













Kafka 精妙的高性能設(shè)計之二
大家好,我是武哥。
這是《吃透 MQ 系列》的連載:Kafka 高性能設(shè)計的下篇。在 上一篇文章 中,指出了高性能設(shè)計的兩個關(guān)鍵維度:計算和 IO,可以將它們理解成「道」。同時給出了 Kafka 高性能設(shè)計的全景圖,可以理解成「術(shù)」。
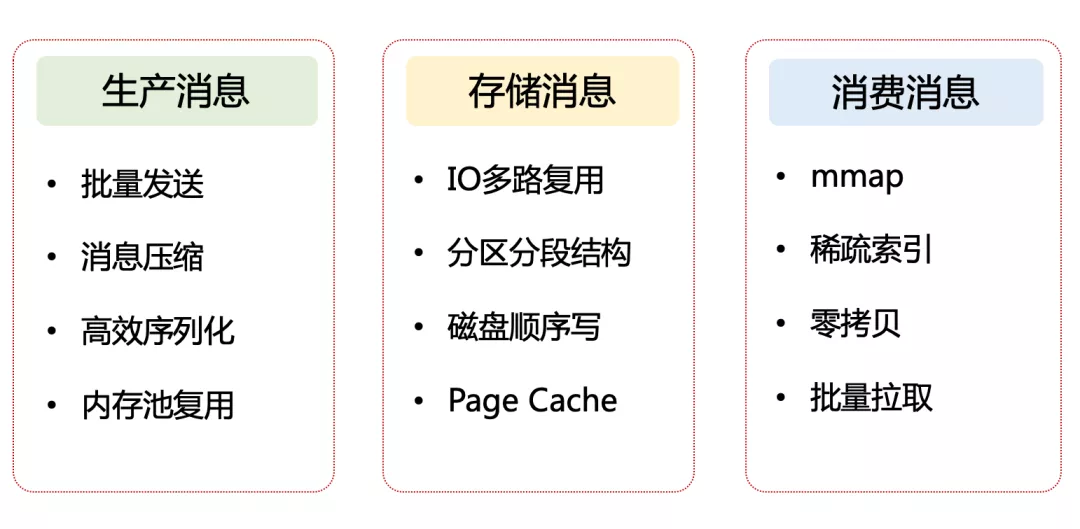
圖 1:Kafka 高性能設(shè)計的全景圖
這篇文章將繼續(xù)對存儲消息和消費消息的 8 條高性能設(shè)計手段,逐個展開分析,廢話不多說,開始發(fā)車。
一. 存儲消息的性能優(yōu)化手段
存儲消息屬于 Broker 端的核心功能,下面是它所采用的 4 條優(yōu)化手段。
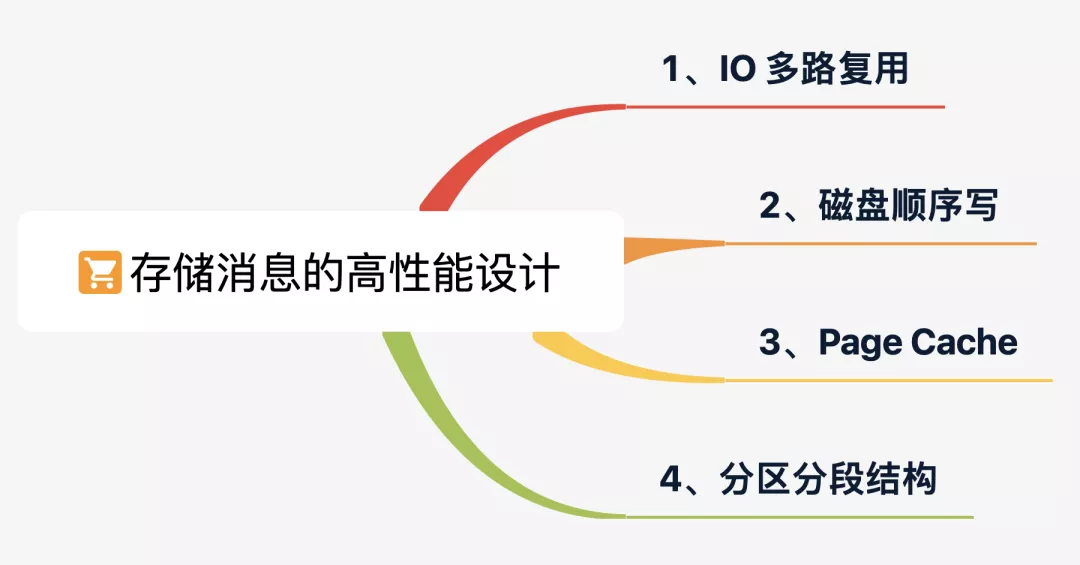
1、IO 多路復(fù)用
對于 Kafka Broker 來說,要做到高性能,首先要考慮的是:設(shè)計出一個高效的網(wǎng)絡(luò)通信模型,用來處理它和 Producer 以及 Consumer 之間的消息傳遞問題。
先引用 Kafka 2.8.0 源碼里 SocketServer 類中一段很關(guān)鍵的注釋:
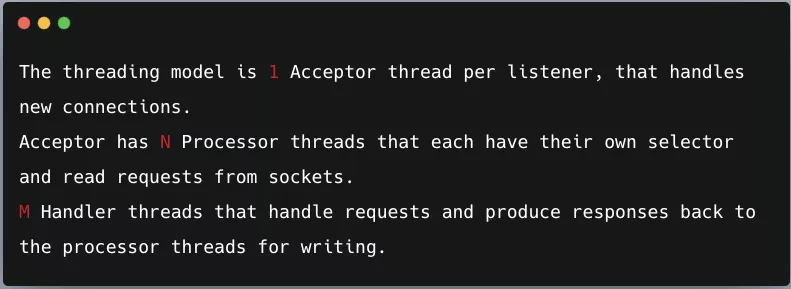
通過這段注釋,其實可以了解到 Kafka 采用的是:很典型的 Reactor 網(wǎng)絡(luò)通信模型,完整的網(wǎng)絡(luò)通信層框架圖如下所示:
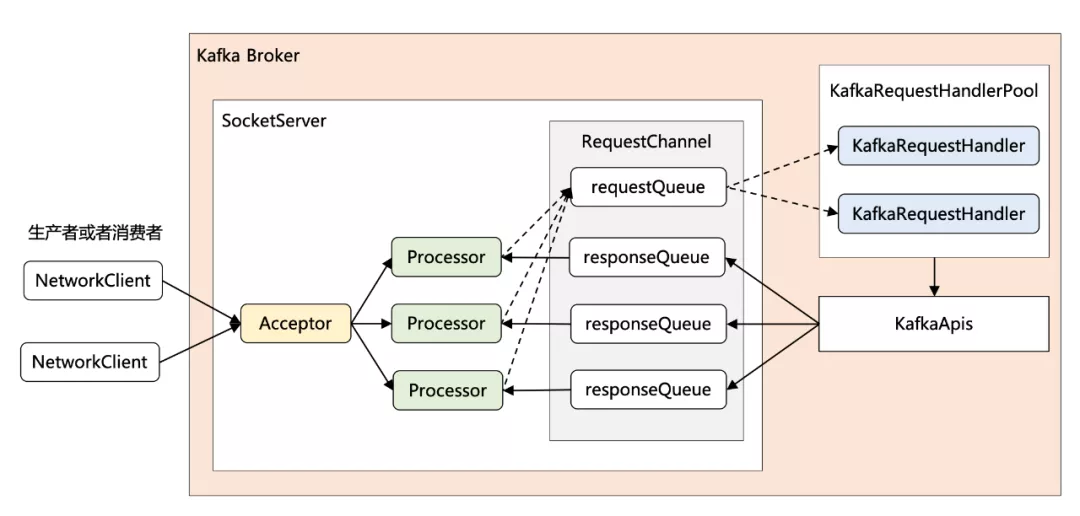
圖 2:Kafka 網(wǎng)絡(luò)通信層的框架圖
通俗點記憶就是 1 + N + M:
