突破存儲跨中心雙活方案設(shè)計階段難點之二:性能影響
存儲跨數(shù)據(jù)中心雙活的方案更是雙活數(shù)據(jù)中心架構(gòu)方案中最重要且最艱難的一項,為了幫助企業(yè)IT架構(gòu)師理清和解決存儲跨中心雙活方案架構(gòu)的難點,twt社區(qū)特別組織線上交流,邀請專家逐一對難點進行解析和解答。
存儲跨中心雙活方案設(shè)計階段如何盡量降低對整體性能的影響?
性能影響問題:因為雙活系統(tǒng)在寫入數(shù)據(jù)時,會寫兩次數(shù)據(jù),尤其是通過復(fù)制功能寫到遠端存儲的過程,傳輸鏈路的性能也會影響整體性能。在選型設(shè)計階段該如何解決該難點?盡量降低對整體性能的影響?
解析和解答
鄧毓 某農(nóng)信社資深骨干工程師
這個問題實際上存儲雙活不可避免要遇到的問題,相比單存儲直接提供讀寫來說,存儲雙活一定會增加讀寫響應(yīng)時間,更別說存儲還是跨兩個不同數(shù)據(jù)中心的,隨著距離的增加,理論上每增加100KM,會增加1ms的RTT(往返延遲時間),通常單個IO總耗時在1-3ms左右,就會認為單個存儲I/O處理處于比較高性能的模式,如果加上其他因素,如“數(shù)據(jù)頭處理”和“并發(fā)”,1ms的“理論”延時增加的影響會成倍增加,將原本處于高性能模式的IO響應(yīng)時間拉高,對應(yīng)用或者數(shù)據(jù)庫來說,“變慢”了。所以存儲雙活的初衷是只是為了高可用性和提高總體并發(fā)、吞吐量,并不是為了降低讀寫響應(yīng)時間。那么我們在設(shè)計、選型存儲雙活方案時,就需要考慮如何盡量降低雙活的存儲所帶來的性能降低影響。
我們先來看看一些存儲雙活方案的讀寫流程:
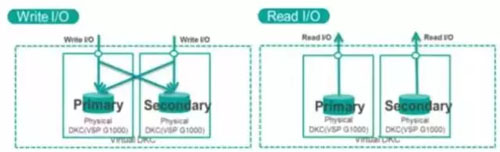
(1)IBM SVC Enhanced Stretch Cluster(ESC)和HDS GAD等
IBM SVC ESC和HDS GAD的讀寫方式都很類似,這里就放在一起來看。
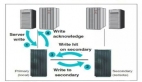
SVC ESC:
HDS GAD:
讀:
ESC和GAD在兩個存儲拉開到兩個數(shù)據(jù)中心,形成AA模式的架構(gòu),對于讀來說,是兩個數(shù)據(jù)中心分別對各自中心的存儲本地讀,這樣讀來說不存在跨站點的RTT,讀性能跟單存儲是一樣的。
寫:
某數(shù)據(jù)中心的寫操作會先寫到本地控制節(jié)點緩存,然后再跨站點同步至另一控制節(jié)點緩存中,并原路返回,告訴主機寫操作完成,等到緩存達到一定的水位時,再刷入各自底層存儲當中,這時的寫操作存在1倍的跨站點RTT。當兩個數(shù)據(jù)中心都要對某一數(shù)據(jù)塊寫操作時,會先在緩存表對應(yīng)的數(shù)據(jù)塊中加鎖,并同步鎖信息至對端緩存表,實現(xiàn)雙活存儲的寫并發(fā)。所以寫也是本地寫的方式,性能跟單存儲比是降低的。
(2)SVC HyperSwap
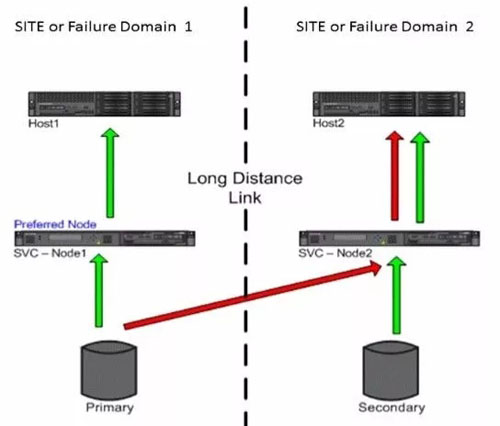
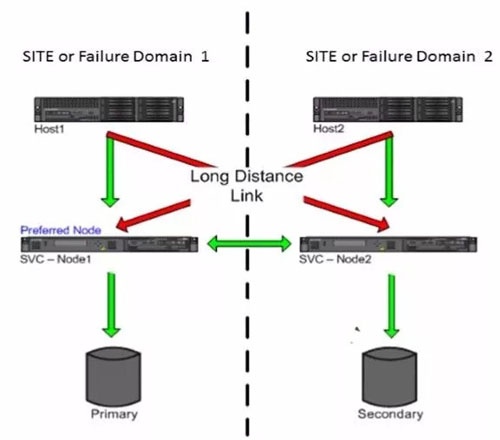
