













MySQL亂碼問題如何排查
MySQL客戶端和服務器是怎么通信的?
1.首先請求會被MySQL客戶端編碼為字節序列之后通過網絡傳輸到服務器。
對于MySQL自帶的客戶端來說,這個編碼過程使用的字符集和我們使用的操作系統的默認字符集是一樣的,類Unix系統的默認字符集就是utf8,Windows系統的默認字符集就是gbk。
啟動MySQL客戶端時,MySQL客戶端就會檢測到這個操作系統使用的是utf8字符集,并將客戶端默認字符集設置為utf8。如果MySQL不支持自動檢測到的操作系統當前正在使用的字符集,或者在某些情況下不允許自動檢測的話,MySQL會使用它自己的內建的默認字符集作為客戶端默認字符集。這個內建的默認字符集在MySQL 5.7以及之前的版本中是latin1,在MySQL 8.0中修改為了utf8mb4。
如果我們在啟動MySQL客戶端是使用了default-character-set啟動參數,那么客戶端的默認字符集將不再檢測操作系統當前正在使用的字符集,而是直接使用啟動參數default-character-set所指定的值。比方說我們使用如下命令來啟動客戶端:
mysql --default-character-set=utf8那么不論我們使用什么操作系統,操作系統目前使用的字符集是什么,我們都將會以utf8作為MySQL客戶端的默認字符集。
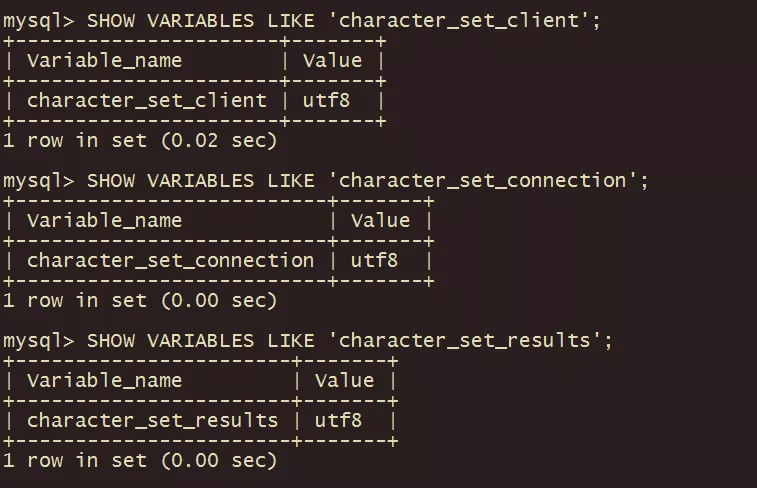
2.服務器收到字節序列請求之后,會認為該字節串是按照character_set_client系統變量編碼的,之后將其從character_set_client轉換到character_set_connection,再進行更深入的處理。
3.最后將響應發送至客戶端時,又會按照character_set_results進行編碼。
4.客戶端收到響應字節串之后,按照本客戶端規定的字符集進行解碼。
對于MySQL自帶的客戶端來說,這個解碼過程使用的字符集和我們使用的操作系統的默認字符集是一樣的,類Unix系統的默認字符集就是utf8,Windows系統的默認字符集就是gbk。
系統變量 | 描述 |
MySQL客戶端字符集 | MySQL客戶端字符集 |
character_set_client | 服務器解碼請求時使用的字符集 (服務器認為請求是按照該系統變量指定的字符集進行編碼的) |
character_set_connection | 服務器處理請求時會把請求字符串從character_set_client轉為character_set_connection |
character_set_results | 服務器向客戶端返回數據時使用的字符集 (服務器采用該系統變量指定的字符集對返回給客戶端的字符串進行編碼) |
從通信轉碼流程來看,要保證沒有亂碼出現:
character_set_client、character_set_connection和character_set_result這三個系統變量應該和客戶端的默認字符集相同即可。
SET names命令可以一次性修改這三個系統變量。
實驗驗證
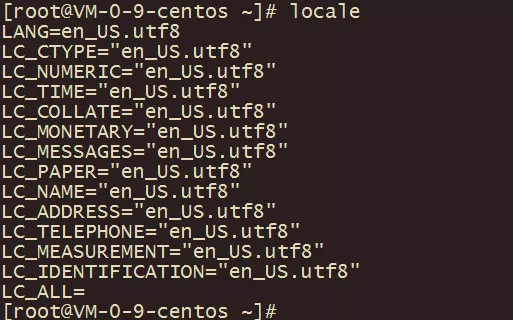
數據庫字符集:
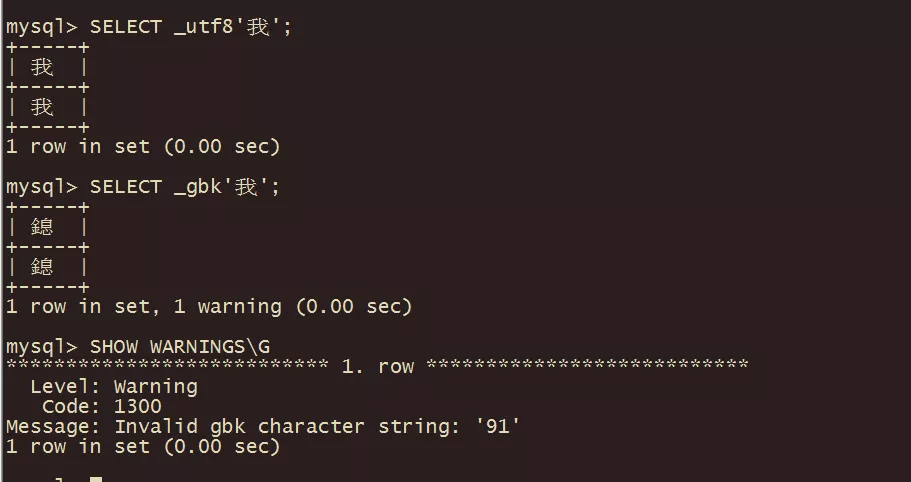
1.客戶端發送請求時會將字符'我'按照utf8進行編碼,也就是:0xE68891。
2.服務器收到請求后發現有前綴_gbk,則不會將其后邊的字節0xE68891進行從character_set_client到character_set_connection的轉換,而是直接把0xE68891認為是某個字符串由gbk編碼后得到的字節序列。
3.再把上述0xE68891從gbk轉換為character_set_results,也就是utf8。0xE688在gbk中代表漢字'鎴',而0x91無法解碼(我們可以看到上述查詢結果中有1個warning)。
結論
解決亂碼問題,要從客戶端到服務器通信流程中的字符集編碼、轉碼、解碼來分析是哪一步的問題。
一般情況下,保證:
- character_set_client
- character_set_results
- character_set_connection
- 客戶端的字符集編碼
當其一致時就可解決亂碼問題。




