- 1:表示 1 個 Acceptor 線程,負(fù)責(zé)監(jiān)聽新的連接,然后將新連接交給 Processor 線程處理。
- N:表示 N 個 Processor 線程,每個 Processor 都有自己的 selector,負(fù)責(zé)從 socket 中讀寫數(shù)據(jù)。
- M:表示 M 個 KafkaRequestHandler 業(yè)務(wù)處理線程,它通過調(diào)用 KafkaApis 進(jìn)行業(yè)務(wù)處理,然后生成 response,再交由給 Processor 線程。
對于 IO 有所研究的同學(xué),應(yīng)該清楚:Reactor 模式正是采用了很經(jīng)典的 IO 多路復(fù)用技術(shù),它可以復(fù)用一個線程去處理大量的 Socket 連接,從而保證高性能。Netty 和 Redis 為什么能做到十萬甚至百萬并發(fā)?它們其實都采用了 Reactor 網(wǎng)絡(luò)通信模型。
2、磁盤順序?qū)?/h3>
通過 IO 多路復(fù)用搞定網(wǎng)絡(luò)通信后,Broker 下一步要考慮的是:如何將消息快速地存儲起來?在 Kafka 存儲選型的奧秘 一文中提到了:Kafka 選用的是「日志文件」來存儲消息,那這種寫磁盤文件的方式,又究竟是如何做到高性能的呢?這一切得益于磁盤順序?qū)懀趺蠢斫饽?Kafka 作為消息隊列,本質(zhì)上就是一個隊列,是先進(jìn)先出的,而且消息一旦生產(chǎn)了就不可變。這種有序性和不可變性使得 Kafka 完全可以「順序?qū)憽谷罩疚募簿褪钦f,僅僅將消息追加到文件末尾即可。有了順序?qū)懙那疤幔覀冊賮砜匆粋€對比實驗,從下圖中可以看到:磁盤順序?qū)懙男阅苓h(yuǎn)遠(yuǎn)高于磁盤隨機(jī)寫,甚至高于內(nèi)存隨機(jī)寫。