SVC HyperSwap的HyperSwap卷有master和aux之分,讀寫復(fù)雜度也高很多,master卷所在站點的主機讀寫是本地讀本地寫,而aux卷所在站點的主機讀寫方式是轉(zhuǎn)發(fā)模式。
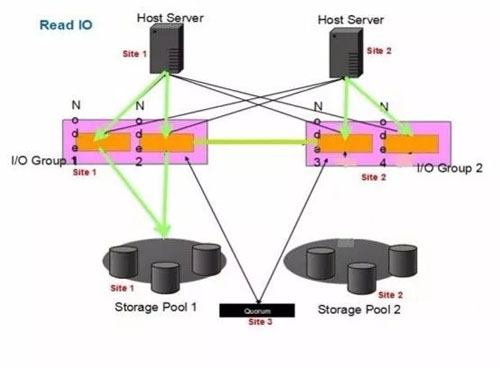
假設(shè)初始化后,Site1的卷為Master卷,Site2的卷為Aux卷
讀:
Site1讀I/O
1.主機向SVC I/O Group1的任意一個節(jié)點發(fā)送讀請求
2.SVC I/O Group1將該請求傳至Storage Pool1
3.Storage Pool1響應(yīng)請求,并將數(shù)據(jù)傳至SVC I/O Group1
4.SVC I/O Group1將數(shù)據(jù)結(jié)果傳至主機
Site2讀I/O
1.主機向SVC I/O Group2的任意一個節(jié)點發(fā)送讀請求
2.SVC I/O Group2將該請求轉(zhuǎn)發(fā)至SVC I/O Group1
3.SVC I/O Group1將請求傳至Storage Pool1
4.Storage Pool1響應(yīng)請求,并將數(shù)據(jù)傳至SVC I/O Group1
5.SVC I/O Group1將數(shù)據(jù)回傳給SVC I/O Group2
6.SVC I/O Group2將數(shù)據(jù)結(jié)果傳至主機
所以可以看到AUX卷所在站點的主機需要跨站點讀對端存儲,存在1倍的RTT,而MASTER卷所在的主機讀IO和單存儲性能相差無幾。
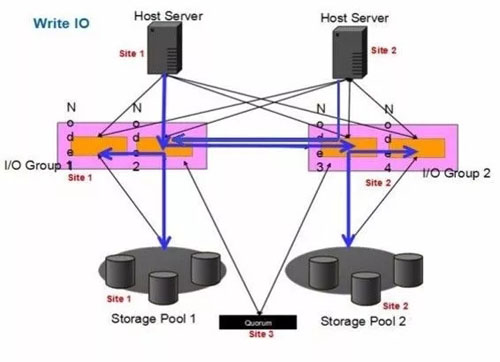
寫:
Site1寫I/O
1.主機向Site1的其中一個SVC節(jié)點2發(fā)送寫I/O請求
2.該SVC節(jié)點2將寫I/O寫入緩存
3.該SVC節(jié)點2將寫I/O同步至節(jié)點1緩存,并同時通過MM發(fā)送寫I/O至站點2的節(jié)點3和節(jié)點4
4.SVC節(jié)點1、3、4陸續(xù)回復(fù)節(jié)點2的寫響應(yīng)
5.SVC節(jié)點2回復(fù)主機寫響應(yīng)
6.兩個站點的SVC節(jié)點分別將緩存寫入各自站點的存儲當中
Site2寫I/O
1.主機向Site2的其中一個SVC節(jié)點3發(fā)送寫I/O請求
2.該SVC節(jié)點3將寫I/O轉(zhuǎn)發(fā)至Site1的任意SVC節(jié)點2
3.SVC節(jié)點2將寫I/O寫入緩存
4.該SVC節(jié)點2將寫I/O同步至節(jié)點1緩存,并同時通過MM發(fā)送寫I/O至站點2的節(jié)點3和節(jié)點4
5.SVC節(jié)點1、3、4陸續(xù)回復(fù)節(jié)點2的寫響應(yīng)
6.SVC節(jié)點2回復(fù)SVC節(jié)點3的轉(zhuǎn)發(fā)響應(yīng)
7.SVC節(jié)點3回復(fù)主機的寫響應(yīng)
8.兩個站點的SVC節(jié)點分別將緩存寫入各自站點的存儲當中
