的組成,對產品開發周期的整體估算是至關重要的。一般地,我們需要使用協同工具來關注資源的約束和關鍵路徑。在自己使用過的協同工具中,筆者認為trello 是非常出色的服務之一,可以對估點進行詳細的記錄和追蹤,同時通過對支持trello 各種插件的使用,可以生成燃盡圖等的數據圖表,從而更有效地了解產品開發過程的真實進度。
多元估點——數據方法的佐證
當進行了三個以上的sprint之后,相等于初步完成了對研發過程中相關數據的采集。這時候,對于新產品的研發估點而言,同樣可以初始估點中的方法,因為將目標轉化成以DHR為時間單位的思路和方法是相同的。同時,通過對歷史數據的計數分析,可以采用統計學中的一些方法進行評估,得到對產品開發時間的另一種估算結果。將使用統計估算的結果與初始估點的估算結果進行比較,可以進一步判斷估點的置信區間,從而提高估點的準確性和可信度。
對歷史數據的提取和采集
對哪些歷史數據進行選取并作為估點的依據呢?同樣存在很多的方法,比較簡單有效的歷史數據就是代碼行數了。盡管代碼行數又著各種各樣的局限,但是以其他數據作為估算的依據可能會更糟糕。
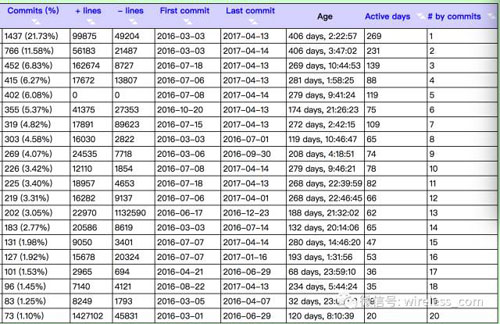
對于存儲代碼的版本管理工具而言,Git 幾乎是大多數開發團隊的首選。在Git的開源社區中有一些可視化的工具如gitk,giggle等,可以用來查看產品的開發歷史。但對于大型的項目,這些簡單的可視化工具就可能不足以了解完整的開發歷史了,因為一些定量的統計數據(如每日提交量,行數等)更能反映開發進程和活躍性。GitStats是筆者推薦的一個好工具,它是一個Git倉庫分析軟件,可以幫助我們查看Git倉庫的狀態,自動生成相關的數據圖表,它所生成的統計數據如下:
- 常規的統計:文件總數,行數,提交量,作者數。
- 活躍度:每天中每小時的、每周中每天的、每周中每小時的、每年中每月的、每年的提交量。
- 所有參與開發的作者數據:列舉所有的開發者(提交數,第一次提交日期,最近一次的提交日期),并按月和年來進行劃分。
- 文件數:支持按日期劃分以及按文件的擴展名來劃分。
以及代碼行數:按日期劃分。
GitStats的下載網址為http://gitstats.sourceforge.net/,也可以從github上獲得:https://github.com/trybeee/GitStats, 這是一個基于Python 的程序,調用git 自身的相關命令獲取數據,使用Gnuplot 作為繪圖工具,最終生成HTML的文件作為輸出結果。
GitStats的使用方法非常簡單,示例如下:
./gitstats /home/abel/git/project ~/gitstats_html/project
Git項目在/home/abel/git/project下,生成的統計數據放在~/gitstats_html/project目錄下。以老曹經歷的一個產品為例,gitstats輸出的常規信息如下:
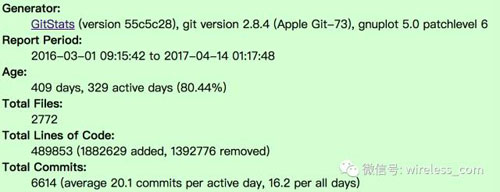
從中可以發現一些有趣的數字,比如增加了1882629行代碼,同時刪除了1392776行代碼。是代碼的重構還是需求變化導致的呢?