圖3:磁盤和內(nèi)存的 IO 速度對比
原因很簡單:對于普通的機(jī)械磁盤,如果是隨機(jī)寫入,性能確實極差,也就是隨便找到文件的某個位置來寫數(shù)據(jù)。但如果是順序?qū)懭耄驗榭纱蟠蠊?jié)省磁盤尋道和盤片旋轉(zhuǎn)的時間,因此性能提升了 3 個數(shù)量級。
3、Page Cache
磁盤順序?qū)懸呀?jīng)很快了,但是對比內(nèi)存順序?qū)懭匀宦藥讉€數(shù)量級,那有沒有可能繼續(xù)優(yōu)化呢?答案是肯定的。
這里 Kafka 用到了 Page Cache 技術(shù),簡單理解就是:利用了操作系統(tǒng)本身的緩存技術(shù),在讀寫磁盤日志文件時,其實操作的都是內(nèi)存,然后由操作系統(tǒng)決定什么時候?qū)?Page Cache 里的數(shù)據(jù)真正刷入磁盤。通過下面這個示例圖便一目了然。
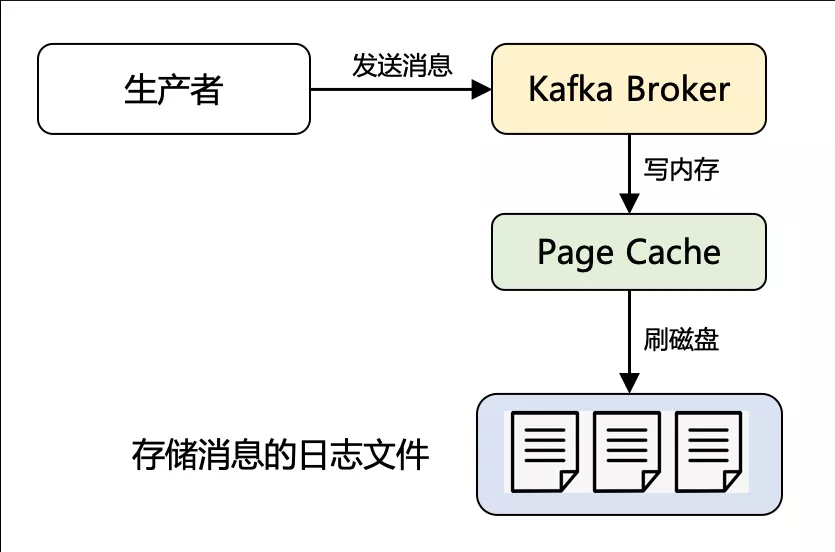
圖4:Kafka 的 Page Cache 原理
那 Page Cache 究竟什么時候會發(fā)揮最大的威力呢?這又不得不提 Page Cache 所用到的兩個經(jīng)典原理。Page Cache 緩存的是最近會被使用的磁盤數(shù)據(jù),利用的是「時間局部性」原理,依據(jù)是:最近訪問的數(shù)據(jù)很可能接下來再訪問到。而預(yù)讀到 Page Cache 中的磁盤數(shù)據(jù),又利用了「空間局部性」原理,依據(jù)是:數(shù)據(jù)往往是連續(xù)訪問的。而 Kafka 作為消息隊列,消息先是順序?qū)懭耄伊ⅠR又會被消費者讀取到,無疑非常契合上述兩條局部性原理。因此,頁緩存可以說是 Kafka 做到高吞吐的重要因素之一。
