如何排查MySQL執行死鎖原因

今天碰到一次因死鎖導致更新操作的sql事務執行時間過長,特將排查過程記錄如下:
首先該sql事務的where條件已經命中了主鍵索引,而且表也不大,故可以排除掃表過慢原因。通過 show processlist;發現也只有該sql事務在操作這個表,初看起來似乎也不像是死鎖的原因:

但通過咨詢yellbehuang后發現,判斷sql事務是否死鎖不能簡單通過show processlist來判斷,而是要通過查詢innodb鎖的相關表來確定,和innodb鎖有關的主要有三個表,
- innodb_trx ## 當前運行的所有事務
- innodb_locks ## 當前出現的鎖
- innodb_lock_waits ## 鎖等待的對應關系
上面表的各個字段的含義如下:
- innodb_locks:
- +————-+———————+——+—–+———+——-+
- | Field | Type | Null | Key | Default | Extra |
- +————-+———————+——+—–+———+——-+
- | lock_id | varchar(81) | NO | | | |#鎖ID
- | lock_trx_id | varchar(18) | NO | | | |#擁有鎖的事務ID
- | lock_mode | varchar(32) | NO | | | |#鎖模式
- | lock_type | varchar(32) | NO | | | |#鎖類型
- | lock_table | varchar(1024) | NO | | | |#被鎖的表
- | lock_index | varchar(1024) | YES | | NULL | |#被鎖的索引
- | lock_space | bigint(21) unsigned | YES | | NULL | |#被鎖的表空間號
- | lock_page | bigint(21) unsigned | YES | | NULL | |#被鎖的頁號
- | lock_rec | bigint(21) unsigned | YES | | NULL | |#被鎖的記錄號
- | lock_data | varchar(8192) | YES | | NULL | |#被鎖的數據
- innodb_lock_waits:
- +-------------------+-------------+------+-----+---------+-------+
- | Field | Type | Null | Key | Default | Extra |
- +-------------------+-------------+------+-----+---------+-------+
- | requesting_trx_id | varchar(18) | NO | | | |#請求鎖的事務ID
- | requested_lock_id | varchar(81) | NO | | | |#請求鎖的鎖ID
- | blocking_trx_id | varchar(18) | NO | | | |#當前擁有鎖的事務ID
- | blocking_lock_id | varchar(81) | NO | | | |#當前擁有鎖的鎖ID
- +-------------------+-------------+------+-----+---------+-------+
- innodb_trx :
- +—————————-+———————+——+—–+———————+——-+
- | Field | Type | Null | Key | Extra |
- +—————————-+———————+——+—–+———————+——-+
- | trx_id | varchar(18) | NO | | |#事務ID
- | trx_state | varchar(13) | NO | | |#事務狀態:
- | trx_started | datetime | NO | | |#事務開始時間;
- | trx_requested_lock_id | varchar(81) | YES | | |#innodb_locks.lock_id
- | trx_wait_started | datetime | YES | | |#事務開始等待的時間
- | trx_weight | bigint(21) unsigned | NO | | |#
- | trx_mysql_thread_id | bigint(21) unsigned | NO | | |#事務線程ID
- | trx_query | varchar(1024) | YES | | |#具體SQL語句
- | trx_operation_state | varchar(64) | YES | | |#事務當前操作狀態
- | trx_tables_in_use | bigint(21) unsigned | NO | | |#事務中有多少個表被使用
- | trx_tables_locked | bigint(21) unsigned | NO | | |#事務擁有多少個鎖