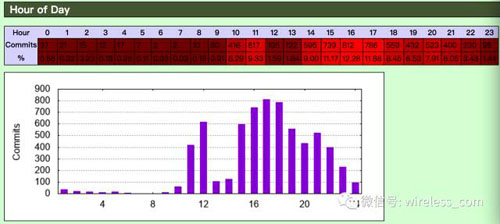
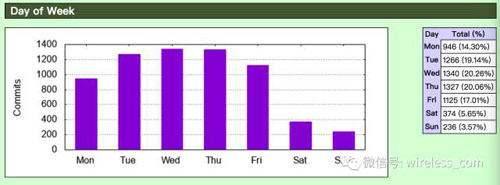
看一看每天中哪個時段或者一周中的哪一天代碼的提交比較頻繁:
還可以看到每個開發者在該產品中的貢獻情況:
基于統計數據的估算
基于統計數據的估算有著一些基本的假設,例如開發人員的開發時間全部應用于某一產品的開發,而不是時分復用,不同產品之間是相對獨立的等等。通過對大目標的估算分解成對小任務的估算,利用大數法則,讓偏大的誤差和偏小的誤差在一定程度上相互抵消。
其中的一個難點和不確定性是backlog與代碼行數之間的對應關系,一個功能的實現采用不同的編程語言代碼量不同,比如通過http 請求獲取一個頁面,Java可能需要30行代碼,而Python可能不超過5行。如果采用相同語言,使用不同的庫導致代碼量同樣會有較大差別。即使采用相同的編程語言和相同的庫,開發人員本身的技能水平同樣會導致代碼量差異。
因此,基于統計數據的估算一般來說是面向開發者個人的,也就是說,首先要保持團隊的相對穩定,然后讓開發者根據自己的數據進行估算比較好,因此,針對同一個業務的開發,不同的開發者建立的backlog 可能是不同的。
如何找到每個backlog對應的代碼量呢?如果使用trello 來跟蹤backlog狀態的話,可以通過trello的開發者API 通過程序來獲得每個backlog的時間段,同時在流程中約定,在每個backlog 的DHR過程中中必須提交代碼,這樣就可以從git倉庫中針對每個開發者的每個backlog進行代碼量的統計了。
至于backlog 之間的相似性,也是以開發者自身的縱向對比為主。因為一個資深的工程師和一個一般水平程序員之間的橫向對比往往不具備可比性,這或許就是所謂“10倍生產率”的一個表現。
舉個簡單的例子,如果工程師A歷史數據中每個backlog的代碼行數平均值為100行,標準差是30行的話,就可以嘗試根據正態分布計算置信區間了。
其他參考模型的估算
當然,這時也可以參考其他常見的軟件估算模型進行多元估點,例如Putnam模型。Putnam是一種動態多變量模型,其中L代表源代碼行數,K代表開發的工作量,Tdev表示開發時間,Ck是技術狀態常數取值因開發環境而定,得到的開發時間估算公式如下:
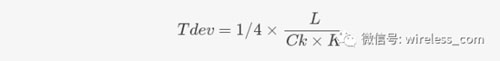
還有比較有名的COCOMO II 模型,在COCOMO II 模型中關于進度的估算公式如下:
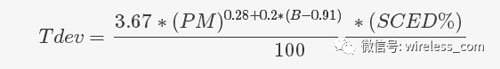
具體解釋參見參考閱讀。
需要注意的是,傳統估算模型都是以人/天,人/月甚至人/年為單位的,我們要轉換成以DHR為單位,那些參數也需要根據自己的歷史數據進行不斷的校準。
這樣,我們就可以嘗試用多元估點的方法對估算的最終結果進行比較和進一步評估了。
處理產品與研發間的估點矛盾
產品經理和研發人員的矛盾主要是開發周期的目標與估點結果之間的矛盾。作為一名研發人員或者技術管理者,在與產品經理或者項目經理進行溝通的時候最好保持以下原則:
- 把人和問題分開,也就是我們提倡的“對事不對人”
- 更關注利益,產品的哪些功能交付可以為團隊乃至公司帶來怎樣的利益,而不是出于不同分工的立場
- 我們是一條繩上的螞蚱,創造可以共同獲利的可行方案
- 堅持使用客觀標準,任何的主觀臆斷都可能會導致相互間誤會的加劇
溝通中的要素
我們要記下估算中包含的假設,并就此進行溝通。同時,明確表達的是估算結果中的不確定性,而不是自己達到承諾的能力的不確定性。不要向其他干系人提供只有很小可能的估算結果,最好以圖形代表文本作為估算值的表達形式。
不要用范圍表示承諾,承諾應該是明確的,也就是說,我們承諾何時可以完成就要在那個時間點必須完成,這是一種職業的態度和操守。可以對承諾進行溝通,但不要對估算值進行談判,讓產品/項目經理了解有效的估算實踐是有意義的,最好讓他們幫助檢查估算中10個問題:
- 是否明確定義了估點目標?