除此之外,頁緩存還有一個巨大的優(yōu)勢。用過 Java 的人都知道:如果不用頁緩存,而是用 JVM 進(jìn)程中的緩存,對象的內(nèi)存開銷非常大(通常是真實數(shù)據(jù)大小的幾倍甚至更多),此外還需要進(jìn)行垃圾回收,GC 所帶來的 Stop The World 問題也會帶來性能問題。可見,頁緩存確實優(yōu)勢明顯,而且極大地簡化了 Kafka 的代碼實現(xiàn)。
4、分區(qū)分段結(jié)構(gòu)
磁盤順序?qū)懠由享摼彺婧芎玫亟鉀Q了日志文件的高性能讀寫問題。但是如果一個 Topic 只對應(yīng)一個日志文件,顯然只能存放在一臺 Broker 機(jī)器上。當(dāng)面對海量消息時,單機(jī)的存儲容量和讀寫性能肯定有限,這樣又引出了又一個精妙的存儲設(shè)計:對數(shù)據(jù)進(jìn)行分區(qū)存儲。我在 Kafka 架構(gòu)設(shè)計的任督二脈 一文中詳細(xì)解釋了分區(qū)(Partition)的概念和作用,它是 Kafka 并發(fā)處理的最小粒度,很好地解決了存儲的擴(kuò)展性問題。隨著分區(qū)數(shù)的增加,Kafka 的吞吐量得以進(jìn)一步提升。其實在 Kafka 的存儲底層,在分區(qū)之下還有一層:那便是「分段」。簡單理解:分區(qū)對應(yīng)的其實是文件夾,分段對應(yīng)的才是真正的日志文件。
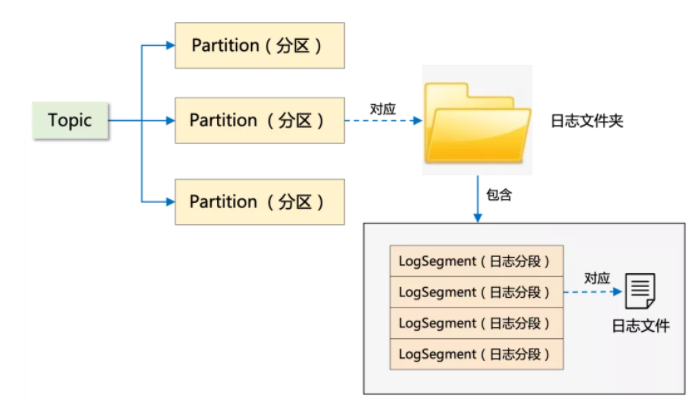
圖5:Kafka 的 分區(qū)分段存儲
每個 Partition 又被分成了多個 Segment,那為什么有了 Partition 之后,還需要 Segment 呢?