- | trx_lock_structs | bigint(21) unsigned | NO | | |#
- | trx_lock_memory_bytes | bigint(21) unsigned | NO | | |#事務鎖住的內存大小(B)
- | trx_rows_locked | bigint(21) unsigned | NO | | |#事務鎖住的行數
- | trx_rows_modified | bigint(21) unsigned | NO | | |#事務更改的行數
- | trx_concurrency_tickets | bigint(21) unsigned | NO | | |#事務并發票數
- | trx_isolation_level | varchar(16) | NO | | |#事務隔離級別
- | trx_unique_checks | int(1) | NO | | |#是否唯一性檢查
- | trx_foreign_key_checks | int(1) | NO | | |#是否外鍵檢查
- | trx_last_foreign_key_error | varchar(256) | YES | | |#最后的外鍵錯誤
- | trx_adaptive_hash_latched | int(1) | NO | | |#
- | trx_adaptive_hash_timeout | bigint(21) unsigned | NO | | |#
可以通過select * from INNODB_LOCKS a inner join INNODB_TRX b on a.lock_trx_id=b.trx_id and trx_mysql_thread_id=線程id 來獲取該sql的鎖狀態,線程id可以通過上面的show processlist來獲得,執行結果如下:
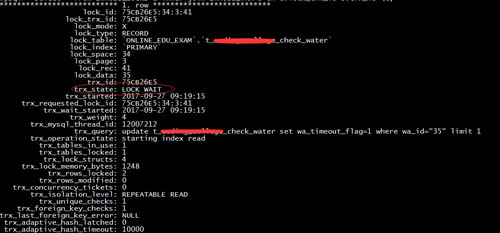
此時發現,該sql連接確實處于LOCK WAIT鎖等待狀態
通過select * from innodb_lock_waits where requesting_trx_id=75CB26E5(即上面查詢得到的lock_trx_id)可以得到當前擁有鎖的事務ID 75CB26AE。
![]()
再通過select * from innodb_trx where lock_trx_id=75CB26AE獲取sql語句與線程id
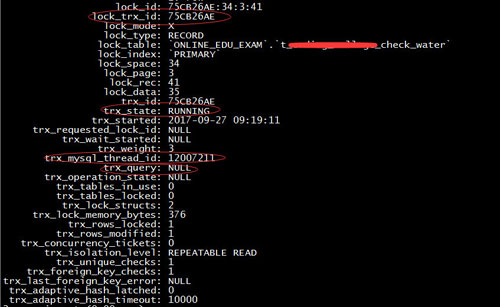
從上面的結果中看出,該事務處于running狀態,但sql卻為null,該線程id即對于上面show processlist的206機器的30764端口的連接,該連接處于sleep狀態。為什么sql為null卻依然占有鎖?在查詢相關資料和咨詢jameszhou后,知道了這個實際和innodb 引擎的寫機制有關,innodb執行寫事務操作時,實際是先取得索引中該行的行鎖(即使該表上沒有任何索引,那么innodb會在后臺創建一個隱藏的聚集主鍵索引),再在緩存里寫入,最后事務commit后正式寫入DB中并釋放鎖。之所以sql為null,是因為該連接已經把sql update操作執行寫入緩存中了,但是由于代碼bug沒有最后commit,導致一直占用著行鎖,后續新的連接想寫這一行數據卻因為一直取不到行鎖而處于長時間的等待狀態。
那為什么innodb需要兩次寫?下面是我查詢相關資料得出來的結論:
因為innodb中的日志是邏輯的,所謂邏輯就是比如當插入一條記錄時,它可能會導致在某一個頁面(這條記錄最終被插入的位置)的多個偏移位置寫入某個長度的值,比如頁頭的記錄數,槽數,頁尾槽數據,頁中的記錄值等等,這些本是一些物理操作,而innodb為了節約日志量及其它一些原因,設計為邏輯處理的方式,那就是它會在一個頁面的基礎上,把一條記錄插入,那么在日志記錄中記錄的內容為表空間號、頁面號、記錄的各個列的值等等,在內部轉換為上面的物理操作。
但這里的一個問題是,如果那個頁面本身是錯誤的,這種錯誤有可能是因為寫斷裂(1個頁面為16K,分多次寫入,后面的有可能沒有寫成功,導致這個頁面不完整)引起的,那么這個邏輯操作就沒辦法完成了,因為它的前提是這個頁面還是正確的,完整的,因為如果這個頁面不正確的話,這個頁面里的數據是無效的,有可能產生各種不可預料的問題。
那么正是因為這個問題,所以必須要首先保證這個頁面是正確的,方法就是兩次寫,它的思想最終是一種備份思想,也就是一種鏡像。
innodb兩次寫的過程:
可以將兩次寫看作是在Innodb表空間內部分配的一個短期的日志文件,這一日志文件包含100個數據頁。Innodb在寫出緩沖區中的數據頁時采用的是一次寫多個頁的方式,這樣多個頁就可以先順序寫入到兩次寫緩沖區并調用fsync()保證這些數據被寫出到磁盤,然后數據頁才被定出到它們實際的存儲位置并再次調用fsync()。故障恢復時Innodb檢查doublewrite緩沖區與數據頁原存儲位置的內容,若數據頁在兩次寫緩沖區中處于不一致狀態將被簡單的丟棄,若在原存儲位置中不一致則從兩次寫緩沖區中還原。
原文鏈接:https://www.qcloud.com/community/article/886137
作者:陳文嘯
【本文是51CTO專欄作者“騰訊云技術社區”的原創稿件,轉載請通過51CTO聯系原作者獲取授權】