- 是否包括完成任務所需的所有工作類型?
- 是否包含了完成任務所需的所有功能領域?
- 是否被分解到足夠詳細的程度,可以揭示所有隱藏的工作?
- 是否使用來自過去的歷史數據,設定的生產率是否接近于類似工作所達到的生成率?
- 是否被實際要完成開發工作的工程師所認可?
- 是否分別包含了最好情況,最差情況和最可能情況,最差情況是否真的最差?是否還有更差?
- 是否從這些情況中正確的計算出了預期情況?
- 是記錄了估算中的假設?
- 估算做出后是否發生了改變?
除非有定量推算的方法,否則不要提供“百分之多少的置信度”形式的估算值(尤其是“90%置信度”),從個人經驗上看,大部分直覺上的90%置信度實際上相當于30%置信度。
妥協與共贏
謹慎對待進度壓縮和最短的可能進度,因為縮短名義上的進度會增加總工作量。由于可能存在難以突破的或者難以實現的關鍵點,如果我們必須要面對壓縮進度,最好不要讓進度縮短的幅度超過25%。如果縮減團隊規模,使進度變得寬松一些,通常會減少總工作量。也就是說,延長進度并采用較小的團隊,可降低開發的成本。但需要注意的是,讓進度延長超過30%很可能會產生各種低效的情況,反而會增加成本。
最后期限的壓力往往是軟件工程中最危險的敵人。過度緊張的或不合理的進度是對所有產品開發最具破壞力的影響因素。所以,盡量不要故意低估,低估帶來的損失比高估帶來的損失更嚴重。最好通過計劃和控制來解決對高估的顧慮,而不要故意降低估算值。高估帶來的損失往往是線性而且是有限的,但是,低估帶來的損失是非線性增長的而且是沒有限制的,很多時候,更多bug所產生的損害比高估要嚴重的多。
在討論進度的時候,提出盡可能多的可選計劃,為達到開發的目標提供支持。在形成合作式解決問題的氣氛時,千萬不要根據即興估算(拍腦袋)做出任何承諾。也就是說,不要對估算結果本身進行溝通,堅持由有資格的人來進行估算,參考所在開發組的歷史數據和估算方式,經受住理念沖突的考驗。 當遇到僵局的時候,只思考一個問題————“怎樣才對我們的組織/公司最有利” 。
回顧與小結
對軟件開發的估算是對開發持續時間的一種預測,以期望達到產品和業務的目的,進而許諾在特定的日期之前以特定的質量水平交付規定的功能。
估算應該是相對客觀的分析過程,目的是得到相對準確的結果;而規劃與計劃一般是主觀的目標求解過程,目的是尋求一種特定的結果。在傳統的軟件工程中,估算的準確度最高可達±10%,也只有在控制很好的項目中才能達到。估算的首要目標不是預測最終的結果,而是確定目標是否能夠實現,從而在可控的狀態下完成這些目標,無需非常準確而是要有效。良好的估算是對項目實際情況有足夠清晰的看法,讓管理層可以作出可控而且能夠達到目標的決策。
具體地說,以DHR作為初始估算的時間單位,確定目標需求的邊界,進而檢查功能的完備性以及非功能性約束是否遺漏,得到估點的期望值。進一步,以歷史數據為依據,通過統計方法或其他估算模型進行多元估點,對多種估算結果進行比較,可以得到置信區間以及對估算的結果進行糾偏。 最后,與產品/管理團隊溝通協商做出承諾,團結一致,全力做好產品。
【本文來自51CTO專欄作者“老曹”的原創文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】