如果不引入 Segment,一個 Partition 只對應(yīng)一個文件,那這個文件會一直增大,勢必造成單個 Partition 文件過大,查找和維護(hù)不方便。此外,在做歷史消息刪除時,必然需要將文件前面的內(nèi)容刪除,只有一個文件顯然不符合 Kafka 順序?qū)懙乃悸贰6谝?Segment 后,則只需將舊的 Segment 文件刪除即可,保證了每個 Segment 的順序?qū)憽?/p>
二. 消費消息的性能優(yōu)化手段
Kafka 除了要做到百萬 TPS 的寫入性能,還要解決高性能的消息讀取問題,否則稱不上高吞吐。下面再來看看 Kafka 消費消息時所采用的 4 條優(yōu)化手段。
1、稀疏索引
如何提高讀性能,大家很容易想到的是:索引。Kafka 所面臨的查詢場景其實很簡單:能按照 offset 或者 timestamp 查到消息即可。如果采用 B Tree 類的索引結(jié)構(gòu)來實現(xiàn),每次數(shù)據(jù)寫入時都需要維護(hù)索引(屬于隨機(jī) IO 操作),而且還會引來「頁分裂」這種比較耗時的操作。而這些代價對于僅需要實現(xiàn)簡單查詢要求的 Kafka 來說,顯得非常重。所以,B Tree 類的索引并不適用于 Kafka。相反,哈希索引看起來卻非常合適。為了加快讀操作,如果只需要在內(nèi)存中維護(hù)一個「從 offset 到日志文件偏移量」的映射關(guān)系即可,每次根據(jù) offset 查找消息時,從哈希表中得到偏移量,再去讀文件即可。(根據(jù) timestamp 查消息也可以采用同樣的思路)但是哈希索引常駐內(nèi)存,顯然沒法處理數(shù)據(jù)量很大的情況,Kafka 每秒可能會有高達(dá)幾百萬的消息寫入,一定會將內(nèi)存撐爆。可我們發(fā)現(xiàn)消息的 offset 完全可以設(shè)計成有序的(實際上是一個單調(diào)遞增 long 類型的字段),這樣消息在日志文件中本身就是有序存放的了,我們便沒必要為每個消息建 hash 索引了,完全可以將消息劃分成若干個 block,只索引每個 block 第一條消息的 offset 即可,先根據(jù)大小關(guān)系找到 block,然后在 block 中順序搜索,這便是 Kafka “稀疏索引” 的設(shè)計思想。

圖6:Kafka 的稀疏索引設(shè)計
采用 “稀疏索引”,可以認(rèn)為是在磁盤空間、內(nèi)存空間、查找性能等多方面的一個折中。有了稀疏索引,當(dāng)給定一個 offset 時,Kafka 采用的是二分查找來高效定位不大于 offset 的物理位移,然后找到目標(biāo)消息。
2、mmap
利用稀疏索引,已經(jīng)基本解決了高效查詢的問題,但是這個過程中仍然有進(jìn)一步的優(yōu)化空間,那便是通過 mmap(memory mapped files) 讀寫上面提到的稀疏索引文件,進(jìn)一步提高查詢消息的速度。
- 注意:mmap 和 page cache 是兩個概念,網(wǎng)上很多資料把它們混淆在一起。此外,還有資料談到 Kafka 在讀 log 文件時也用到了 mmap,通過對 2.8.0 版本的源碼分析,這個信息也是錯誤的,其實只有索引文件的讀寫才用到了 mmap.