同理,AUX卷所在站點的主機需要跨站點寫對端存儲,并且回寫AUX卷底層存儲,總共存在2倍的RTT,而MASTER卷所在的主機寫IO和單存儲性能相差無幾。
所以很明顯,SVC HYPERSWAP的SVC節(jié)點是跨站點雙活,而存儲則為ACTIVE-STANDBY。
(3)NetApp MCC
MCC的雙活方式實際上是兩個數(shù)據(jù)中心的存儲互為鏡像,各自提供不同的存儲服務(wù)。
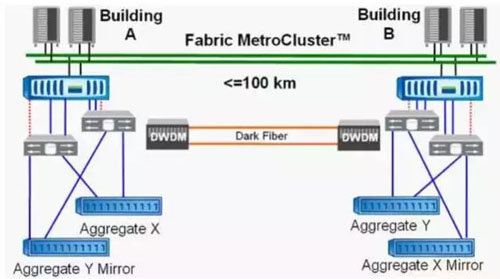
對于AGGX來說,為站點A的主機提供本地讀和本地寫,并通過集群節(jié)點的NVRAM寫日志同步至站點B,維持數(shù)據(jù)一致性,也是等到日志達到水位線,刷入底層存儲當中。
對于AGGY來說,也是類似,為站點B的主機提供本地讀和本地寫,并同步NVRAM的寫日志至站點A。MCC通過這種方式實現(xiàn)兩個站點存儲的雙活,MCC集群節(jié)點也是雙活,但對于某一應(yīng)用主機來說,實則只在一個站點活動。
性能方面,MCC的讀性能和單存儲類似,寫性能存在1倍的RTT。
(4)SVC Vplex Metro
Vplex Metro和其他三種方式都不一樣,是一種分布式的存儲雙活/多活架構(gòu)。Vplex沒有寫緩存,有了分布式緩存,標榜為access anywhere
沒有寫緩存就意味了,主機對VPLEX的寫是透寫模式,主機的寫IO只是經(jīng)過VPLEX的虛擬化直接落入到底層存儲,并在分布式緩存目錄表中記錄這個寫IO是通過哪個VPLEX引擎寫入的。當需要對該數(shù)據(jù)塊進行讀操作時,先是在分布式緩存目錄中查找數(shù)據(jù)塊是通過哪個VPLEX引擎寫入的,然后再通過本地的VPLEX引擎轉(zhuǎn)發(fā)該讀請求至上一次寫入該數(shù)據(jù)塊的VPLEX引擎,通過它來讀取它后端的存儲,最終原路返回。另外,對于寫入的IO,透穿過VPLEX寫底層存儲時,還將同步一份IO副本至另一VPLEX引擎的底層存儲。
所以可以看到,對于某數(shù)據(jù)中心VPLEX的讀操作來說,如果剛好上次該數(shù)據(jù)塊的寫操作時也是發(fā)在該VPLEX中,那么讀是本地讀,親和性好。如果剛好上次該數(shù)據(jù)塊的的寫操作不是在該VPLEX,那么就需要跨站點進行讀操作,親和性弱,存在1倍的跨站點RTT;對于寫,都是本地寫,只不過需要將該寫IO同步至另一站點的底層存儲,也存在1倍的跨站點RTT。
好了,寫了這么多,將幾種主流的存儲雙活架構(gòu)的讀寫操作流程寫清楚了。簡單對比如下:

歸根到底,我們最想要的存儲跨中心雙活,就是為了讓兩個數(shù)據(jù)中心的主機對存儲的讀寫,盡量本地讀和本地寫,或者本地讀,減少跨中心寫。這是“盡量降低對整體性能的影響”的最直接的方法!
首先是讀寫比例問題,不能將讀寫比例過小的應(yīng)用放到雙活存儲系統(tǒng)中。
再是距離對讀寫RTT的放大問題,讀寫響應(yīng)時間越敏感,距離越不能過遠。
***是想盡辦法,減少跨中心寫,這里有很多辦法,比如通過數(shù)據(jù)庫的分庫分表,將應(yīng)用分割至兩個站點,熱點數(shù)據(jù)分離;增大緩沖池,盡量減少直接的寫存儲操作等。