究竟如何理解 mmap?前面提到,常規(guī)的文件操作為了提高讀寫性能,使用了 Page Cache 機(jī)制,但是由于頁緩存處在內(nèi)核空間中,不能被用戶進(jìn)程直接尋址,所以讀文件時還需要通過系統(tǒng)調(diào)用,將頁緩存中的數(shù)據(jù)再次拷貝到用戶空間中。而采用 mmap 后,它將磁盤文件與進(jìn)程虛擬地址做了映射,并不會招致系統(tǒng)調(diào)用,以及額外的內(nèi)存 copy 開銷,從而提高了文件讀取效率。
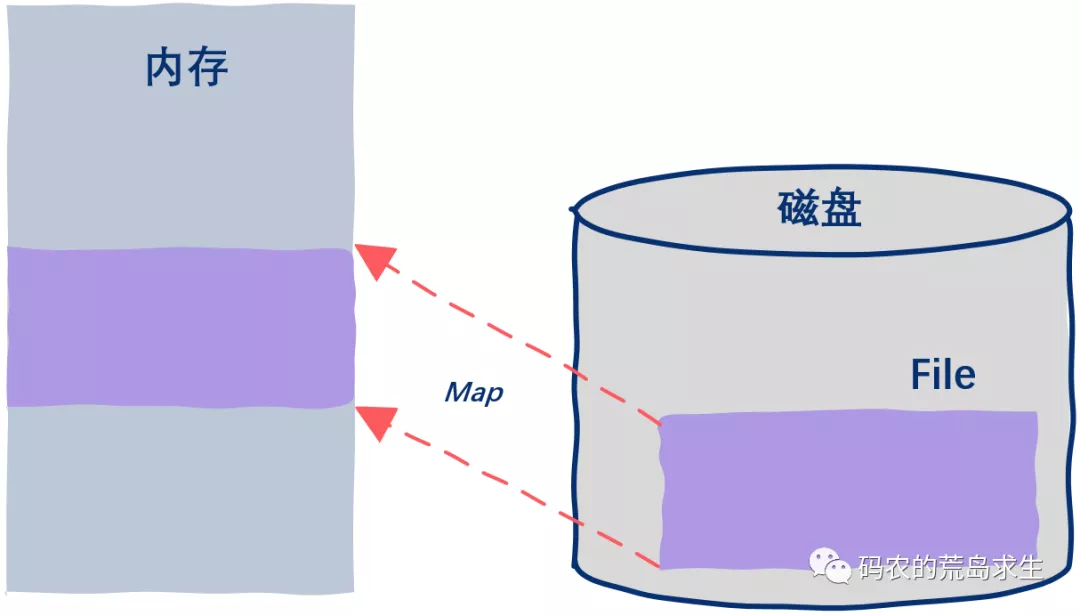
圖7:mmap 示意圖,引自《碼農(nóng)的荒島求生》
關(guān)于 mmap,好友小風(fēng)哥寫過一篇很通俗的文章: mmap 可以讓程序員解鎖哪些騷操作?大家可以參考。具體到 Kafka 的源碼層面,就是基于 JDK nio 包下的 MappedByteBuffer 的 map 函數(shù),將磁盤文件映射到內(nèi)存中。至于為什么 log 文件不采用 mmap?其實是一個特別好的問題,這個問題社區(qū)并沒有給出官方答案,網(wǎng)上的答案只能揣測作者的意圖。個人比較認(rèn)同 stackoverflow 上的這個答案:
mmap 有多少字節(jié)可以映射到內(nèi)存中與地址空間有關(guān),32 位的體系結(jié)構(gòu)只能處理 4GB 甚至更小的文件。Kafka 日志通常足夠大,可能一次只能映射部分,因此讀取它們將變得非常復(fù)雜。然而,索引文件是稀疏的,它們相對較小。將它們映射到內(nèi)存中可以加快查找過程,這是內(nèi)存映射文件提供的主要好處。
3、零拷貝
消息借助稀疏索引被查詢到后,下一步便是:將消息從磁盤文件中讀出來,然后通過網(wǎng)卡發(fā)給消費者,那這一步又可以怎么優(yōu)化呢?Kafka 用到了零拷貝(Zero-Copy)技術(shù)來提升性能。所謂的零拷貝是指數(shù)據(jù)直接從磁盤文件復(fù)制到網(wǎng)卡設(shè)備,而無需經(jīng)過應(yīng)用程序,減少了內(nèi)核和用戶模式之間的上下文切換。
下面這個過程是不采用零拷貝技術(shù)時,從磁盤中讀取文件然后通過網(wǎng)卡發(fā)送出去的流程,可以看到:經(jīng)歷了 4 次拷貝,4 次上下文切換。
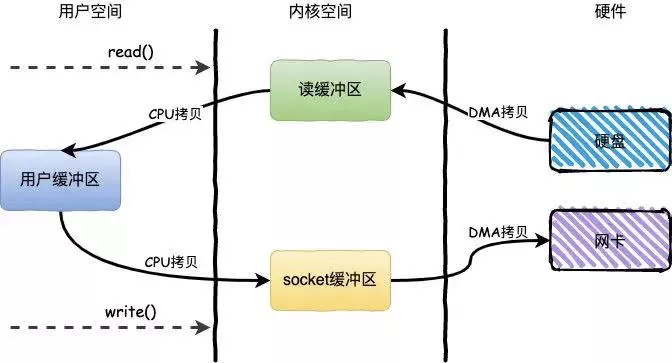
圖8:非零拷貝技術(shù)的流程圖,引自《艾小仙》
如果采用零拷貝技術(shù)(底層通過 sendfile 方法實現(xiàn)),流程將變成下面這樣。可以看到:只需 3 次拷貝以及 2 次上下文切換,顯然性能更高。
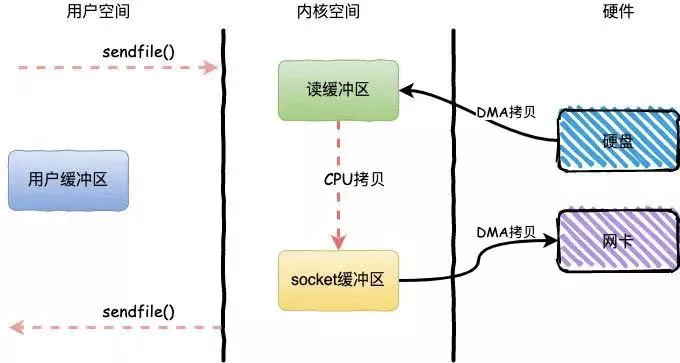
圖9:零拷貝技術(shù)的流程圖,引自《艾小仙》
4、批量拉取
和生產(chǎn)者批量發(fā)送消息類似,消息者也是批量拉取消息的,每次拉取一個消息集合,從而大大減少了網(wǎng)絡(luò)傳輸?shù)?overhead。另外,在 Kafka 精妙的高性能設(shè)計(上篇) 中介紹過,生產(chǎn)者其實在 Client 端對批量消息進(jìn)行了壓縮,這批消息持久化到 Broker 時,仍然保持的是壓縮狀態(tài),最終在 Consumer 端再做解壓縮操作。
三. 寫在最后
以上就是 Kafka 12 條高性能設(shè)計手段的詳解,這兩篇文章先從 IO 和計算兩個維度進(jìn)行宏觀上的切入,然后順著 MQ 一發(fā)一存一消費的脈絡(luò),從微觀上解構(gòu)了 Kafka 高性能的全景圖。可以說 Kafka 在高性能設(shè)計方面是教科書式的存在,它從 Prodcuer 、到 Broker、再到 Consumer,在掏空心思地優(yōu)化每一個細(xì)節(jié),最終才做到了單機(jī)每秒幾十萬 TPS 的極致性能。
最后,希望本文的分析技巧可以幫助你吃透其他高性能的中間件。我是武哥,我們下期見!




















